 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnow What You Know: Metacognitive Entropy Calibration for Verifiable RL Reasoning
Feb 26, 2026Large reasoning models (LRMs) have emerged as a powerful paradigm for solving complex real-world tasks. In practice, these models are predominantly trained via Reinforcement Learning with Verifiable Rewards (RLVR), yet most existing outcome-only RLVR pipelines rely almost exclusively on a binary correctness signal and largely ignore the model's intrinsic uncertainty. We term this discrepancy the uncertainty-reward mismatch, under which high- and low-uncertainty solutions are treated equivalently, preventing the policy from "Know What You Know" and impeding the shift from optimizing for correct answers to optimizing effective reasoning paths. This limitation is especially critical in reasoning-centric tasks such as mathematics and question answering, where performance hinges on the quality of the model's internal reasoning process rather than mere memorization of final answers. To address this, we propose EGPO, a metacognitive entropy calibration framework that explicitly integrates intrinsic uncertainty into RLVR for enhancing LRMs. EGPO estimates per-sample uncertainty using a zero-overhead entropy proxy derived from token-level likelihoods and aligns it with extrinsic correctness through an asymmetric calibration mechanism that preserves correct reasoning while selectively regulating overconfident failures, thereby enabling stable and uncertainty-aware policy optimization. Moreover, EGPO recovers informative learning signals from otherwise degenerate group-based rollouts without modifying the verifier or reward definition. Extensive experiments across multiple benchmarks demonstrate that the proposed EGPO leads to substantial and consistent improvements in reasoning performance, establishing a principled path for advancing LRMs through metacognitive entropy calibration.
MagicAgent: Towards Generalized Agent Planning
Feb 22, 2026The evolution of Large Language Models (LLMs) from passive text processors to autonomous agents has established planning as a core component of modern intelligence. However, achieving generalized planning remains elusive, not only by the scarcity of high-quality interaction data but also by inherent conflicts across heterogeneous planning tasks. These challenges result in models that excel at isolated tasks yet struggle to generalize, while existing multi-task training attempts suffer from gradient interference. In this paper, we present \textbf{MagicAgent}, a series of foundation models specifically designed for generalized agent planning. We introduce a lightweight and scalable synthetic data framework that generates high-quality trajectories across diverse planning tasks, including hierarchical task decomposition, tool-augmented planning, multi-constraint scheduling, procedural logic orchestration, and long-horizon tool execution. To mitigate training conflicts, we propose a two-stage training paradigm comprising supervised fine-tuning followed by multi-objective reinforcement learning over both static datasets and dynamic environments. Empirical results demonstrate that MagicAgent-32B and MagicAgent-30B-A3B deliver superior performance, achieving accuracies of $75.1\%$ on Worfbench, $55.9\%$ on NaturalPlan, $57.5\%$ on $τ^2$-Bench, $86.9\%$ on BFCL-v3, and $81.2\%$ on ACEBench, as well as strong results on our in-house MagicEval benchmarks. These results substantially outperform existing sub-100B models and even surpass leading closed-source models.
DFPO: Scaling Value Modeling via Distributional Flow towards Robust and Generalizable LLM Post-Training
Feb 05, 2026Training reinforcement learning (RL) systems in real-world environments remains challenging due to noisy supervision and poor out-of-domain (OOD) generalization, especially in LLM post-training. Recent distributional RL methods improve robustness by modeling values with multiple quantile points, but they still learn each quantile independently as a scalar. This results in rough-grained value representations that lack fine-grained conditioning on state information, struggling under complex and OOD conditions. We propose DFPO (Distributional Value Flow Policy Optimization with Conditional Risk and Consistency Control), a robust distributional RL framework that models values as continuous flows across time steps. By scaling value modeling through learning of a value flow field instead of isolated quantile predictions, DFPO captures richer state information for more accurate advantage estimation. To stabilize training under noisy feedback, DFPO further integrates conditional risk control and consistency constraints along value flow trajectories. Experiments on dialogue, math reasoning, and scientific tasks show that DFPO outperforms PPO, FlowRL, and other robust baselines under noisy supervision, achieving improved training stability and generalization.
