 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeU-MASK: User-adaptive Spatio-Temporal Masking for Personalized Mobile AI Applications
Jan 11, 2026Personalized mobile artificial intelligence applications are widely deployed, yet they are expected to infer user behavior from sparse and irregular histories under a continuously evolving spatio-temporal context. This setting induces a fundamental tension among three requirements, i.e., immediacy to adapt to recent behavior, stability to resist transient noise, and generalization to support long-horizon prediction and cold-start users. Most existing approaches satisfy at most two of these requirements, resulting in an inherent impossibility triangle in data-scarce, non-stationary personalization. To address this challenge, we model mobile behavior as a partially observed spatio-temporal tensor and unify short-term adaptation, long-horizon forecasting, and cold-start recommendation as a conditional completion problem, where a user- and task-specific mask specifies which coordinates are treated as evidence. We propose U-MASK, a user-adaptive spatio-temporal masking method that allocates evidence budgets based on user reliability and task sensitivity. To enable mask generation under sparse observations, U-MASK learns a compact, task-agnostic user representation from app and location histories via U-SCOPE, which serves as the sole semantic conditioning signal. A shared diffusion transformer then performs mask-guided generative completion while preserving observed evidence, so personalization and task differentiation are governed entirely by the mask and the user representation. Experiments on real-world mobile datasets demonstrate consistent improvements over state-of-the-art methods across short-term prediction, long-horizon forecasting, and cold-start settings, with the largest gains under severe data sparsity. The code and dataset will be available at https://github.com/NICE-HKU/U-MASK.
TrafficSimAgent: A Hierarchical Agent Framework for Autonomous Traffic Simulation with MCP Control
Dec 24, 2025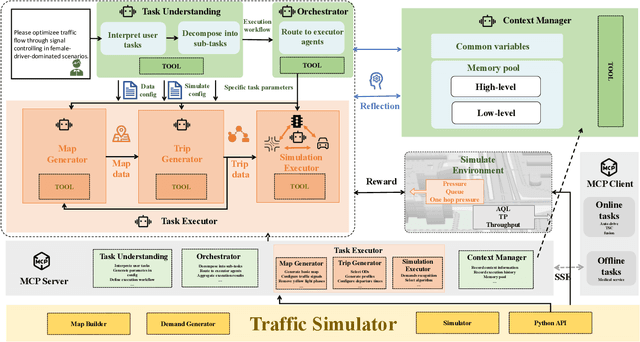

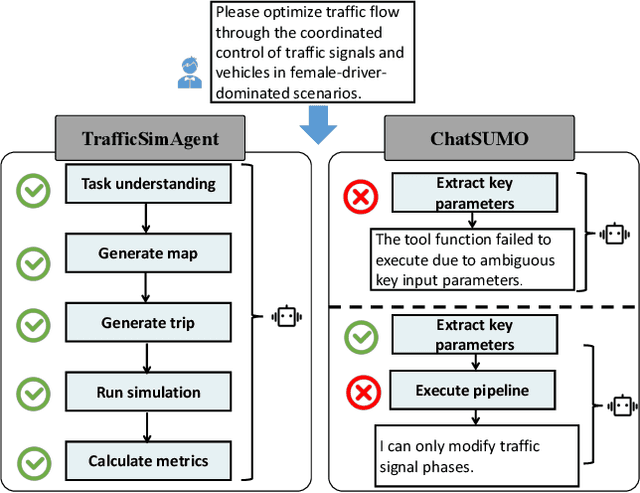
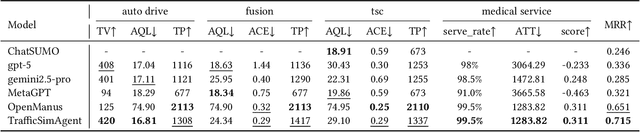
Traffic simulation is important for transportation optimization and policy making. While existing simulators such as SUMO and MATSim offer fully-featured platforms and utilities, users without too much knowledge about these platforms often face significant challenges when conducting experiments from scratch and applying them to their daily work. To solve this challenge, we propose TrafficSimAgent, an LLM-based agent framework that serves as an expert in experiment design and decision optimization for general-purpose traffic simulation tasks. The framework facilitates execution through cross-level collaboration among expert agents: high-level expert agents comprehend natural language instructions with high flexibility, plan the overall experiment workflow, and invoke corresponding MCP-compatible tools on demand; meanwhile, low-level expert agents select optimal action plans for fundamental elements based on real-time traffic conditions. Extensive experiments across multiple scenarios show that TrafficSimAgent effectively executes simulations under various conditions and consistently produces reasonable outcomes even when user instructions are ambiguous. Besides, the carefully designed expert-level autonomous decision-driven optimization in TrafficSimAgent yields superior performance when compared with other systems and SOTA LLM based methods.
