 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Granularity Mutual Refinement Network for Zero-Shot Learning
Nov 11, 2025Zero-shot learning (ZSL) aims to recognize unseen classes with zero samples by transferring semantic knowledge from seen classes. Current approaches typically correlate global visual features with semantic information (i.e., attributes) or align local visual region features with corresponding attributes to enhance visual-semantic interactions. Although effective, these methods often overlook the intrinsic interactions between local region features, which can further improve the acquisition of transferable and explicit visual features. In this paper, we propose a network named Multi-Granularity Mutual Refinement Network (Mg-MRN), which refine discriminative and transferable visual features by learning decoupled multi-granularity features and cross-granularity feature interactions. Specifically, we design a multi-granularity feature extraction module to learn region-level discriminative features through decoupled region feature mining. Then, a cross-granularity feature fusion module strengthens the inherent interactions between region features of varying granularities. This module enhances the discriminability of representations at each granularity level by integrating region representations from adjacent hierarchies, further improving ZSL recognition performance. Extensive experiments on three popular ZSL benchmark datasets demonstrate the superiority and competitiveness of our proposed Mg-MRN method. Our code is available at https://github.com/NingWang2049/Mg-MRN.
DailyDVS-200: A Comprehensive Benchmark Dataset for Event-Based Action Recognition
Jul 06, 2024



Neuromorphic sensors, specifically event cameras, revolutionize visual data acquisition by capturing pixel intensity changes with exceptional dynamic range, minimal latency, and energy efficiency, setting them apart from conventional frame-based cameras. The distinctive capabilities of event cameras have ignited significant interest in the domain of event-based action recognition, recognizing their vast potential for advancement. However, the development in this field is currently slowed by the lack of comprehensive, large-scale datasets, which are critical for developing robust recognition frameworks. To bridge this gap, we introduces DailyDVS-200, a meticulously curated benchmark dataset tailored for the event-based action recognition community. DailyDVS-200 is extensive, covering 200 action categories across real-world scenarios, recorded by 47 participants, and comprises more than 22,000 event sequences. This dataset is designed to reflect a broad spectrum of action types, scene complexities, and data acquisition diversity. Each sequence in the dataset is annotated with 14 attributes, ensuring a detailed characterization of the recorded actions. Moreover, DailyDVS-200 is structured to facilitate a wide range of research