 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Large Reasoning Models: A Survey on Scaling LLM Reasoning Capabilities
Jan 17, 2025



Language has long been conceived as an essential tool for human reasoning. The breakthrough of Large Language Models (LLMs) has sparked significant research interest in leveraging these models to tackle complex reasoning tasks. Researchers have moved beyond simple autoregressive token generation by introducing the concept of "thought" -- a sequence of tokens representing intermediate steps in the reasoning process. This innovative paradigm enables LLMs' to mimic complex human reasoning processes, such as tree search and reflective thinking. Recently, an emerging trend of learning to reason has applied reinforcement learning (RL) to train LLMs to master reasoning processes. This approach enables the automatic generation of high-quality reasoning trajectories through trial-and-error search algorithms, significantly expanding LLMs' reasoning capacity by providing substantially more training data. Furthermore, recent studies demonstrate that encouraging LLMs to "think" with more tokens during test-time inference can further significantly boost reasoning accuracy. Therefore, the train-time and test-time scaling combined to show a new research frontier -- a path toward Large Reasoning Model. The introduction of OpenAI's o1 series marks a significant milestone in this research direction. In this survey, we present a comprehensive review of recent progress in LLM reasoning. We begin by introducing the foundational background of LLMs and then explore the key technical components driving the development of large reasoning models, with a focus on automated data construction, learning-to-reason techniques, and test-time scaling. We also analyze popular open-source projects at building large reasoning models, and conclude with open challenges and future research directions.
Towards Large Reasoning Models: A Survey of Reinforced Reasoning with Large Language Models
Jan 16, 2025Language has long been conceived as an essential tool for human reasoning. The breakthrough of Large Language Models (LLMs) has sparked significant research interest in leveraging these models to tackle complex reasoning tasks. Researchers have moved beyond simple autoregressive token generation by introducing the concept of "thought" -- a sequence of tokens representing intermediate steps in the reasoning process. This innovative paradigm enables LLMs' to mimic complex human reasoning processes, such as tree search and reflective thinking. Recently, an emerging trend of learning to reason has applied reinforcement learning (RL) to train LLMs to master reasoning processes. This approach enables the automatic generation of high-quality reasoning trajectories through trial-and-error search algorithms, significantly expanding LLMs' reasoning capacity by providing substantially more training data. Furthermore, recent studies demonstrate that encouraging LLMs to "think" with more tokens during test-time inference can further significantly boost reasoning accuracy. Therefore, the train-time and test-time scaling combined to show a new research frontier -- a path toward Large Reasoning Model. The introduction of OpenAI's o1 series marks a significant milestone in this research direction. In this survey, we present a comprehensive review of recent progress in LLM reasoning. We begin by introducing the foundational background of LLMs and then explore the key technical components driving the development of large reasoning models, with a focus on automated data construction, learning-to-reason techniques, and test-time scaling. We also analyze popular open-source projects at building large reasoning models, and conclude with open challenges and future research directions.
LCSim: A Large-Scale Controllable Traffic Simulator
Jun 28, 2024
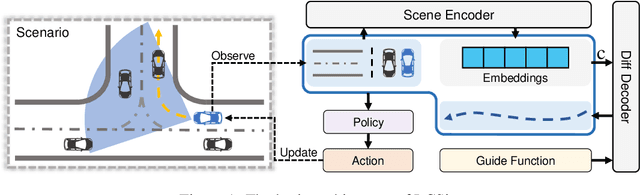


With the rapid development of urban transportation and the continuous advancement in autonomous vehicles, the demand for safely and efficiently testing autonomous driving and traffic optimization algorithms arises, which needs accurate modeling of large-scale urban traffic scenarios. Existing traffic simulation systems encounter two significant limitations. Firstly, they often rely on open-source datasets or manually crafted maps, constraining the scale of simulations. Secondly, vehicle models within these systems tend to be either oversimplified or lack controllability, compromising the authenticity and diversity of the simulations. In this paper, we propose LCSim, a large-scale controllable traffic simulator. LCSim provides map tools for constructing unified high-definition map (HD map) descriptions from open-source datasets including Waymo and Argoverse or publicly available data sources like OpenStreetMap to scale up the simulation scenarios. Also, we integrate diffusion-based traffic simulation into the simulator for realistic and controllable microscopic traffic flow modeling. By leveraging these features, LCSim provides realistic and diverse virtual traffic environments. Code and Demos are available at https://github.com/tsinghua-fib-lab/LCSim.