CAMS: A CityGPT-Powered Agentic Framework for Urban Human Mobility Simulation
Jun 16, 2025Human mobility simulation plays a crucial role in various real-world applications. Recently, to address the limitations of traditional data-driven approaches, researchers have explored leveraging the commonsense knowledge and reasoning capabilities of large language models (LLMs) to accelerate human mobility simulation. However, these methods suffer from several critical shortcomings, including inadequate modeling of urban spaces and poor integration with both individual mobility patterns and collective mobility distributions. To address these challenges, we propose \textbf{C}ityGPT-Powered \textbf{A}gentic framework for \textbf{M}obility \textbf{S}imulation (\textbf{CAMS}), an agentic framework that leverages the language based urban foundation model to simulate human mobility in urban space. \textbf{CAMS} comprises three core modules, including MobExtractor to extract template mobility patterns and synthesize new ones based on user profiles, GeoGenerator to generate anchor points considering collective knowledge and generate candidate urban geospatial knowledge using an enhanced version of CityGPT, TrajEnhancer to retrieve spatial knowledge based on mobility patterns and generate trajectories with real trajectory preference alignment via DPO. Experiments on real-world datasets show that \textbf{CAMS} achieves superior performance without relying on externally provided geospatial information. Moreover, by holistically modeling both individual mobility patterns and collective mobility constraints, \textbf{CAMS} generates more realistic and plausible trajectories. In general, \textbf{CAMS} establishes a new paradigm that integrates the agentic framework with urban-knowledgeable LLMs for human mobility simulation.
Hawkes based Representation Learning for Reasoning over Scale-free Community-structured Temporal Knowledge Graphs
Dec 28, 2024Temporal knowledge graph (TKG) reasoning has become a hot topic due to its great value in many practical tasks. The key to TKG reasoning is modeling the structural information and evolutional patterns of the TKGs. While great efforts have been devoted to TKG reasoning, the structural and evolutional characteristics of real-world networks have not been considered. In the aspect of structure, real-world networks usually exhibit clear community structure and scale-free (long-tailed distribution) properties. In the aspect of evolution, the impact of an event decays with the time elapsing. In this paper, we propose a novel TKG reasoning model called Hawkes process-based Evolutional Representation Learning Network (HERLN), which learns structural information and evolutional patterns of a TKG simultaneously, considering the characteristics of real-world networks: community structure, scale-free and temporal decaying. First, we find communities in the input TKG to make the encoding get more similar intra-community embeddings. Second, we design a Hawkes process-based relational graph convolutional network to cope with the event impact-decaying phenomenon. Third, we design a conditional decoding method to alleviate biases towards frequent entities caused by long-tailed distribution. Experimental results show that HERLN achieves significant improvements over the state-of-the-art models.
TrajAgent: An Agent Framework for Unified Trajectory Modelling
Oct 27, 2024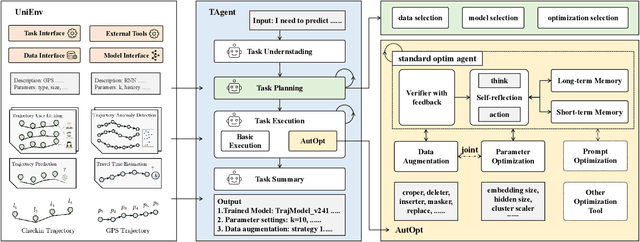

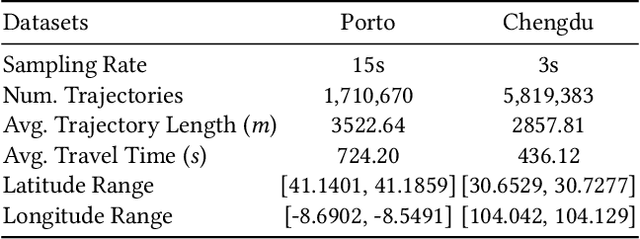

Trajectory modeling, which includes research on trajectory data pattern mining and future prediction, has widespread applications in areas such as life services, urban transportation, and public administration. Numerous methods have been proposed to address specific problems within trajectory modelling. However, due to the heterogeneity of data and the diversity of trajectory tasks, achieving unified trajectory modelling remains an important yet challenging task. In this paper, we propose TrajAgent, a large language model-based agentic framework, to unify various trajectory modelling tasks. In TrajAgent, we first develop UniEnv, an execution environment with a unified data and model interface, to support the execution and training of various models. Building on UniEnv, we introduce TAgent, an agentic workflow designed for automatic trajectory modelling across various trajectory tasks. Specifically, we design AutOpt, a systematic optimization module within TAgent, to further improve the performance of the integrated model. With diverse trajectory tasks input in natural language, TrajAgent automatically generates competitive results via training and executing appropriate models. Extensive experiments on four tasks using four real-world datasets demonstrate the effectiveness of TrajAgent in unified trajectory modelling, achieving an average performance improvement of 15.43% over baseline methods.
