 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulating Generative Social Agents via Theory-Informed Workflow Design
Aug 12, 2025Recent advances in large language models have demonstrated strong reasoning and role-playing capabilities, opening new opportunities for agent-based social simulations. However, most existing agents' implementations are scenario-tailored, without a unified framework to guide the design. This lack of a general social agent limits their ability to generalize across different social contexts and to produce consistent, realistic behaviors. To address this challenge, we propose a theory-informed framework that provides a systematic design process for LLM-based social agents. Our framework is grounded in principles from Social Cognition Theory and introduces three key modules: motivation, action planning, and learning. These modules jointly enable agents to reason about their goals, plan coherent actions, and adapt their behavior over time, leading to more flexible and contextually appropriate responses. Comprehensive experiments demonstrate that our theory-driven agents reproduce realistic human behavior patterns under complex conditions, achieving up to 75% lower deviation from real-world behavioral data across multiple fidelity metrics compared to classical generative baselines. Ablation studies further show that removing motivation, planning, or learning modules increases errors by 1.5 to 3.2 times, confirming their distinct and essential contributions to generating realistic and coherent social behaviors.
The Roots of International Perceptions: Simulating US Attitude Changes Towards China with LLM Agents
Aug 12, 2025The rise of LLMs poses new possibilities in modeling opinion evolution, a long-standing task in simulation, by leveraging advanced reasoning abilities to recreate complex, large-scale human cognitive trends. While most prior works focus on opinion evolution surrounding specific isolated events or the views within a country, ours is the first to model the large-scale attitude evolution of a population representing an entire country towards another -- US citizens' perspectives towards China. To tackle the challenges of this broad scenario, we propose a framework that integrates media data collection, user profile creation, and cognitive architecture for opinion updates to successfully reproduce the real trend of US attitudes towards China over a 20-year period from 2005 to today. We also leverage LLMs' capabilities to introduce debiased media exposure, extracting neutral events from typically subjective news contents, to uncover the roots of polarized opinion formation, as well as a devils advocate agent to help explain the rare reversal from negative to positive attitudes towards China, corresponding with changes in the way Americans obtain information about the country. The simulation results, beyond validating our framework architecture, also reveal the impact of biased framing and selection bias in shaping attitudes. Overall, our work contributes to a new paradigm for LLM-based modeling of cognitive behaviors in a large-scale, long-term, cross-border social context, providing insights into the formation of international biases and offering valuable implications for media consumers to better understand the factors shaping their perspectives, and ultimately contributing to the larger social need for bias reduction and cross-cultural tolerance.
AgentRecBench: Benchmarking LLM Agent-based Personalized Recommender Systems
May 26, 2025



The emergence of agentic recommender systems powered by Large Language Models (LLMs) represents a paradigm shift in personalized recommendations, leveraging LLMs' advanced reasoning and role-playing capabilities to enable autonomous, adaptive decision-making. Unlike traditional recommendation approaches, agentic recommender systems can dynamically gather and interpret user-item interactions from complex environments, generating robust recommendation strategies that generalize across diverse scenarios. However, the field currently lacks standardized evaluation protocols to systematically assess these methods. To address this critical gap, we propose: (1) an interactive textual recommendation simulator incorporating rich user and item metadata and three typical evaluation scenarios (classic, evolving-interest, and cold-start recommendation tasks); (2) a unified modular framework for developing and studying agentic recommender systems; and (3) the first comprehensive benchmark comparing 10 classical and agentic recommendation methods. Our findings demonstrate the superiority of agentic systems and establish actionable design guidelines for their core components. The benchmark environment has been rigorously validated through an open challenge and remains publicly available with a continuously maintained leaderboard~\footnote[2]{https://tsinghua-fib-lab.github.io/AgentSocietyChallenge/pages/overview.html}, fostering ongoing community engagement and reproducible research. The benchmark is available at: \hyperlink{https://huggingface.co/datasets/SGJQovo/AgentRecBench}{https://huggingface.co/datasets/SGJQovo/AgentRecBench}.
