 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatialAct: Probing Spatial Reasoning-to-Action Capabilities of VLM Agents in 3D Scenes
May 29, 2026Humans can effortlessly perceive spatial layouts, form cognitive representations, reason about spatial relations, and translate such reasoning into actions in everyday 3D environments. Although recent vision-language models (VLMs) have shown promising performance on observation-conditioned spatial perception and reasoning tasks, it remains unclear whether they can build coherent spatial understanding, act upon it, and refine their actions through multi-turn feedback. To study this problem, we introduce \textbf{SpatialAct}, a simulator-grounded benchmark for probing \textit{action-conditioned spatial reasoning} in 3D scenes. Starting from the most challenging setting, Multi-turn Interactive Refinement, we further design its decomposed counterpart, Single-step Error Detection and Fix, together with five fundamental spatial ability tasks to diagnose the underlying causes of model failures. Experiments reveal a clear reasoning-to-action gap: current VLMs can perform well on isolated spatial reasoning tasks, but struggle to maintain coherent spatial beliefs and produce reliable actions during multi-turn feedback, substantially underperforming humans. These results suggest that current VLM agents still lack robust spatial state tracking under action-induced environment changes, even when low-level control is abstracted away.
Do Neural Networks Lose Plasticity in a Gradually Changing World?
Feb 09, 2026Continual learning has become a trending topic in machine learning. Recent studies have discovered an interesting phenomenon called loss of plasticity, referring to neural networks gradually losing the ability to learn new tasks. However, existing plasticity research largely relies on contrived settings with abrupt task transitions, which often do not reflect real-world environments. In this paper, we propose to investigate a gradually changing environment, and we simulate this by input/output interpolation and task sampling. We perform theoretical and empirical analysis, showing that the loss of plasticity is an artifact of abrupt tasks changes in the environment and can be largely mitigated if the world changes gradually.
CityRiSE: Reasoning Urban Socio-Economic Status in Vision-Language Models via Reinforcement Learning
Oct 25, 2025Harnessing publicly available, large-scale web data, such as street view and satellite imagery, urban socio-economic sensing is of paramount importance for achieving global sustainable development goals. With the emergence of Large Vision-Language Models (LVLMs), new opportunities have arisen to solve this task by treating it as a multi-modal perception and understanding problem. However, recent studies reveal that LVLMs still struggle with accurate and interpretable socio-economic predictions from visual data. To address these limitations and maximize the potential of LVLMs, we introduce \textbf{CityRiSE}, a novel framework for \textbf{R}eason\textbf{i}ng urban \textbf{S}ocio-\textbf{E}conomic status in LVLMs through pure reinforcement learning (RL). With carefully curated multi-modal data and verifiable reward design, our approach guides the LVLM to focus on semantically meaningful visual cues, enabling structured and goal-oriented reasoning for generalist socio-economic status prediction. Experiments demonstrate that CityRiSE with emergent reasoning process significantly outperforms existing baselines, improving both prediction accuracy and generalization across diverse urban contexts, particularly for prediction on unseen cities and unseen indicators. This work highlights the promise of combining RL and LVLMs for interpretable and generalist urban socio-economic sensing.