paths, offering a solid foundation for both validating existing approaches and inspiring novel methodologies. By setting a new benchmark in the field, we challenge the current limitations of neuromorphic data processing and invite a surge of new approaches in event-based action recognition techniques, which paves the way for future explorations in neuromorphic computing and beyond. The dataset and source code are available at https://github.com/QiWang233/DailyDVS-200.
Language Model Guided Interpretable Video Action Reasoning
Apr 02, 2024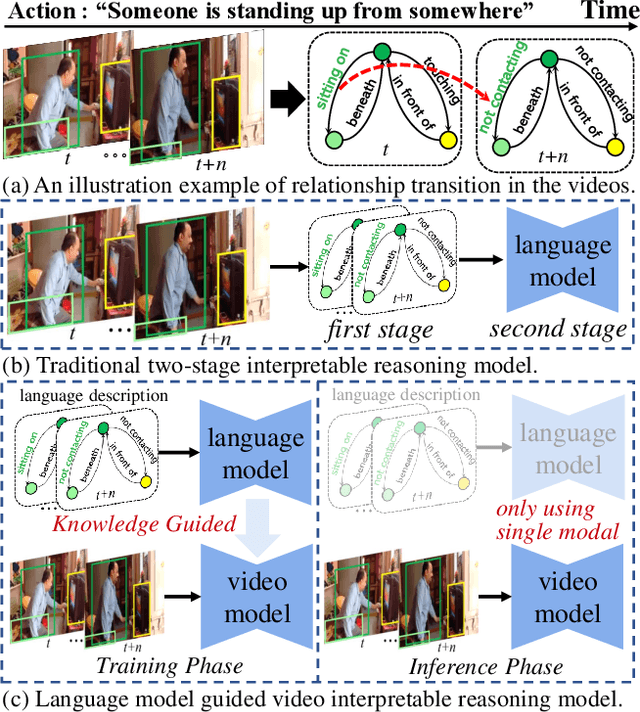
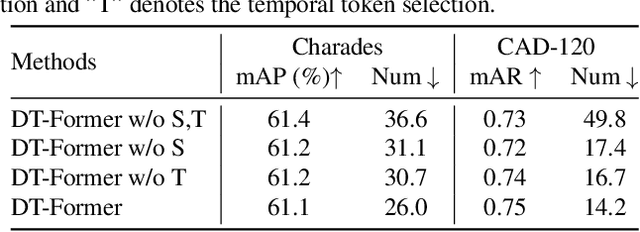
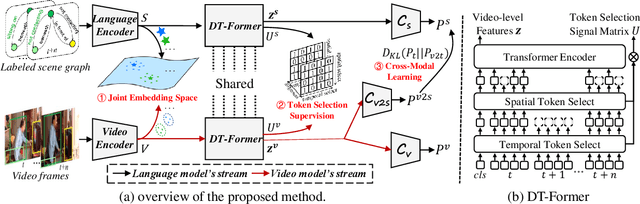
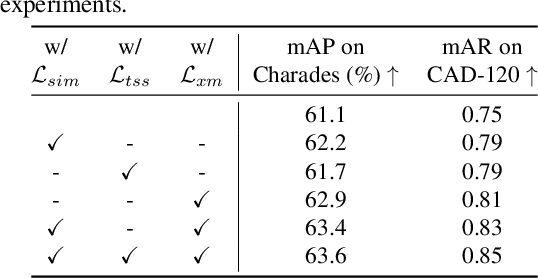
While neural networks have excelled in video action recognition tasks, their black-box nature often obscures the understanding of their decision-making processes. Recent approaches used inherently interpretable models to analyze video actions in a manner akin to human reasoning. These models, however, usually fall short in performance compared to their black-box counterparts. In this work, we present a new framework named Language-guided Interpretable Action Recognition framework (LaIAR). LaIAR leverages knowledge from language models to enhance both the recognition capabilities and the interpretability of video models. In essence, we redefine the problem of understanding video model decisions as a task of aligning video and language models. Using the logical reasoning captured by the language model, we steer the training of the video model. This integrated approach not only improves the video model's adaptability to different domains but also boosts its overall performance. Extensive experiments on two complex video action datasets, Charades & CAD-120, validates the improved performance and interpretability of our LaIAR framework. The code of LaIAR is available at https://github.com/NingWang2049/LaIAR.
Flowmind2Digital: The First Comprehensive Flowmind Recognition and Conversion Approach
Jan 08, 2024Flowcharts and mind maps, collectively known as flowmind, are vital in daily activities, with hand-drawn versions facilitating real-time collaboration. However, there's a growing need to digitize them for efficient processing. Automated conversion methods are essential to overcome manual conversion challenges. Existing sketch recognition methods face limitations in practical situations, being field-specific and lacking digital conversion steps. Our paper introduces the Flowmind2digital method and hdFlowmind dataset to address these challenges. Flowmind2digital, utilizing neural networks and keypoint detection, achieves a record 87.3% accuracy on our dataset, surpassing previous methods by 11.9%. The hdFlowmind dataset, comprising 1,776 annotated flowminds across 22 scenarios, outperforms existing datasets. Additionally, our experiments emphasize the importance of simple graphics, enhancing accuracy by 9.3%.
