 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscriminative Finetuning of Generative Large Language Models without Reward Models and Preference Data
Feb 25, 2025Supervised fine-tuning (SFT) followed by preference optimization (PO) denoted by SFT$\rightarrow$PO has become the standard for improving pretrained large language models (LLMs), with PO demonstrating significant performance gains. However, PO methods rely on either human-labeled preference data or a strong reward model to generate preference data. Can we fine-tune LLMs without preference data or reward models while achieving competitive performance to SFT$\rightarrow$PO? We address this question by introducing Discriminative Fine-Tuning (DFT), a novel approach that eliminates the need for preference data. Unlike SFT, which employs a generative approach and overlooks negative data, DFT adopts a discriminative paradigm that that increases the probability of positive answers while suppressing potentially negative ones, shifting from token prediction to data prediction. Our contributions include: (i) a discriminative probabilistic framework for fine-tuning LLMs by explicitly modeling the discriminative likelihood of an answer among all possible outputs given an input; (ii) efficient algorithms to optimize this discriminative likelihood; and (iii) extensive experiments demonstrating DFT's effectiveness, achieving performance better than SFT and comparable to if not better than SFT$\rightarrow$PO. The code can be found at https://github.com/PenGuln/DFT.
CityGPT: Empowering Urban Spatial Cognition of Large Language Models
Jun 20, 2024



Large language models(LLMs) with powerful language generation and reasoning capabilities have already achieved success in many domains, e.g., math and code generation. However, due to the lacking of physical world's corpus and knowledge during training, they usually fail to solve many real-life tasks in the urban space. In this paper, we propose CityGPT, a systematic framework for enhancing the capability of LLMs on understanding urban space and solving the related urban tasks by building a city-scale world model in the model. First, we construct a diverse instruction tuning dataset CityInstruction for injecting urban knowledge and enhancing spatial reasoning capability effectively. By using a mixture of CityInstruction and general instruction data, we fine-tune various LLMs (e.g., ChatGLM3-6B, Qwen1.5 and LLama3 series) to enhance their capability without sacrificing general abilities. To further validate the effectiveness of proposed methods, we construct a comprehensive benchmark CityEval to evaluate the capability of LLMs on diverse urban scenarios and problems. Extensive evaluation results demonstrate that small LLMs trained with CityInstruction can achieve competitive performance with commercial LLMs in the comprehensive evaluation of CityEval. The source codes are openly accessible to the research community via https://github.com/tsinghua-fib-lab/CityGPT.
CityBench: Evaluating the Capabilities of Large Language Model as World Model
Jun 20, 2024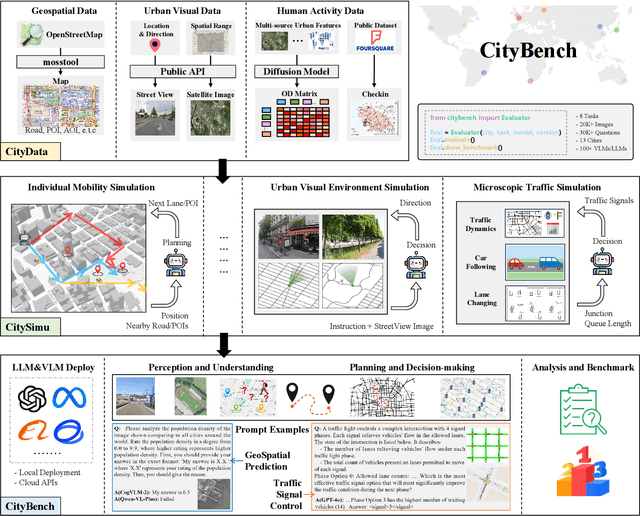
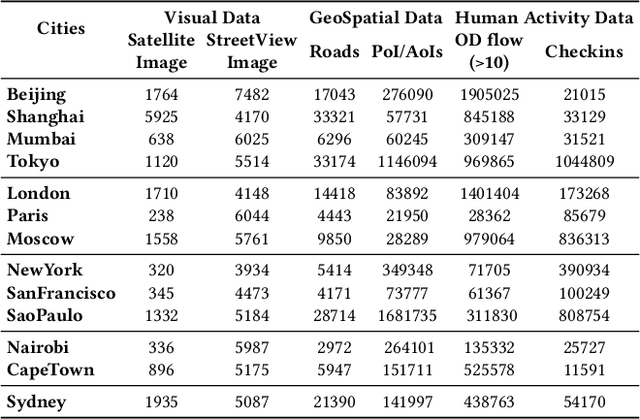