CityBench: Evaluating the Capabilities of Large Language Model as World Model
Jun 20, 2024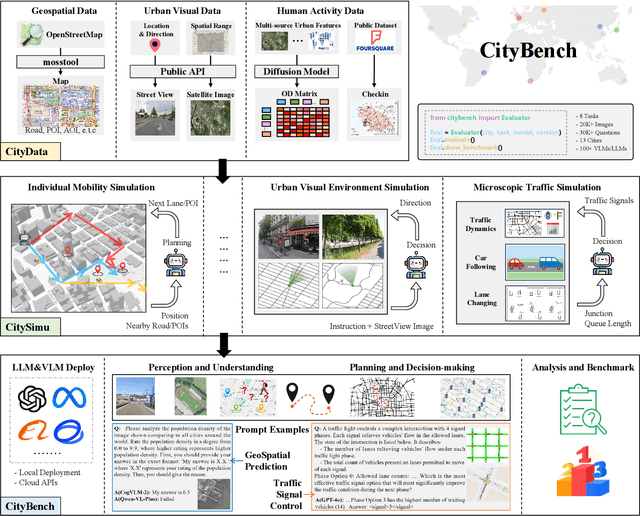
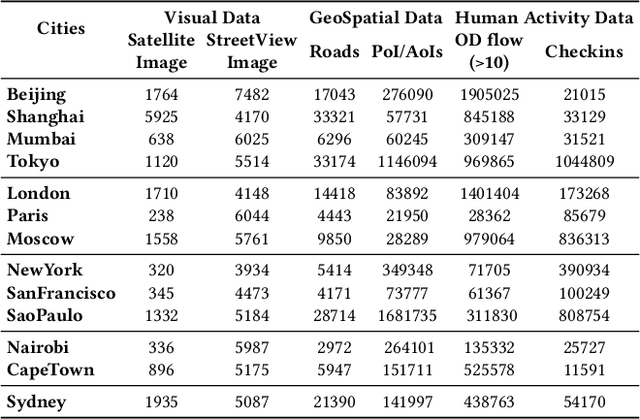
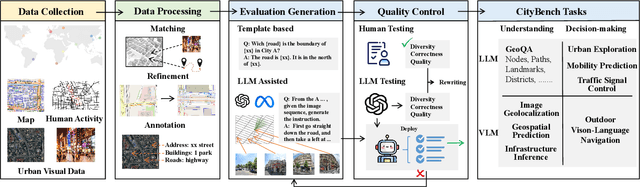
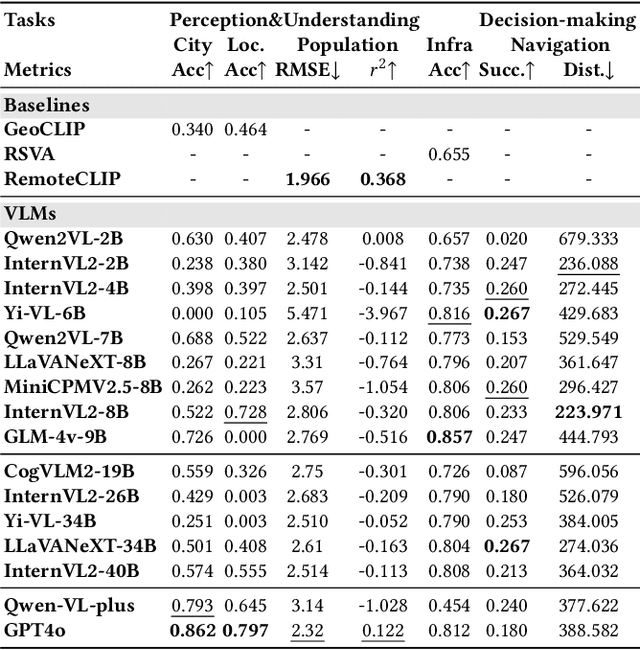
Large language models (LLMs) with powerful generalization ability has been widely used in many domains. A systematic and reliable evaluation of LLMs is a crucial step in their development and applications, especially for specific professional fields. In the urban domain, there have been some early explorations about the usability of LLMs, but a systematic and scalable evaluation benchmark is still lacking. The challenge in constructing a systematic evaluation benchmark for the urban domain lies in the diversity of data and scenarios, as well as the complex and dynamic nature of cities. In this paper, we propose CityBench, an interactive simulator based evaluation platform, as the first systematic evaluation benchmark for the capability of LLMs for urban domain. First, we build CitySim to integrate the multi-source data and simulate fine-grained urban dynamics. Based on CitySim, we design 7 tasks in 2 categories of perception-understanding and decision-making group to evaluate the capability of LLMs as city-scale world model for urban domain. Due to the flexibility and ease-of-use of CitySim, our evaluation platform CityBench can be easily extended to any city in the world. We evaluate 13 well-known LLMs including open source LLMs and commercial LLMs in 13 cities around the world. Extensive experiments demonstrate the scalability and effectiveness of proposed CityBench and shed lights for the future development of LLMs in urban domain. The dataset, benchmark and source codes are openly accessible to the research community via https://github.com/tsinghua-fib-lab/CityBench
CityGPT: Empowering Urban Spatial Cognition of Large Language Models
Jun 20, 2024



Large language models(LLMs) with powerful language generation and reasoning capabilities have already achieved success in many domains, e.g., math and code generation. However, due to the lacking of physical world's corpus and knowledge during training, they usually fail to solve many real-life tasks in the urban space. In this paper, we propose CityGPT, a systematic framework for enhancing the capability of LLMs on understanding urban space and solving the related urban tasks by building a city-scale world model in the model. First, we construct a diverse instruction tuning dataset CityInstruction for injecting urban knowledge and enhancing spatial reasoning capability effectively. By using a mixture of CityInstruction and general instruction data, we fine-tune various LLMs (e.g., ChatGLM3-6B, Qwen1.5 and LLama3 series) to enhance their capability without sacrificing general abilities. To further validate the effectiveness of proposed methods, we construct a comprehensive benchmark CityEval to evaluate the capability of LLMs on diverse urban scenarios and problems. Extensive evaluation results demonstrate that small LLMs trained with CityInstruction can achieve competitive performance with commercial LLMs in the comprehensive evaluation of CityEval. The source codes are openly accessible to the research community via https://github.com/tsinghua-fib-lab/CityGPT.