UE4-NeRF:Neural Radiance Field for Real-Time Rendering of Large-Scale Scene
Oct 20, 2023Neural Radiance Fields (NeRF) is a novel implicit 3D reconstruction method that shows immense potential and has been gaining increasing attention. It enables the reconstruction of 3D scenes solely from a set of photographs. However, its real-time rendering capability, especially for interactive real-time rendering of large-scale scenes, still has significant limitations. To address these challenges, in this paper, we propose a novel neural rendering system called UE4-NeRF, specifically designed for real-time rendering of large-scale scenes. We partitioned each large scene into different sub-NeRFs. In order to represent the partitioned independent scene, we initialize polygonal meshes by constructing multiple regular octahedra within the scene and the vertices of the polygonal faces are continuously optimized during the training process. Drawing inspiration from Level of Detail (LOD) techniques, we trained meshes of varying levels of detail for different observation levels. Our approach combines with the rasterization pipeline in Unreal Engine 4 (UE4), achieving real-time rendering of large-scale scenes at 4K resolution with a frame rate of up to 43 FPS. Rendering within UE4 also facilitates scene editing in subsequent stages. Furthermore, through experiments, we have demonstrated that our method achieves rendering quality comparable to state-of-the-art approaches. Project page: https://jamchaos.github.io/UE4-NeRF/.
Towards Visual Affordance Learning: A Benchmark for Affordance Segmentation and Recognition
Mar 26, 2022