AgentSociety Challenge: Designing LLM Agents for User Modeling and Recommendation on Web Platforms
Feb 26, 2025The AgentSociety Challenge is the first competition in the Web Conference that aims to explore the potential of Large Language Model (LLM) agents in modeling user behavior and enhancing recommender systems on web platforms. The Challenge consists of two tracks: the User Modeling Track and the Recommendation Track. Participants are tasked to utilize a combined dataset from Yelp, Amazon, and Goodreads, along with an interactive environment simulator, to develop innovative LLM agents. The Challenge has attracted 295 teams across the globe and received over 1,400 submissions in total over the course of 37 official competition days. The participants have achieved 21.9% and 20.3% performance improvement for Track 1 and Track 2 in the Development Phase, and 9.1% and 15.9% in the Final Phase, representing a significant accomplishment. This paper discusses the detailed designs of the Challenge, analyzes the outcomes, and highlights the most successful LLM agent designs. To support further research and development, we have open-sourced the benchmark environment at https://tsinghua-fib-lab.github.io/AgentSocietyChallenge.
AgentSociety: Large-Scale Simulation of LLM-Driven Generative Agents Advances Understanding of Human Behaviors and Society
Feb 12, 2025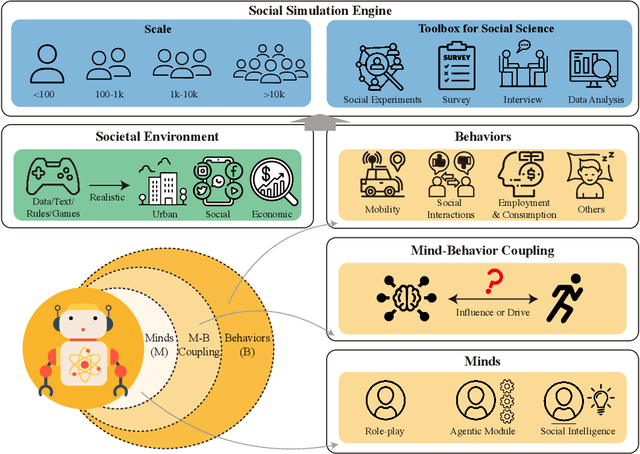
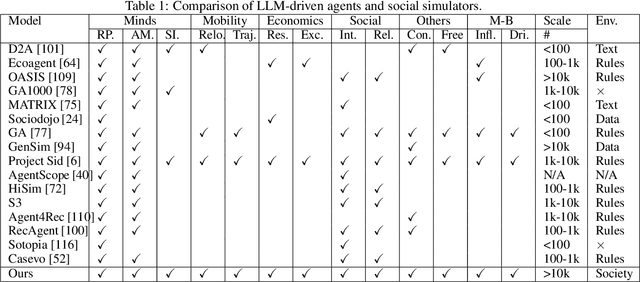
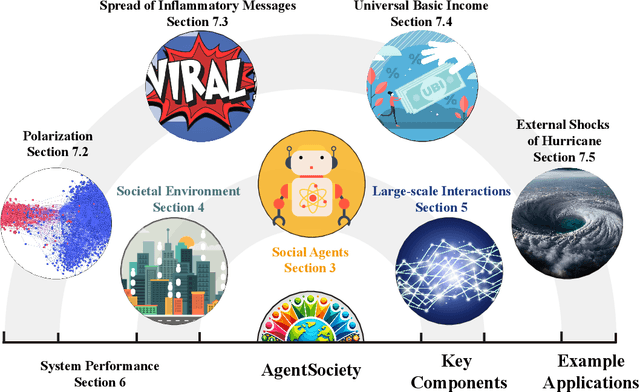

Understanding human behavior and society is a central focus in social sciences, with the rise of generative social science marking a significant paradigmatic shift. By leveraging bottom-up simulations, it replaces costly and logistically challenging traditional experiments with scalable, replicable, and systematic computational approaches for studying complex social dynamics. Recent advances in large language models (LLMs) have further transformed this research paradigm, enabling the creation of human-like generative social agents and realistic simulacra of society. In this paper, we propose AgentSociety, a large-scale social simulator that integrates LLM-driven agents, a realistic societal environment, and a powerful large-scale simulation engine. Based on the proposed simulator, we generate social lives for over 10k agents, simulating their 5 million interactions both among agents and between agents and their environment. Furthermore, we explore the potential of AgentSociety as a testbed for computational social experiments, focusing on four key social issues: polarization, the spread of inflammatory messages, the effects of universal basic income policies, and the impact of external shocks such as hurricanes. These four issues serve as valuable cases for assessing AgentSociety's support for typical research methods -- such as surveys, interviews, and interventions -- as well as for investigating the patterns, causes, and underlying mechanisms of social issues. The alignment between AgentSociety's outcomes and real-world experimental results not only demonstrates its ability to capture human behaviors and their underlying mechanisms, but also underscores its potential as an important platform for social scientists and policymakers.