From Scores to Preferences: Redefining MOS Benchmarking for Speech Quality Reward Modeling
Oct 01, 2025Assessing the perceptual quality of synthetic speech is crucial for guiding the development and refinement of speech generation models. However, it has traditionally relied on human subjective ratings such as the Mean Opinion Score (MOS), which depend on manual annotations and often suffer from inconsistent rating standards and poor reproducibility. To address these limitations, we introduce MOS-RMBench, a unified benchmark that reformulates diverse MOS datasets into a preference-comparison setting, enabling rigorous evaluation across different datasets. Building on MOS-RMBench, we systematically construct and evaluate three paradigms for reward modeling: scalar reward models, semi-scalar reward models, and generative reward models (GRMs). Our experiments reveal three key findings: (1) scalar models achieve the strongest overall performance, consistently exceeding 74% accuracy; (2) most models perform considerably worse on synthetic speech than on human speech; and (3) all models struggle on pairs with very small MOS differences. To improve performance on these challenging pairs, we propose a MOS-aware GRM that incorporates an MOS-difference-based reward function, enabling the model to adaptively scale rewards according to the difficulty of each sample pair. Experimental results show that the MOS-aware GRM significantly improves fine-grained quality discrimination and narrows the gap with scalar models on the most challenging cases. We hope this work will establish both a benchmark and a methodological framework to foster more rigorous and scalable research in automatic speech quality assessment.
Speech-Language Models with Decoupled Tokenizers and Multi-Token Prediction
Jun 14, 2025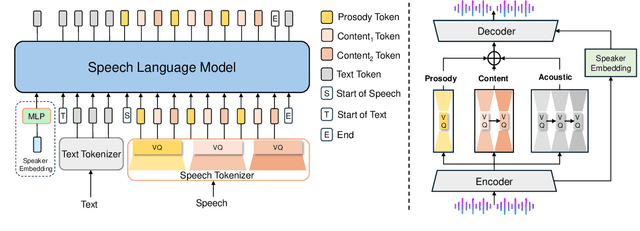
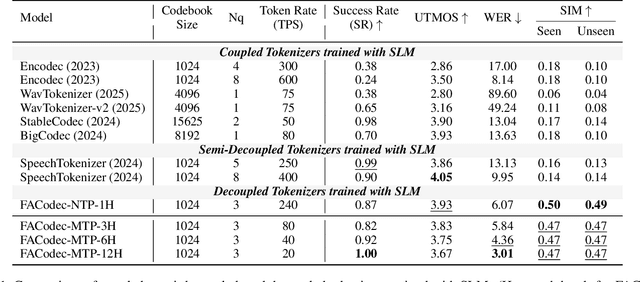
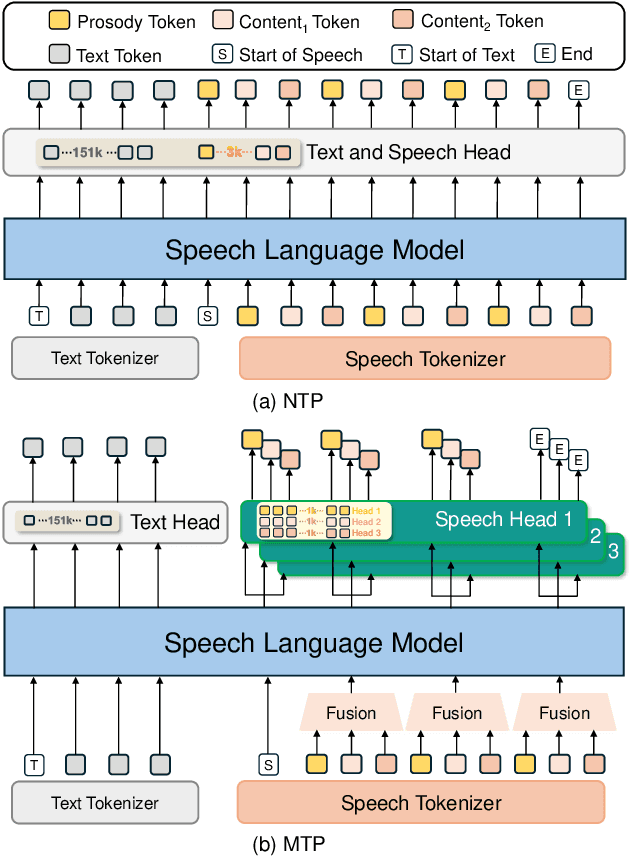
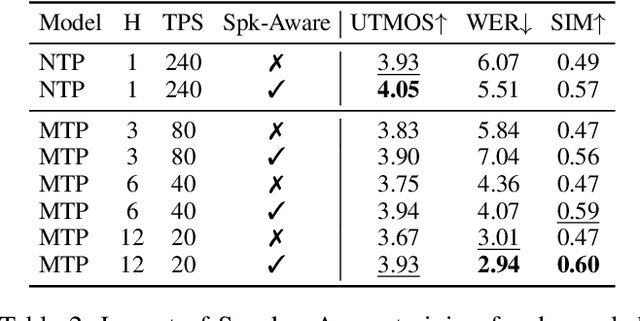
Speech-language models (SLMs) offer a promising path toward unifying speech and text understanding and generation. However, challenges remain in achieving effective cross-modal alignment and high-quality speech generation. In this work, we systematically investigate the impact of key components (i.e., speech tokenizers, speech heads, and speaker modeling) on the performance of LLM-centric SLMs. We compare coupled, semi-decoupled, and fully decoupled speech tokenizers under a fair SLM framework and find that decoupled tokenization significantly improves alignment and synthesis quality. To address the information density mismatch between speech and text, we introduce multi-token prediction (MTP) into SLMs, enabling each hidden state to decode multiple speech tokens. This leads to up to 12$\times$ faster decoding and a substantial drop in word error rate (from 6.07 to 3.01). Furthermore, we propose a speaker-aware generation paradigm and introduce RoleTriviaQA, a large-scale role-playing knowledge QA benchmark with diverse speaker identities. Experiments demonstrate that our methods enhance both knowledge understanding and speaker consistency.