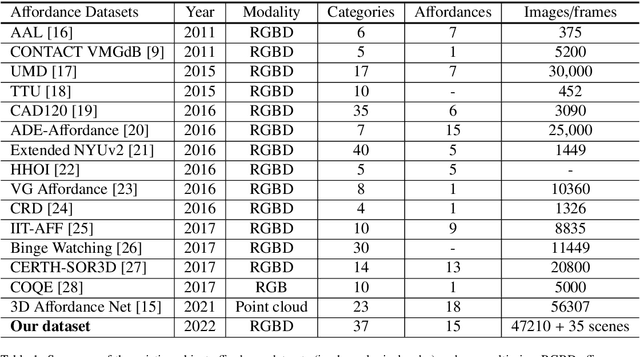
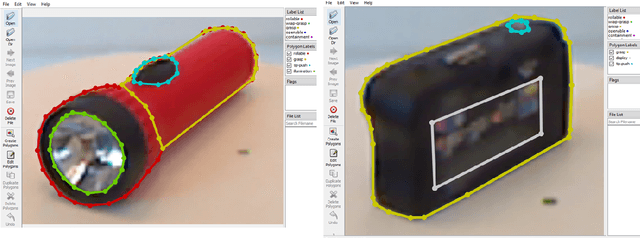
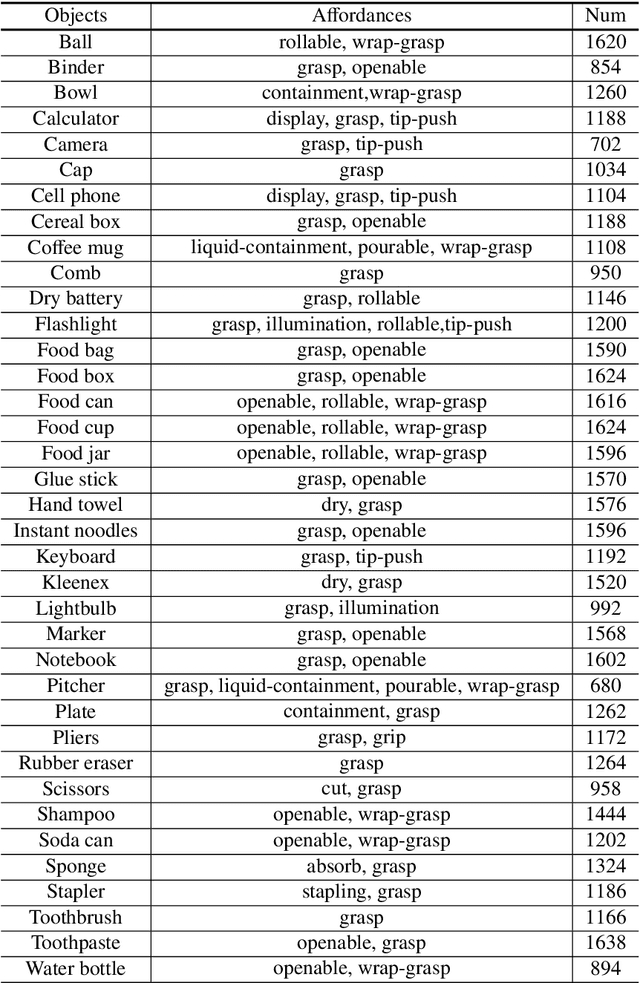
The physical and textural attributes of objects have been widely studied for recognition, detection and segmentation tasks in computer vision. A number of datasets, such as large scale ImageNet, have been proposed for feature learning using data hungry deep neural networks and for hand-crafted feature extraction. To intelligently interact with objects, robots and intelligent machines need the ability to infer beyond the traditional physical/textural attributes, and understand/learn visual cues, called visual affordances, for affordance recognition, detection and segmentation. To date there is no publicly available large dataset for visual affordance understanding and learning. In this paper, we introduce a large scale multi-view RGBD visual affordance learning dataset, a benchmark of 47210 RGBD images from 37 object categories, annotated with 15 visual affordance categories and 35 cluttered/complex scenes with different objects and multiple affordances. To the best of our knowledge, this is the first ever and the largest multi-view RGBD visual affordance learning dataset. We benchmark the proposed dataset for affordance recognition and segmentation. To achieve this we propose an Affordance Recognition Network a.k.a ARNet. In addition, four state-of-the-art deep learning networks are evaluated for affordance segmentation task. Our experimental results showcase the challenging nature of the dataset and present definite prospects for new and robust affordance learning algorithms. The dataset is available at: https://sites.google.com/view/afaqshah/dataset.