AgentMove: Predicting Human Mobility Anywhere Using Large Language Model based Agentic Framework
Aug 26, 2024
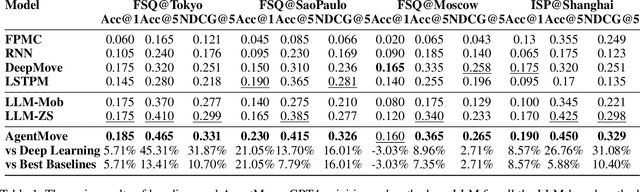
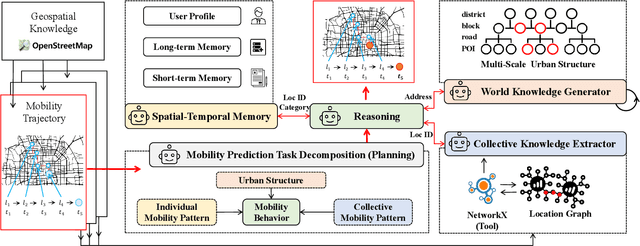

Human mobility prediction plays a crucial role in various real-world applications. Although deep learning based models have shown promising results over the past decade, their reliance on extensive private mobility data for training and their inability to perform zero-shot predictions, have hindered further advancements. Recently, attempts have been made to apply large language models (LLMs) to mobility prediction task. However, their performance has been constrained by the absence of a systematic design of workflow. They directly generate the final output using LLMs, which limits the potential of LLMs to uncover complex mobility patterns and underestimates their extensive reserve of global geospatial knowledge. In this paper, we introduce AgentMove, a systematic agentic prediction framework to achieve generalized mobility prediction for any cities worldwide. In AgentMove, we first decompose the mobility prediction task into three sub-tasks and then design corresponding modules to complete these subtasks, including spatial-temporal memory for individual mobility pattern mining, world knowledge generator for modeling the effects of urban structure and collective knowledge extractor for capturing the shared patterns among population. Finally, we combine the results of three modules and conduct a reasoning step to generate the final predictions. Extensive experiments on mobility data from two sources in 12 cities demonstrate that AgentMove outperforms the best baseline more than 8% in various metrics and it shows robust predictions with various LLMs as base and also less geographical bias across cities. Codes and data can be found in https://github.com/tsinghua-fib-lab/AgentMove.
CityGPT: Empowering Urban Spatial Cognition of Large Language Models
Jun 20, 2024



Large language models(LLMs) with powerful language generation and reasoning capabilities have already achieved success in many domains, e.g., math and code generation. However, due to the lacking of physical world's corpus and knowledge during training, they usually fail to solve many real-life tasks in the urban space. In this paper, we propose CityGPT, a systematic framework for enhancing the capability of LLMs on understanding urban space and solving the related urban tasks by building a city-scale world model in the model. First, we construct a diverse instruction tuning dataset CityInstruction for injecting urban knowledge and enhancing spatial reasoning capability effectively. By using a mixture of CityInstruction and general instruction data, we fine-tune various LLMs (e.g., ChatGLM3-6B, Qwen1.5 and LLama3 series) to enhance their capability without sacrificing general abilities. To further validate the effectiveness of proposed methods, we construct a comprehensive benchmark CityEval to evaluate the capability of LLMs on diverse urban scenarios and problems. Extensive evaluation results demonstrate that small LLMs trained with CityInstruction can achieve competitive performance with commercial LLMs in the comprehensive evaluation of CityEval. The source codes are openly accessible to the research community via https://github.com/tsinghua-fib-lab/CityGPT.
