 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoveFM-R: Advancing Mobility Foundation Models via Language-driven Semantic Reasoning
Sep 26, 2025Mobility Foundation Models (MFMs) have advanced the modeling of human movement patterns, yet they face a ceiling due to limitations in data scale and semantic understanding. While Large Language Models (LLMs) offer powerful semantic reasoning, they lack the innate understanding of spatio-temporal statistics required for generating physically plausible mobility trajectories. To address these gaps, we propose MoveFM-R, a novel framework that unlocks the full potential of mobility foundation models by leveraging language-driven semantic reasoning capabilities. It tackles two key challenges: the vocabulary mismatch between continuous geographic coordinates and discrete language tokens, and the representation gap between the latent vectors of MFMs and the semantic world of LLMs. MoveFM-R is built on three core innovations: a semantically enhanced location encoding to bridge the geography-language gap, a progressive curriculum to align the LLM's reasoning with mobility patterns, and an interactive self-reflection mechanism for conditional trajectory generation. Extensive experiments demonstrate that MoveFM-R significantly outperforms existing MFM-based and LLM-based baselines. It also shows robust generalization in zero-shot settings and excels at generating realistic trajectories from natural language instructions. By synthesizing the statistical power of MFMs with the deep semantic understanding of LLMs, MoveFM-R pioneers a new paradigm that enables a more comprehensive, interpretable, and powerful modeling of human mobility. The implementation of MoveFM-R is available online at https://anonymous.4open.science/r/MoveFM-R-CDE7/.
Tuning Language Models for Robust Prediction of Diverse User Behaviors
May 23, 2025Predicting user behavior is essential for intelligent assistant services, yet deep learning models often struggle to capture long-tailed behaviors. Large language models (LLMs), with their pretraining on vast corpora containing rich behavioral knowledge, offer promise. However, existing fine-tuning approaches tend to overfit to frequent ``anchor'' behaviors, reducing their ability to predict less common ``tail'' behaviors. In this paper, we introduce BehaviorLM, a progressive fine-tuning approach that addresses this issue. In the first stage, LLMs are fine-tuned on anchor behaviors while preserving general behavioral knowledge. In the second stage, fine-tuning uses a balanced subset of all behaviors based on sample difficulty to improve tail behavior predictions without sacrificing anchor performance. Experimental results on two real-world datasets demonstrate that BehaviorLM robustly predicts both anchor and tail behaviors and effectively leverages LLM behavioral knowledge to master tail behavior prediction with few-shot examples.
BehaveGPT: A Foundation Model for Large-scale User Behavior Modeling
May 23, 2025In recent years, foundational models have revolutionized the fields of language and vision, demonstrating remarkable abilities in understanding and generating complex data; however, similar advances in user behavior modeling have been limited, largely due to the complexity of behavioral data and the challenges involved in capturing intricate temporal and contextual relationships in user activities. To address this, we propose BehaveGPT, a foundational model designed specifically for large-scale user behavior prediction. Leveraging transformer-based architecture and a novel pretraining paradigm, BehaveGPT is trained on vast user behavior datasets, allowing it to learn complex behavior patterns and support a range of downstream tasks, including next behavior prediction, long-term generation, and cross-domain adaptation. Our approach introduces the DRO-based pretraining paradigm tailored for user behavior data, which improves model generalization and transferability by equitably modeling both head and tail behaviors. Extensive experiments on real-world datasets demonstrate that BehaveGPT outperforms state-of-the-art baselines, achieving more than a 10% improvement in macro and weighted recall, showcasing its ability to effectively capture and predict user behavior. Furthermore, we measure the scaling law in the user behavior domain for the first time on the Honor dataset, providing insights into how model performance scales with increased data and parameter sizes.