Scene Graph Generation: A Comprehensive Survey
Jan 03, 2022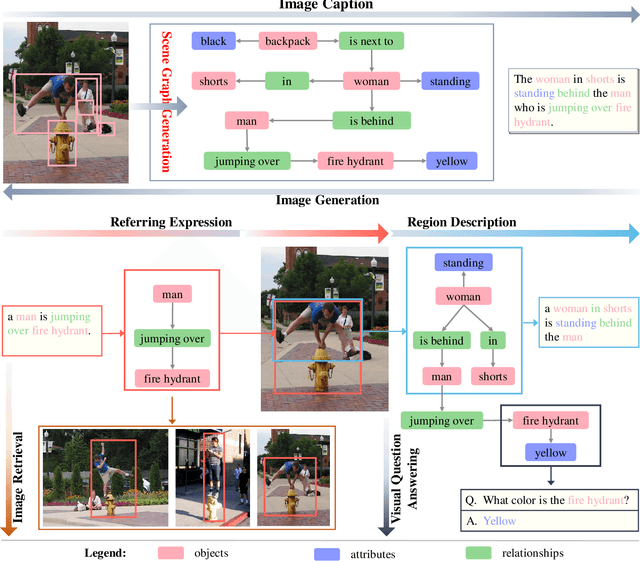
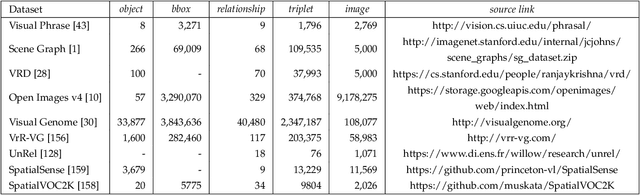
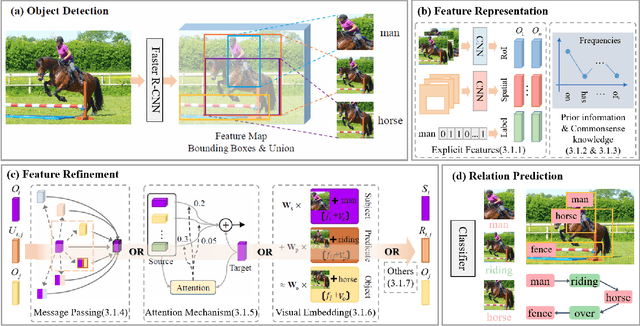
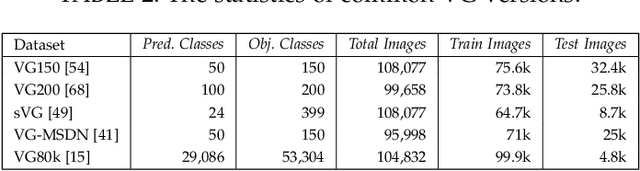
Deep learning techniques have led to remarkable breakthroughs in the field of generic object detection and have spawned a lot of scene-understanding tasks in recent years. Scene graph has been the focus of research because of its powerful semantic representation and applications to scene understanding. Scene Graph Generation (SGG) refers to the task of automatically mapping an image into a semantic structural scene graph, which requires the correct labeling of detected objects and their relationships. Although this is a challenging task, the community has proposed a lot of SGG approaches and achieved good results. In this paper, we provide a comprehensive survey of recent achievements in this field brought about by deep learning techniques. We review 138 representative works that cover different input modalities, and systematically summarize existing methods of image-based SGG from the perspective of feature extraction and fusion. We attempt to connect and systematize the existing visual relationship detection methods, to summarize, and interpret the mechanisms and the strategies of SGG in a comprehensive way. Finally, we finish this survey with deep discussions about current existing problems and future research directions. This survey will help readers to develop a better understanding of the current research status and ideas.