Towards Large Reasoning Models: A Survey on Scaling LLM Reasoning Capabilities
Jan 17, 2025



Language has long been conceived as an essential tool for human reasoning. The breakthrough of Large Language Models (LLMs) has sparked significant research interest in leveraging these models to tackle complex reasoning tasks. Researchers have moved beyond simple autoregressive token generation by introducing the concept of "thought" -- a sequence of tokens representing intermediate steps in the reasoning process. This innovative paradigm enables LLMs' to mimic complex human reasoning processes, such as tree search and reflective thinking. Recently, an emerging trend of learning to reason has applied reinforcement learning (RL) to train LLMs to master reasoning processes. This approach enables the automatic generation of high-quality reasoning trajectories through trial-and-error search algorithms, significantly expanding LLMs' reasoning capacity by providing substantially more training data. Furthermore, recent studies demonstrate that encouraging LLMs to "think" with more tokens during test-time inference can further significantly boost reasoning accuracy. Therefore, the train-time and test-time scaling combined to show a new research frontier -- a path toward Large Reasoning Model. The introduction of OpenAI's o1 series marks a significant milestone in this research direction. In this survey, we present a comprehensive review of recent progress in LLM reasoning. We begin by introducing the foundational background of LLMs and then explore the key technical components driving the development of large reasoning models, with a focus on automated data construction, learning-to-reason techniques, and test-time scaling. We also analyze popular open-source projects at building large reasoning models, and conclude with open challenges and future research directions.
Towards Large Reasoning Models: A Survey of Reinforced Reasoning with Large Language Models
Jan 16, 2025Language has long been conceived as an essential tool for human reasoning. The breakthrough of Large Language Models (LLMs) has sparked significant research interest in leveraging these models to tackle complex reasoning tasks. Researchers have moved beyond simple autoregressive token generation by introducing the concept of "thought" -- a sequence of tokens representing intermediate steps in the reasoning process. This innovative paradigm enables LLMs' to mimic complex human reasoning processes, such as tree search and reflective thinking. Recently, an emerging trend of learning to reason has applied reinforcement learning (RL) to train LLMs to master reasoning processes. This approach enables the automatic generation of high-quality reasoning trajectories through trial-and-error search algorithms, significantly expanding LLMs' reasoning capacity by providing substantially more training data. Furthermore, recent studies demonstrate that encouraging LLMs to "think" with more tokens during test-time inference can further significantly boost reasoning accuracy. Therefore, the train-time and test-time scaling combined to show a new research frontier -- a path toward Large Reasoning Model. The introduction of OpenAI's o1 series marks a significant milestone in this research direction. In this survey, we present a comprehensive review of recent progress in LLM reasoning. We begin by introducing the foundational background of LLMs and then explore the key technical components driving the development of large reasoning models, with a focus on automated data construction, learning-to-reason techniques, and test-time scaling. We also analyze popular open-source projects at building large reasoning models, and conclude with open challenges and future research directions.