Towards Large Reasoning Models: A Survey on Scaling LLM Reasoning Capabilities
Jan 17, 2025



Language has long been conceived as an essential tool for human reasoning. The breakthrough of Large Language Models (LLMs) has sparked significant research interest in leveraging these models to tackle complex reasoning tasks. Researchers have moved beyond simple autoregressive token generation by introducing the concept of "thought" -- a sequence of tokens representing intermediate steps in the reasoning process. This innovative paradigm enables LLMs' to mimic complex human reasoning processes, such as tree search and reflective thinking. Recently, an emerging trend of learning to reason has applied reinforcement learning (RL) to train LLMs to master reasoning processes. This approach enables the automatic generation of high-quality reasoning trajectories through trial-and-error search algorithms, significantly expanding LLMs' reasoning capacity by providing substantially more training data. Furthermore, recent studies demonstrate that encouraging LLMs to "think" with more tokens during test-time inference can further significantly boost reasoning accuracy. Therefore, the train-time and test-time scaling combined to show a new research frontier -- a path toward Large Reasoning Model. The introduction of OpenAI's o1 series marks a significant milestone in this research direction. In this survey, we present a comprehensive review of recent progress in LLM reasoning. We begin by introducing the foundational background of LLMs and then explore the key technical components driving the development of large reasoning models, with a focus on automated data construction, learning-to-reason techniques, and test-time scaling. We also analyze popular open-source projects at building large reasoning models, and conclude with open challenges and future research directions.
Towards Large Reasoning Models: A Survey of Reinforced Reasoning with Large Language Models
Jan 16, 2025Language has long been conceived as an essential tool for human reasoning. The breakthrough of Large Language Models (LLMs) has sparked significant research interest in leveraging these models to tackle complex reasoning tasks. Researchers have moved beyond simple autoregressive token generation by introducing the concept of "thought" -- a sequence of tokens representing intermediate steps in the reasoning process. This innovative paradigm enables LLMs' to mimic complex human reasoning processes, such as tree search and reflective thinking. Recently, an emerging trend of learning to reason has applied reinforcement learning (RL) to train LLMs to master reasoning processes. This approach enables the automatic generation of high-quality reasoning trajectories through trial-and-error search algorithms, significantly expanding LLMs' reasoning capacity by providing substantially more training data. Furthermore, recent studies demonstrate that encouraging LLMs to "think" with more tokens during test-time inference can further significantly boost reasoning accuracy. Therefore, the train-time and test-time scaling combined to show a new research frontier -- a path toward Large Reasoning Model. The introduction of OpenAI's o1 series marks a significant milestone in this research direction. In this survey, we present a comprehensive review of recent progress in LLM reasoning. We begin by introducing the foundational background of LLMs and then explore the key technical components driving the development of large reasoning models, with a focus on automated data construction, learning-to-reason techniques, and test-time scaling. We also analyze popular open-source projects at building large reasoning models, and conclude with open challenges and future research directions.
A Population-to-individual Tuning Framework for Adapting Pretrained LM to On-device User Intent Prediction
Aug 19, 2024
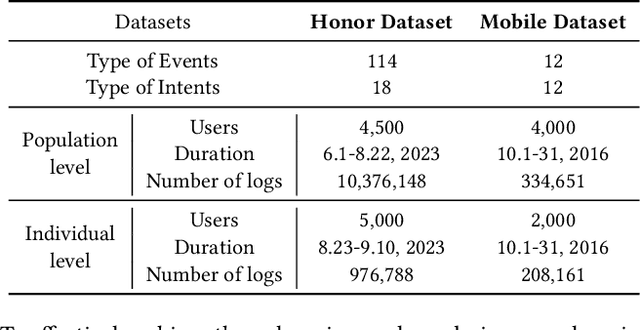


Mobile devices, especially smartphones, can support rich functions and have developed into indispensable tools in daily life. With the rise of generative AI services, smartphones can potentially transform into personalized assistants, anticipating user needs and scheduling services accordingly. Predicting user intents on smartphones, and reflecting anticipated activities based on past interactions and context, remains a pivotal step towards this vision. Existing research predominantly focuses on specific domains, neglecting the challenge of modeling diverse event sequences across dynamic contexts. Leveraging pre-trained language models (PLMs) offers a promising avenue, yet adapting PLMs to on-device user intent prediction presents significant challenges. To address these challenges, we propose PITuning, a Population-to-Individual Tuning framework. PITuning enhances common pattern extraction through dynamic event-to-intent transition modeling and addresses long-tailed preferences via adaptive unlearning strategies. Experimental results on real-world datasets demonstrate PITuning's superior intent prediction performance, highlighting its ability to capture long-tailed preferences and its practicality for on-device prediction scenarios.