Deep Bayesian Image Set Classification: A Defence Approach against Adversarial Attacks
Aug 23, 2021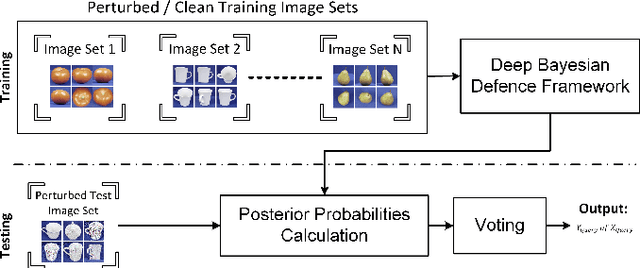
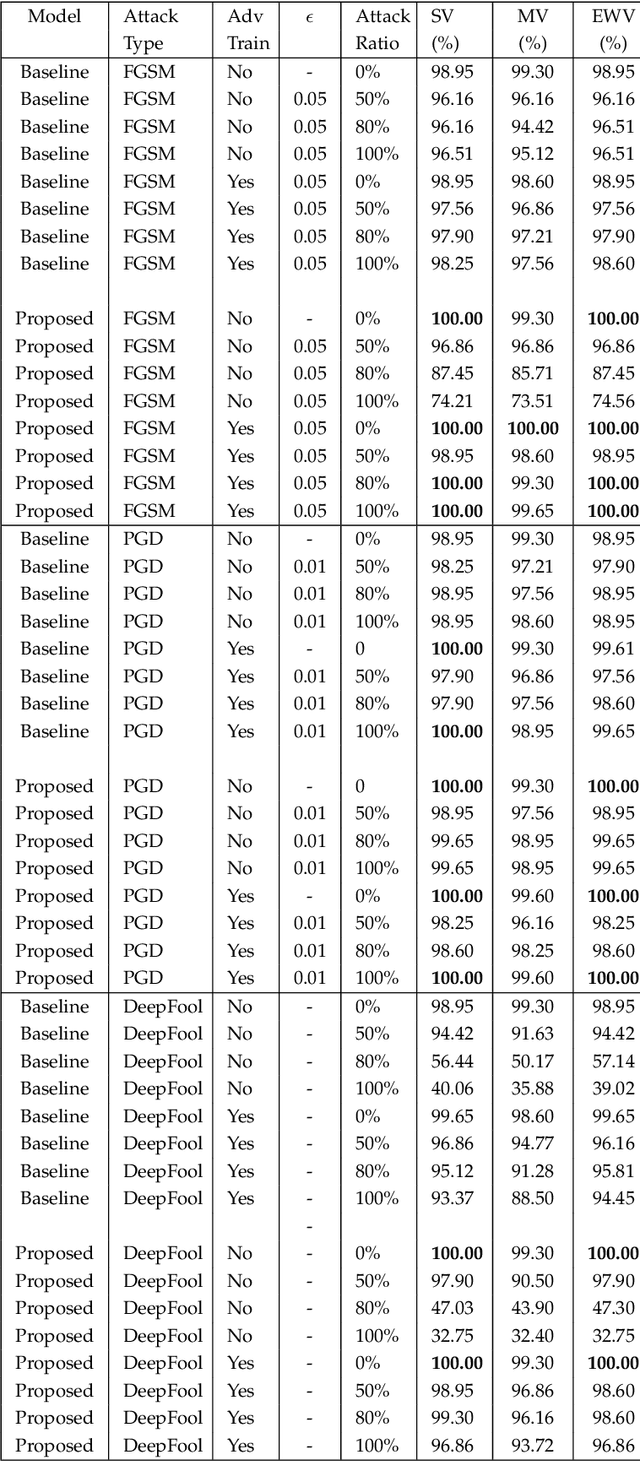
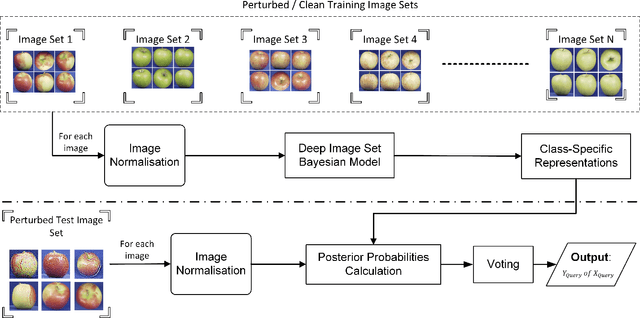
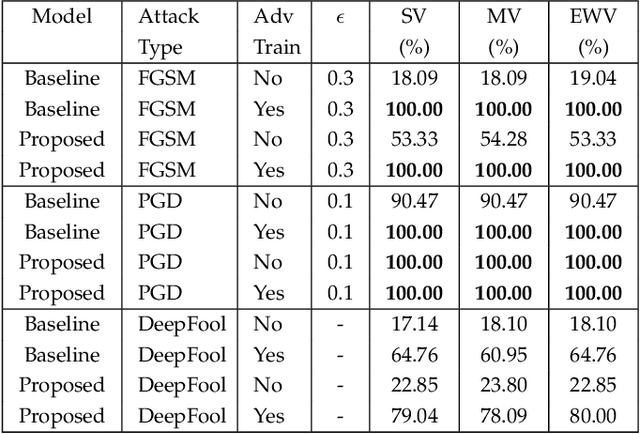
Deep learning has become an integral part of various computer vision systems in recent years due to its outstanding achievements for object recognition, facial recognition, and scene understanding. However, deep neural networks (DNNs) are susceptible to be fooled with nearly high confidence by an adversary. In practice, the vulnerability of deep learning systems against carefully perturbed images, known as adversarial examples, poses a dire security threat in the physical world applications. To address this phenomenon, we present, what to our knowledge, is the first ever image set based adversarial defence approach. Image set classification has shown an exceptional performance for object and face recognition, owing to its intrinsic property of handling appearance variability. We propose a robust deep Bayesian image set classification as a defence framework against a broad range of adversarial attacks. We extensively experiment the performance of the proposed technique with several voting strategies. We further analyse the effects of image size, perturbation magnitude, along with the ratio of perturbed images in each image set. We also evaluate our technique with the recent state-of-the-art defence methods, and single-shot recognition task. The empirical results demonstrate superior performance on CIFAR-10, MNIST, ETH-80, and Tiny ImageNet datasets.