A Survey of Large Language Model-Powered Spatial Intelligence Across Scales: Advances in Embodied Agents, Smart Cities, and Earth Science
Apr 14, 2025Over the past year, the development of large language models (LLMs) has brought spatial intelligence into focus, with much attention on vision-based embodied intelligence. However, spatial intelligence spans a broader range of disciplines and scales, from navigation and urban planning to remote sensing and earth science. What are the differences and connections between spatial intelligence across these fields? In this paper, we first review human spatial cognition and its implications for spatial intelligence in LLMs. We then examine spatial memory, knowledge representations, and abstract reasoning in LLMs, highlighting their roles and connections. Finally, we analyze spatial intelligence across scales -- from embodied to urban and global levels -- following a framework that progresses from spatial memory and understanding to spatial reasoning and intelligence. Through this survey, we aim to provide insights into interdisciplinary spatial intelligence research and inspire future studies.
Boosting Diffusion-Based Text Image Super-Resolution Model Towards Generalized Real-World Scenarios
Mar 11, 2025Restoring low-resolution text images presents a significant challenge, as it requires maintaining both the fidelity and stylistic realism of the text in restored images. Existing text image restoration methods often fall short in hard situations, as the traditional super-resolution models cannot guarantee clarity, while diffusion-based methods fail to maintain fidelity. In this paper, we introduce a novel framework aimed at improving the generalization ability of diffusion models for text image super-resolution (SR), especially promoting fidelity. First, we propose a progressive data sampling strategy that incorporates diverse image types at different stages of training, stabilizing the convergence and improving the generalization. For the network architecture, we leverage a pre-trained SR prior to provide robust spatial reasoning capabilities, enhancing the model's ability to preserve textual information. Additionally, we employ a cross-attention mechanism to better integrate textual priors. To further reduce errors in textual priors, we utilize confidence scores to dynamically adjust the importance of textual features during training. Extensive experiments on real-world datasets demonstrate that our approach not only produces text images with more realistic visual appearances but also improves the accuracy of text structure.
EPR-GAIL: An EPR-Enhanced Hierarchical Imitation Learning Framework to Simulate Complex User Consumption Behaviors
Mar 09, 2025

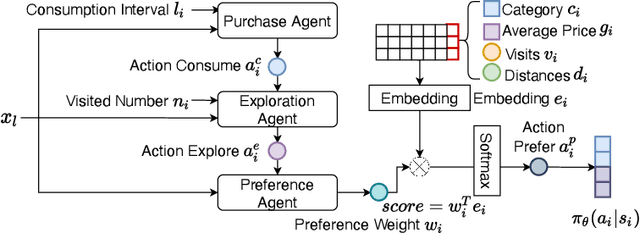

User consumption behavior data, which records individuals' online spending history at various types of stores, has been widely used in various applications, such as store recommendation, site selection, and sale forecasting. However, its high worth is limited due to deficiencies in data comprehensiveness and changes of application scenarios. Thus, generating high-quality sequential consumption data by simulating complex user consumption behaviors is of great importance to real-world applications. Two branches of existing sequence generation methods are both limited in quality. Model-based methods with simplified assumptions fail to model the complex decision process of user consumption, while data-driven methods that emulate real-world data are prone to noises, unobserved behaviors, and dynamic decision space. In this work, we propose to enhance the fidelity and trustworthiness of the data-driven Generative Adversarial Imitation Learning (GAIL) method by blending it with the Exploration and Preferential Return EPR model . The core idea of our EPR-GAIL framework is to model user consumption behaviors as a complex EPR decision process, which consists of purchase, exploration, and preference decisions. Specifically, we design the hierarchical policy function in the generator as a realization of the EPR decision process and employ the probability distributions of the EPR model to guide the reward function in the discriminator. Extensive experiments on two real-world datasets of user consumption behaviors on an online platform demonstrate that the EPR-GAIL framework outperforms the best state-of-the-art baseline by over 19\% in terms of data fidelity. Furthermore, the generated consumption behavior data can improve the performance of sale prediction and location recommendation by up to 35.29% and 11.19%, respectively, validating its advantage for practical applications.