CityBench: Evaluating the Capabilities of Large Language Model as World Model
Jun 20, 2024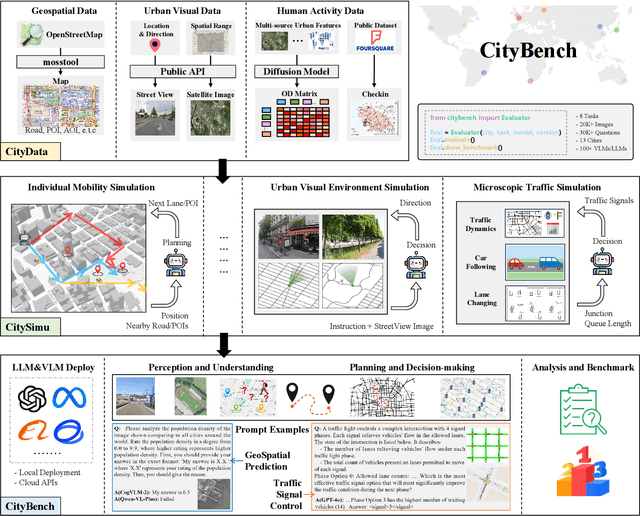
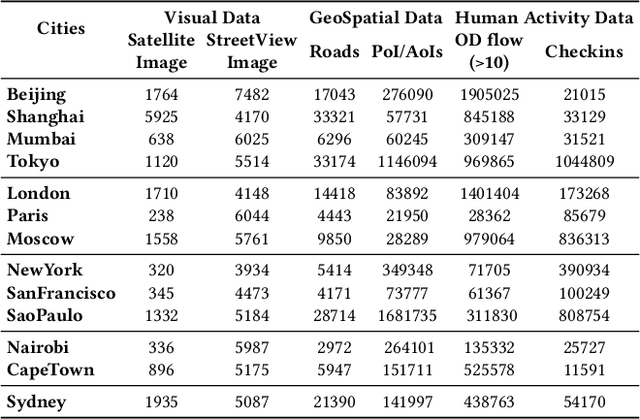
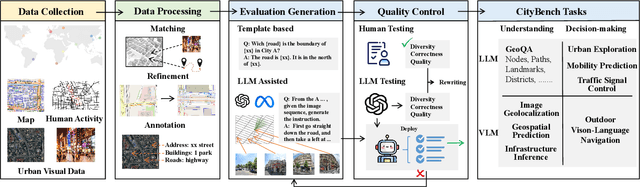
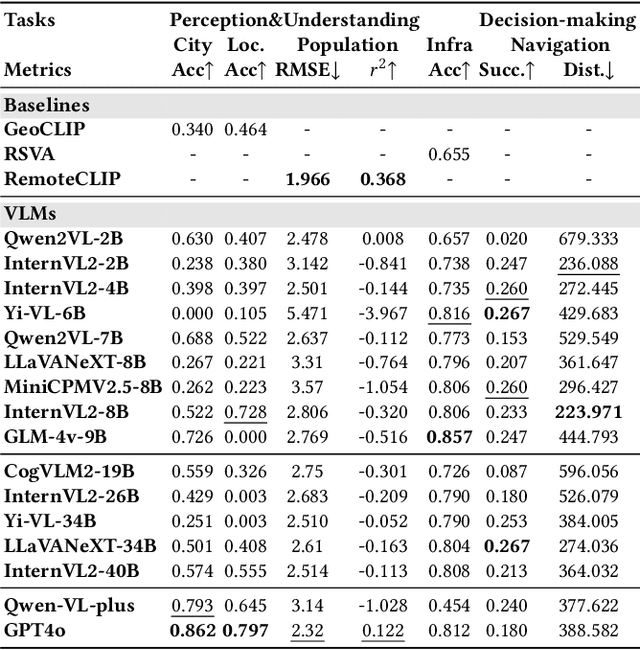
Large language models (LLMs) with powerful generalization ability has been widely used in many domains. A systematic and reliable evaluation of LLMs is a crucial step in their development and applications, especially for specific professional fields. In the urban domain, there have been some early explorations about the usability of LLMs, but a systematic and scalable evaluation benchmark is still lacking. The challenge in constructing a systematic evaluation benchmark for the urban domain lies in the diversity of data and scenarios, as well as the complex and dynamic nature of cities. In this paper, we propose CityBench, an interactive simulator based evaluation platform, as the first systematic evaluation benchmark for the capability of LLMs for urban domain. First, we build CitySim to integrate the multi-source data and simulate fine-grained urban dynamics. Based on CitySim, we design 7 tasks in 2 categories of perception-understanding and decision-making group to evaluate the capability of LLMs as city-scale world model for urban domain. Due to the flexibility and ease-of-use of CitySim, our evaluation platform CityBench can be easily extended to any city in the world. We evaluate 13 well-known LLMs including open source LLMs and commercial LLMs in 13 cities around the world. Extensive experiments demonstrate the scalability and effectiveness of proposed CityBench and shed lights for the future development of LLMs in urban domain. The dataset, benchmark and source codes are openly accessible to the research community via https://github.com/tsinghua-fib-lab/CityBench