 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUrbanPlanBench: A Comprehensive Urban Planning Benchmark for Evaluating Large Language Models
Apr 23, 2025


The advent of Large Language Models (LLMs) holds promise for revolutionizing various fields traditionally dominated by human expertise. Urban planning, a professional discipline that fundamentally shapes our daily surroundings, is one such field heavily relying on multifaceted domain knowledge and experience of human experts. The extent to which LLMs can assist human practitioners in urban planning remains largely unexplored. In this paper, we introduce a comprehensive benchmark, UrbanPlanBench, tailored to evaluate the efficacy of LLMs in urban planning, which encompasses fundamental principles, professional knowledge, and management and regulations, aligning closely with the qualifications expected of human planners. Through extensive evaluation, we reveal a significant imbalance in the acquisition of planning knowledge among LLMs, with even the most proficient models falling short of meeting professional standards. For instance, we observe that 70% of LLMs achieve subpar performance in understanding planning regulations compared to other aspects. Besides the benchmark, we present the largest-ever supervised fine-tuning (SFT) dataset, UrbanPlanText, comprising over 30,000 instruction pairs sourced from urban planning exams and textbooks. Our findings demonstrate that fine-tuned models exhibit enhanced performance in memorization tests and comprehension of urban planning knowledge, while there exists significant room for improvement, particularly in tasks requiring domain-specific terminology and reasoning. By making our benchmark, dataset, and associated evaluation and fine-tuning toolsets publicly available at https://github.com/tsinghua-fib-lab/PlanBench, we aim to catalyze the integration of LLMs into practical urban planning, fostering a symbiotic collaboration between human expertise and machine intelligence.
A Survey of Large Language Model-Powered Spatial Intelligence Across Scales: Advances in Embodied Agents, Smart Cities, and Earth Science
Apr 14, 2025Over the past year, the development of large language models (LLMs) has brought spatial intelligence into focus, with much attention on vision-based embodied intelligence. However, spatial intelligence spans a broader range of disciplines and scales, from navigation and urban planning to remote sensing and earth science. What are the differences and connections between spatial intelligence across these fields? In this paper, we first review human spatial cognition and its implications for spatial intelligence in LLMs. We then examine spatial memory, knowledge representations, and abstract reasoning in LLMs, highlighting their roles and connections. Finally, we analyze spatial intelligence across scales -- from embodied to urban and global levels -- following a framework that progresses from spatial memory and understanding to spatial reasoning and intelligence. Through this survey, we aim to provide insights into interdisciplinary spatial intelligence research and inspire future studies.
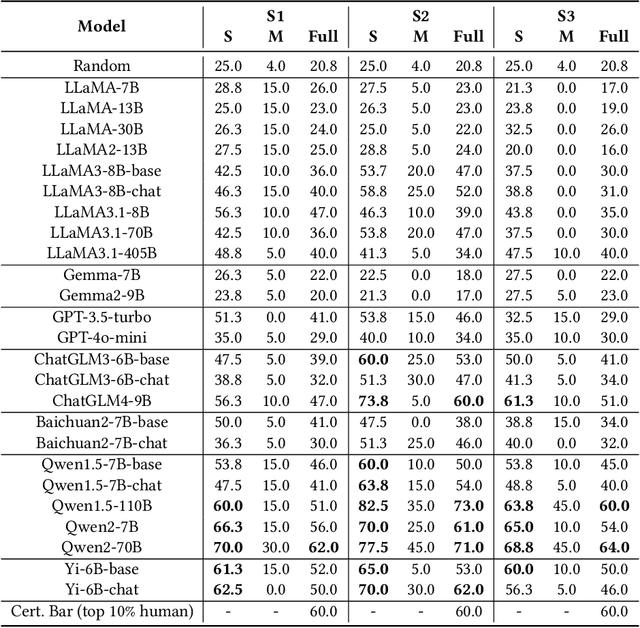
Knowledge-Guided Dynamic Modality Attention Fusion Framework for Multimodal Sentiment Analysis
Oct 06, 2024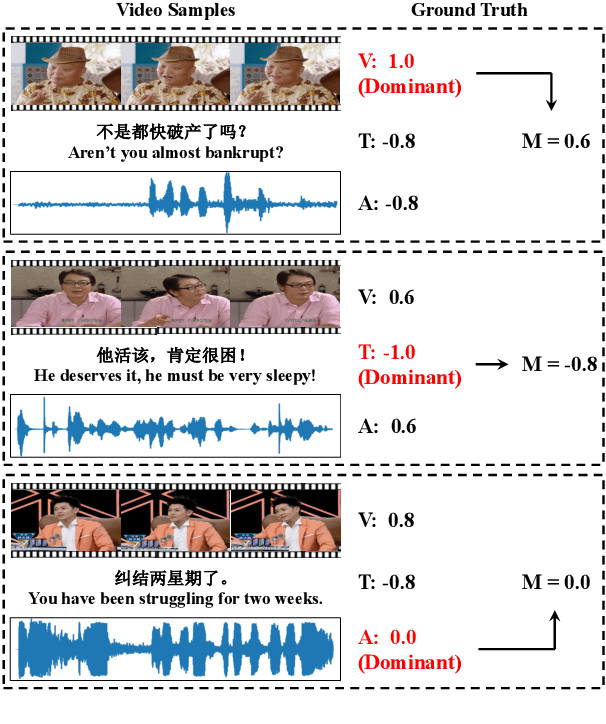
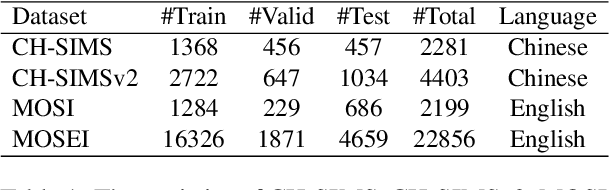
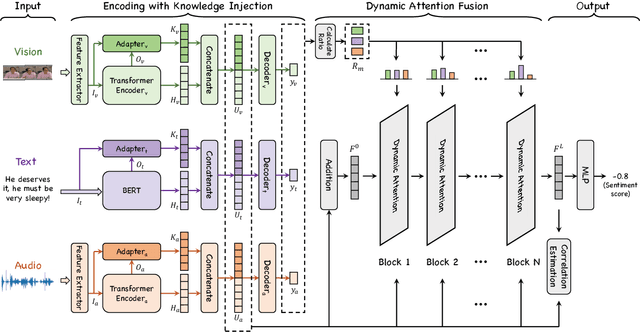
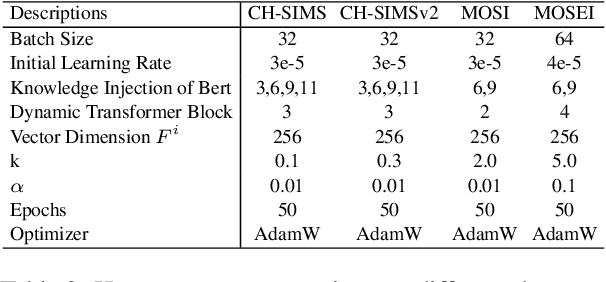
Multimodal Sentiment Analysis (MSA) utilizes multimodal data to infer the users' sentiment. Previous methods focus on equally treating the contribution of each modality or statically using text as the dominant modality to conduct interaction, which neglects the situation where each modality may become dominant. In this paper, we propose a Knowledge-Guided Dynamic Modality Attention Fusion Framework (KuDA) for multimodal sentiment analysis. KuDA uses sentiment knowledge to guide the model dynamically selecting the dominant modality and adjusting the contributions of each modality. In addition, with the obtained multimodal representation, the model can further highlight the contribution of dominant modality through the correlation evaluation loss. Extensive experiments on four MSA benchmark datasets indicate that KuDA achieves state-of-the-art performance and is able to adapt to different scenarios of dominant modality.
DailyDVS-200: A Comprehensive Benchmark Dataset for Event-Based Action Recognition
Jul 06, 2024