CityBench: Evaluating the Capabilities of Large Language Model as World Model
Jun 20, 2024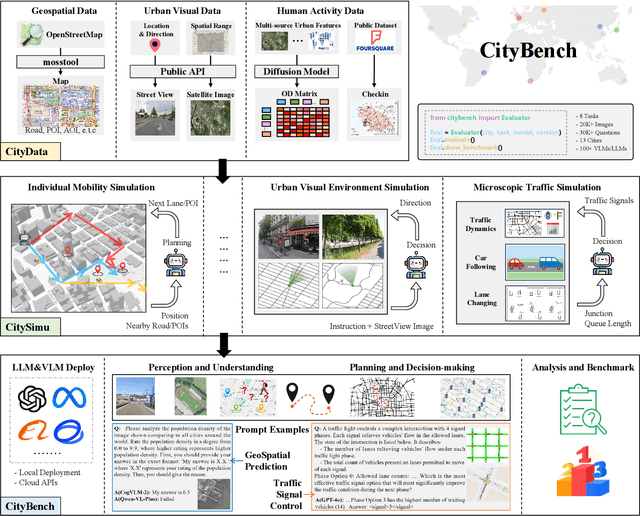
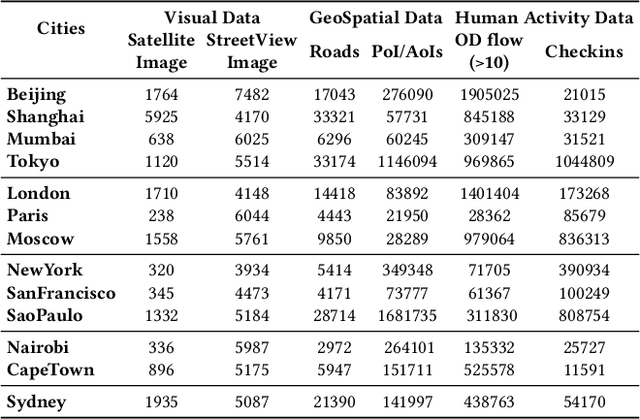
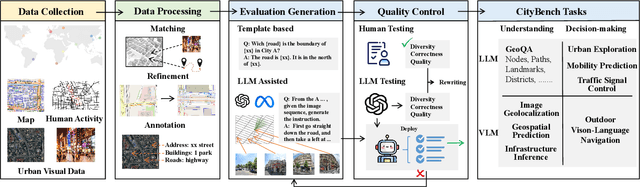
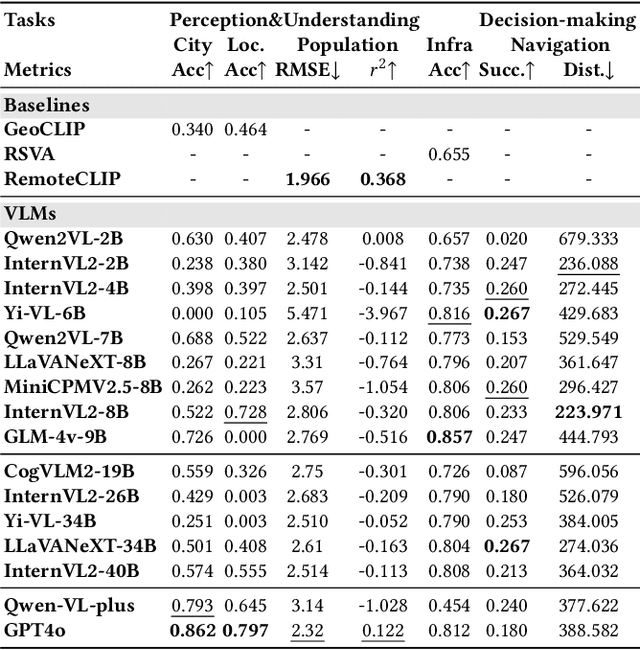
Large language models (LLMs) with powerful generalization ability has been widely used in many domains. A systematic and reliable evaluation of LLMs is a crucial step in their development and applications, especially for specific professional fields. In the urban domain, there have been some early explorations about the usability of LLMs, but a systematic and scalable evaluation benchmark is still lacking. The challenge in constructing a systematic evaluation benchmark for the urban domain lies in the diversity of data and scenarios, as well as the complex and dynamic nature of cities. In this paper, we propose CityBench, an interactive simulator based evaluation platform, as the first systematic evaluation benchmark for the capability of LLMs for urban domain. First, we build CitySim to integrate the multi-source data and simulate fine-grained urban dynamics. Based on CitySim, we design 7 tasks in 2 categories of perception-understanding and decision-making group to evaluate the capability of LLMs as city-scale world model for urban domain. Due to the flexibility and ease-of-use of CitySim, our evaluation platform CityBench can be easily extended to any city in the world. We evaluate 13 well-known LLMs including open source LLMs and commercial LLMs in 13 cities around the world. Extensive experiments demonstrate the scalability and effectiveness of proposed CityBench and shed lights for the future development of LLMs in urban domain. The dataset, benchmark and source codes are openly accessible to the research community via https://github.com/tsinghua-fib-lab/CityBench