 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReason-to-Recommend: Using Interaction-of-Thought Reasoning to Enhance LLM Recommendation
Jun 05, 2025Driven by advances in Large Language Models (LLMs), integrating them into recommendation tasks has gained interest due to their strong semantic understanding and prompt flexibility. Prior work encoded user-item interactions or metadata into prompts for recommendations. In parallel, LLM reasoning, boosted by test-time scaling and reinforcement learning, has excelled in fields like mathematics and code, where reasoning traces and correctness signals are clear, enabling high performance and interpretability. However, directly applying these reasoning methods to recommendation is ineffective because user feedback is implicit and lacks reasoning supervision. To address this, we propose $\textbf{R2Rec}$, a reasoning-enhanced recommendation framework that samples interaction chains from the user-item graph and converts them into structured interaction-of-thoughts via a progressive masked prompting strategy, with each thought representing stepwise reasoning grounded in interaction context. This allows LLMs to simulate step-by-step decision-making based on implicit patterns. We design a two-stage training pipeline: supervised fine-tuning teaches basic reasoning from high-quality traces, and reinforcement learning refines reasoning via reward signals, alleviating sparse explicit supervision. Experiments on three real-world datasets show R2Rec outperforms classical and LLM-based baselines with an average $\textbf{10.48%}$ improvement in HitRatio@1 and $\textbf{131.81%}$ gain over the original LLM. Furthermore, the explicit reasoning chains enhance interpretability by revealing the decision process. Our code is available at: https://anonymous.4open.science/r/R2Rec-7C5D.
AgentSociety Challenge: Designing LLM Agents for User Modeling and Recommendation on Web Platforms
Feb 26, 2025The AgentSociety Challenge is the first competition in the Web Conference that aims to explore the potential of Large Language Model (LLM) agents in modeling user behavior and enhancing recommender systems on web platforms. The Challenge consists of two tracks: the User Modeling Track and the Recommendation Track. Participants are tasked to utilize a combined dataset from Yelp, Amazon, and Goodreads, along with an interactive environment simulator, to develop innovative LLM agents. The Challenge has attracted 295 teams across the globe and received over 1,400 submissions in total over the course of 37 official competition days. The participants have achieved 21.9% and 20.3% performance improvement for Track 1 and Track 2 in the Development Phase, and 9.1% and 15.9% in the Final Phase, representing a significant accomplishment. This paper discusses the detailed designs of the Challenge, analyzes the outcomes, and highlights the most successful LLM agent designs. To support further research and development, we have open-sourced the benchmark environment at https://tsinghua-fib-lab.github.io/AgentSocietyChallenge.
AgentSquare: Automatic LLM Agent Search in Modular Design Space
Oct 08, 2024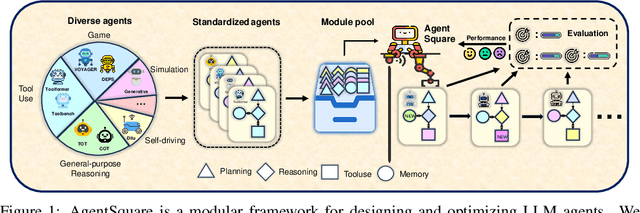
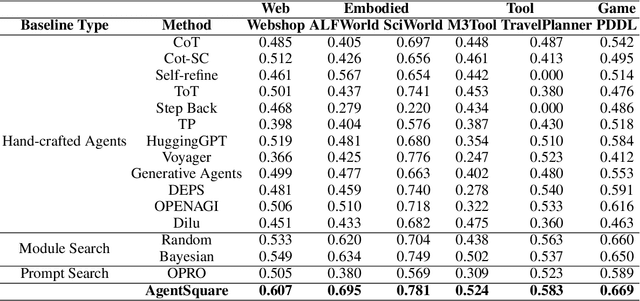
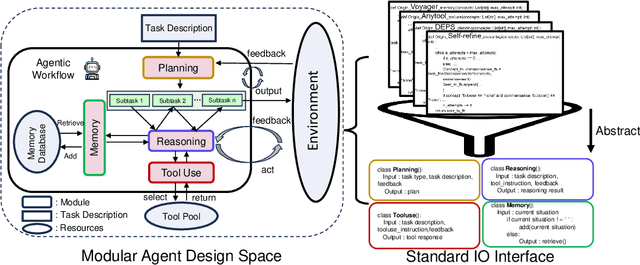

Recent advancements in Large Language Models (LLMs) have led to a rapid growth of agentic systems capable of handling a wide range of complex tasks. However, current research largely relies on manual, task-specific design, limiting their adaptability to novel tasks. In this paper, we introduce a new research problem: Modularized LLM Agent Search (MoLAS). We propose a modular design space that abstracts existing LLM agent designs into four fundamental modules with uniform IO interface: Planning, Reasoning, Tool Use, and Memory. Building on this design space, we present a novel LLM agent search framework called AgentSquare, which introduces two core mechanisms, i.e., module evolution and recombination, to efficiently search for optimized LLM agents. To further accelerate the process, we design a performance predictor that uses in-context surrogate models to skip unpromising agent designs. Extensive experiments across six benchmarks, covering the diverse scenarios of web, embodied, tool use and game applications, show that AgentSquare substantially outperforms hand-crafted agents, achieving an average performance gain of 17.2% against best-known human designs. Moreover, AgentSquare can generate interpretable design insights, enabling a deeper understanding of agentic architecture and its impact on task performance. We believe that the modular design space and AgentSquare search framework offer a platform for fully exploiting the potential of prior successful designs and consolidating the collective efforts of research community. Code repo is available at https://github.com/tsinghua-fib-lab/AgentSquare.