Neuromorphic sensors, specifically event cameras, revolutionize visual data acquisition by capturing pixel intensity changes with exceptional dynamic range, minimal latency, and energy efficiency, setting them apart from conventional frame-based cameras. The distinctive capabilities of event cameras have ignited significant interest in the domain of event-based action recognition, recognizing their vast potential for advancement. However, the development in this field is currently slowed by the lack of comprehensive, large-scale datasets, which are critical for developing robust recognition frameworks. To bridge this gap, we introduces DailyDVS-200, a meticulously curated benchmark dataset tailored for the event-based action recognition community. DailyDVS-200 is extensive, covering 200 action categories across real-world scenarios, recorded by 47 participants, and comprises more than 22,000 event sequences. This dataset is designed to reflect a broad spectrum of action types, scene complexities, and data acquisition diversity. Each sequence in the dataset is annotated with 14 attributes, ensuring a detailed characterization of the recorded actions. Moreover, DailyDVS-200 is structured to facilitate a wide range of research paths, offering a solid foundation for both validating existing approaches and inspiring novel methodologies. By setting a new benchmark in the field, we challenge the current limitations of neuromorphic data processing and invite a surge of new approaches in event-based action recognition techniques, which paves the way for future explorations in neuromorphic computing and beyond. The dataset and source code are available at https://github.com/QiWang233/DailyDVS-200.
CityGPT: Empowering Urban Spatial Cognition of Large Language Models
Jun 20, 2024



Large language models(LLMs) with powerful language generation and reasoning capabilities have already achieved success in many domains, e.g., math and code generation. However, due to the lacking of physical world's corpus and knowledge during training, they usually fail to solve many real-life tasks in the urban space. In this paper, we propose CityGPT, a systematic framework for enhancing the capability of LLMs on understanding urban space and solving the related urban tasks by building a city-scale world model in the model. First, we construct a diverse instruction tuning dataset CityInstruction for injecting urban knowledge and enhancing spatial reasoning capability effectively. By using a mixture of CityInstruction and general instruction data, we fine-tune various LLMs (e.g., ChatGLM3-6B, Qwen1.5 and LLama3 series) to enhance their capability without sacrificing general abilities. To further validate the effectiveness of proposed methods, we construct a comprehensive benchmark CityEval to evaluate the capability of LLMs on diverse urban scenarios and problems. Extensive evaluation results demonstrate that small LLMs trained with CityInstruction can achieve competitive performance with commercial LLMs in the comprehensive evaluation of CityEval. The source codes are openly accessible to the research community via https://github.com/tsinghua-fib-lab/CityGPT.
Large Language Model for Participatory Urban Planning
Feb 27, 2024