Causal Discovery and Inference towards Urban Elements and Associated Factors
Mar 09, 2025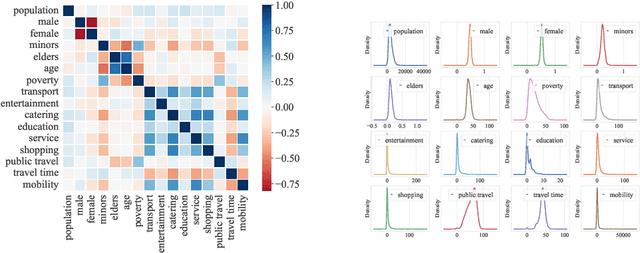
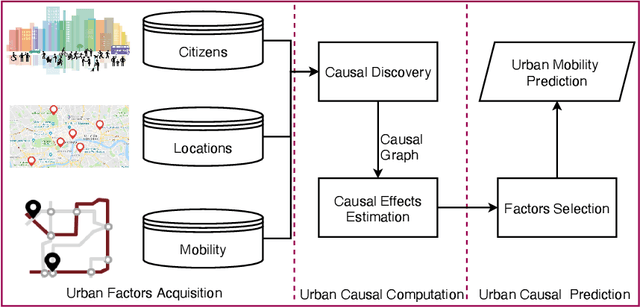
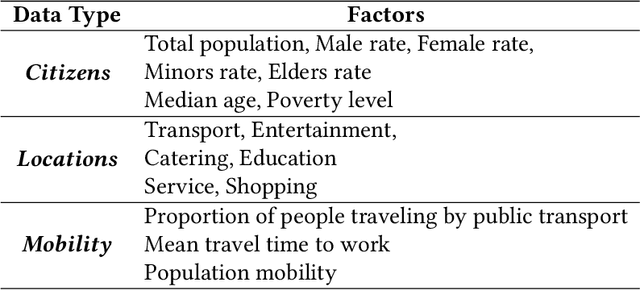
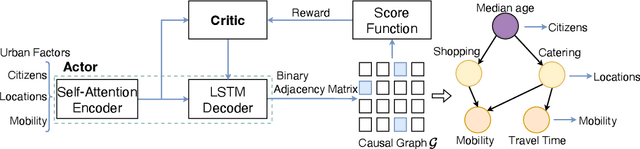
To uncover the city's fundamental functioning mechanisms, it is important to acquire a deep understanding of complicated relationships among citizens, location, and mobility behaviors. Previous research studies have applied direct correlation analysis to investigate such relationships. Nevertheless, due to the ubiquitous confounding effects, empirical correlation analysis may not accurately reflect underlying causal relationships among basic urban elements. In this paper, we propose a novel urban causal computing framework to comprehensively explore causalities and confounding effects among a variety of factors across different types of urban elements. In particular, we design a reinforcement learning algorithm to discover the potential causal graph, which depicts the causal relations between urban factors. The causal graph further serves as the guidance for estimating causal effects between pair-wise urban factors by propensity score matching. After removing the confounding effects from correlations, we leverage significance levels of causal effects in downstream urban mobility prediction tasks. Experimental studies on open-source urban datasets show that the discovered causal graph demonstrates a hierarchical structure, where citizens affect locations, and they both cause changes in urban mobility behaviors. Experimental results in urban mobility prediction tasks further show that the proposed method can effectively reduce confounding effects and enhance performance of urban computing tasks.
Causality Enhanced Origin-Destination Flow Prediction in Data-Scarce Cities
Mar 09, 2025Accurate origin-destination (OD) flow prediction is of great importance to developing cities, as it can contribute to optimize urban structures and layouts. However, with the common issues of missing regional features and lacking OD flow data, it is quite daunting to predict OD flow in developing cities. To address this challenge, we propose a novel Causality-Enhanced OD Flow Prediction (CE-OFP), a unified framework that aims to transfer urban knowledge between cities and achieve accuracy improvements in OD flow predictions across data-scarce cities. In specific, we propose a novel reinforcement learning model to discover universal causalities among urban features in data-rich cities and build corresponding causal graphs. Then, we further build Causality-Enhanced Variational Auto-Encoder (CE-VAE) to incorporate causal graphs for effective feature reconstruction in data-scarce cities. Finally, with the reconstructed features, we devise a knowledge distillation method with a graph attention network to migrate the OD prediction model from data-rich cities to data-scare cities. Extensive experiments on two pairs of real-world datasets validate that the proposed CE-OFP remarkably outperforms state-of-the-art baselines, which can reduce the RMSE of OD flow prediction for data-scarce cities by up to 11%.