A Systematic Collection of Medical Image Datasets for Deep Learning
Jun 24, 2021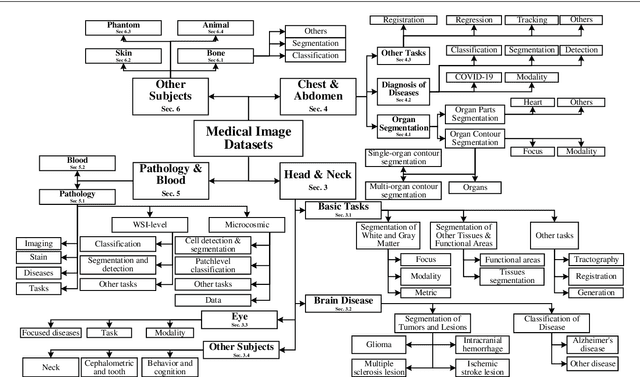
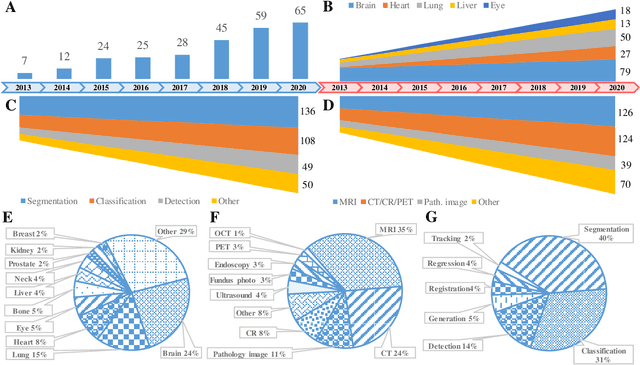
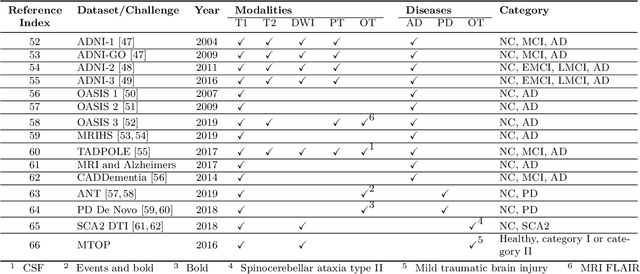
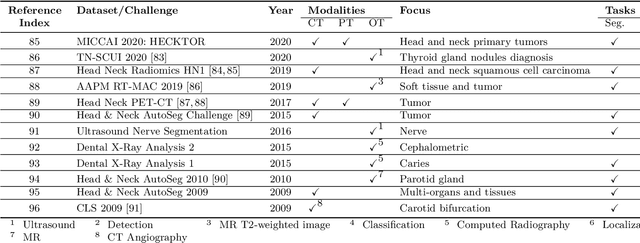
The astounding success made by artificial intelligence (AI) in healthcare and other fields proves that AI can achieve human-like performance. However, success always comes with challenges. Deep learning algorithms are data-dependent and require large datasets for training. The lack of data in the medical imaging field creates a bottleneck for the application of deep learning to medical image analysis. Medical image acquisition, annotation, and analysis are costly, and their usage is constrained by ethical restrictions. They also require many resources, such as human expertise and funding. That makes it difficult for non-medical researchers to have access to useful and large medical data. Thus, as comprehensive as possible, this paper provides a collection of medical image datasets with their associated challenges for deep learning research. We have collected information of around three hundred datasets and challenges mainly reported between 2013 and 2020 and categorized them into four categories: head & neck, chest & abdomen, pathology & blood, and ``others''. Our paper has three purposes: 1) to provide a most up to date and complete list that can be used as a universal reference to easily find the datasets for clinical image analysis, 2) to guide researchers on the methodology to test and evaluate their methods' performance and robustness on relevant datasets, 3) to provide a ``route'' to relevant algorithms for the relevant medical topics, and challenge leaderboards.