Participatory urban planning is the mainstream of modern urban planning that involves the active engagement of residents. However, the traditional participatory paradigm requires experienced planning experts and is often time-consuming and costly. Fortunately, the emerging Large Language Models (LLMs) have shown considerable ability to simulate human-like agents, which can be used to emulate the participatory process easily. In this work, we introduce an LLM-based multi-agent collaboration framework for participatory urban planning, which can generate land-use plans for urban regions considering the diverse needs of residents. Specifically, we construct LLM agents to simulate a planner and thousands of residents with diverse profiles and backgrounds. We first ask the planner to carry out an initial land-use plan. To deal with the different facilities needs of residents, we initiate a discussion among the residents in each community about the plan, where residents provide feedback based on their profiles. Furthermore, to improve the efficiency of discussion, we adopt a fishbowl discussion mechanism, where part of the residents discuss and the rest of them act as listeners in each round. Finally, we let the planner modify the plan based on residents' feedback. We deploy our method on two real-world regions in Beijing. Experiments show that our method achieves state-of-the-art performance in residents satisfaction and inclusion metrics, and also outperforms human experts in terms of service accessibility and ecology metrics.
UV-SAM: Adapting Segment Anything Model for Urban Village Identification
Feb 01, 2024



Urban villages, defined as informal residential areas in or around urban centers, are characterized by inadequate infrastructures and poor living conditions, closely related to the Sustainable Development Goals (SDGs) on poverty, adequate housing, and sustainable cities. Traditionally, governments heavily depend on field survey methods to monitor the urban villages, which however are time-consuming, labor-intensive, and possibly delayed. Thanks to widely available and timely updated satellite images, recent studies develop computer vision techniques to detect urban villages efficiently. However, existing studies either focus on simple urban village image classification or fail to provide accurate boundary information. To accurately identify urban village boundaries from satellite images, we harness the power of the vision foundation model and adapt the Segment Anything Model (SAM) to urban village segmentation, named UV-SAM. Specifically, UV-SAM first leverages a small-sized semantic segmentation model to produce mixed prompts for urban villages, including mask, bounding box, and image representations, which are then fed into SAM for fine-grained boundary identification. Extensive experimental results on two datasets in China demonstrate that UV-SAM outperforms existing baselines, and identification results over multiple years show that both the number and area of urban villages are decreasing over time, providing deeper insights into the development trends of urban villages and sheds light on the vision foundation models for sustainable cities. The dataset and codes of this study are available at https://github.com/tsinghua-fib-lab/UV-SAM.
Large language model empowered participatory urban planning
Jan 24, 2024



Participatory urban planning is the mainstream of modern urban planning and involves the active engagement of different stakeholders. However, the traditional participatory paradigm encounters challenges in time and manpower, while the generative planning tools fail to provide adjustable and inclusive solutions. This research introduces an innovative urban planning approach integrating Large Language Models (LLMs) within the participatory process. The framework, based on the crafted LLM agent, consists of role-play, collaborative generation, and feedback iteration, solving a community-level land-use task catering to 1000 distinct interests. Empirical experiments in diverse urban communities exhibit LLM's adaptability and effectiveness across varied planning scenarios. The results were evaluated on four metrics, surpassing human experts in satisfaction and inclusion, and rivaling state-of-the-art reinforcement learning methods in service and ecology. Further analysis shows the advantage of LLM agents in providing adjustable and inclusive solutions with natural language reasoning and strong scalability. While implementing the recent advancements in emulating human behavior for planning, this work envisions both planners and citizens benefiting from low-cost, efficient LLM agents, which is crucial for enhancing participation and realizing participatory urban planning.
Rethinking the Construction of Effective Metrics for Understanding the Mechanisms of Pretrained Language Models
Oct 19, 2023Pretrained language models are expected to effectively map input text to a set of vectors while preserving the inherent relationships within the text. Consequently, designing a white-box model to compute metrics that reflect the presence of specific internal relations in these vectors has become a common approach for post-hoc interpretability analysis of pretrained language models. However, achieving interpretability in white-box models and ensuring the rigor of metric computation becomes challenging when the source model lacks inherent interpretability. Therefore, in this paper, we discuss striking a balance in this trade-off and propose a novel line to constructing metrics for understanding the mechanisms of pretrained language models. We have specifically designed a family of metrics along this line of investigation, and the model used to compute these metrics is referred to as the tree topological probe. We conducted measurements on BERT-large by using these metrics. Based on the experimental results, we propose a speculation regarding the working mechanism of BERT-like pretrained language models, as well as a strategy for enhancing fine-tuning performance by leveraging the topological probe to improve specific submodules.