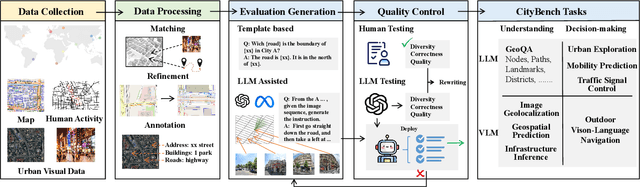
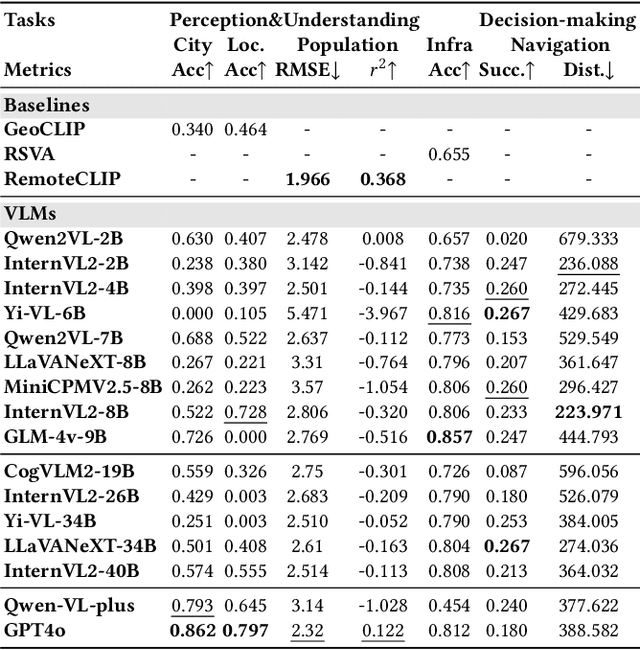
Large language models (LLMs) with powerful generalization ability has been widely used in many domains. A systematic and reliable evaluation of LLMs is a crucial step in their development and applications, especially for specific professional fields. In the urban domain, there have been some early explorations about the usability of LLMs, but a systematic and scalable evaluation benchmark is still lacking. The challenge in constructing a systematic evaluation benchmark for the urban domain lies in the diversity of data and scenarios, as well as the complex and dynamic nature of cities. In this paper, we propose CityBench, an interactive simulator based evaluation platform, as the first systematic evaluation benchmark for the capability of LLMs for urban domain. First, we build CitySim to integrate the multi-source data and simulate fine-grained urban dynamics. Based on CitySim, we design 7 tasks in 2 categories of perception-understanding and decision-making group to evaluate the capability of LLMs as city-scale world model for urban domain. Due to the flexibility and ease-of-use of CitySim, our evaluation platform CityBench can be easily extended to any city in the world. We evaluate 13 well-known LLMs including open source LLMs and commercial LLMs in 13 cities around the world. Extensive experiments demonstrate the scalability and effectiveness of proposed CityBench and shed lights for the future development of LLMs in urban domain. The dataset, benchmark and source codes are openly accessible to the research community via https://github.com/tsinghua-fib-lab/CityBench
To Cool or not to Cool? Temperature Network Meets Large Foundation Models via DRO
Apr 06, 2024The temperature parameter plays a profound role during training and/or inference with large foundation models (LFMs) such as large language models (LLMs) and CLIP models. Particularly, it adjusts the logits in the softmax function in LLMs, which is crucial for next token generation, and it scales the similarities in the contrastive loss for training CLIP models. A significant question remains: Is it viable to learn a neural network to predict a personalized temperature of any input data for enhancing LFMs"? In this paper, we present a principled framework for learning a small yet generalizable temperature prediction network (TempNet) to improve LFMs. Our solution is composed of a novel learning framework with a robust loss underpinned by constrained distributionally robust optimization (DRO), and a properly designed TempNet with theoretical inspiration. TempNet can be trained together with a large foundation model from scratch or learned separately given a pretrained foundation model. It is not only useful for predicting personalized temperature to promote the training of LFMs but also generalizable and transferable to new tasks. Our experiments on LLMs and CLIP models demonstrate that TempNet greatly improves the performance of existing solutions or models, e.g. Table 1. The code to reproduce the experimental results in this paper can be found at https://github.com/zhqiu/TempNet.