WEmbSim: A Simple yet Effective Metric for Image Captioning
Dec 24, 2020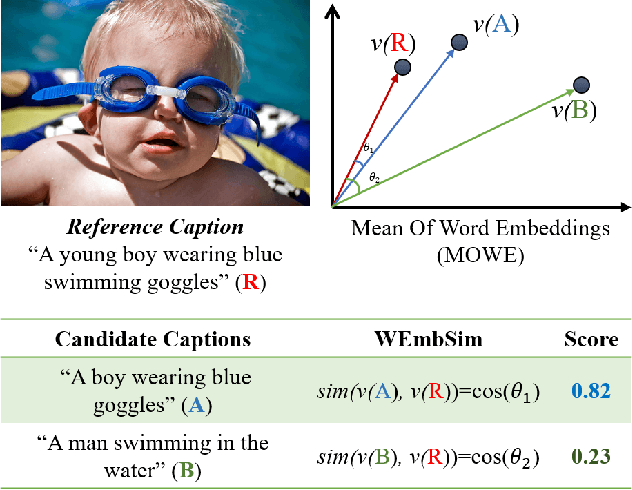
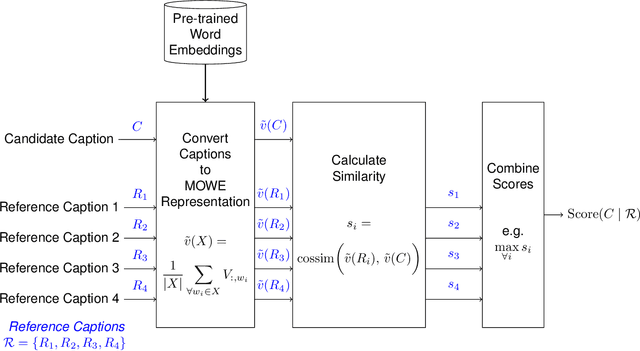

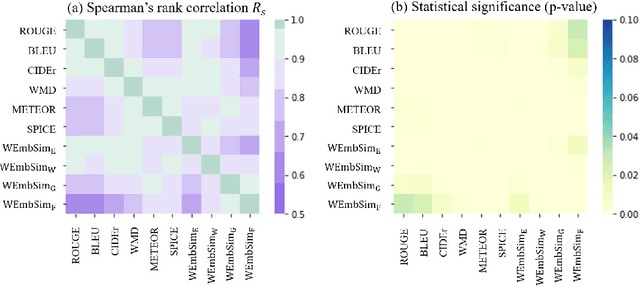
The area of automatic image caption evaluation is still undergoing intensive research to address the needs of generating captions which can meet adequacy and fluency requirements. Based on our past attempts at developing highly sophisticated learning-based metrics, we have discovered that a simple cosine similarity measure using the Mean of Word Embeddings(MOWE) of captions can actually achieve a surprisingly high performance on unsupervised caption evaluation. This inspires our proposed work on an effective metric WEmbSim, which beats complex measures such as SPICE, CIDEr and WMD at system-level correlation with human judgments. Moreover, it also achieves the best accuracy at matching human consensus scores for caption pairs, against commonly used unsupervised methods. Therefore, we believe that WEmbSim sets a new baseline for any complex metric to be justified.
* 7 pages