 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLCEval: Learned Composite Metric for Caption Evaluation
Paper and Code
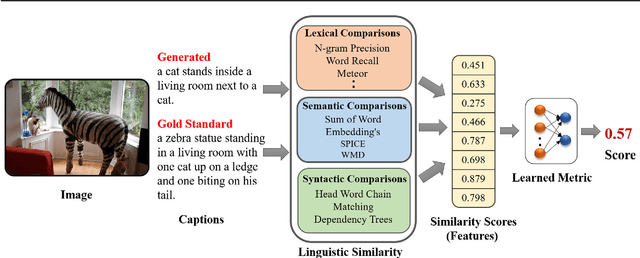

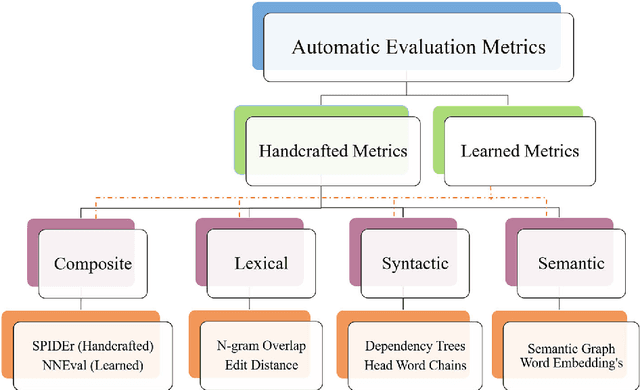
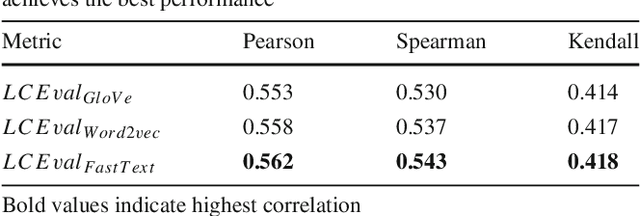
Automatic evaluation metrics hold a fundamental importance in the development and fine-grained analysis of captioning systems. While current evaluation metrics tend to achieve an acceptable correlation with human judgements at the system level, they fail to do so at the caption level. In this work, we propose a neural network-based learned metric to improve the caption-level caption evaluation. To get a deeper insight into the parameters which impact a learned metrics performance, this paper investigates the relationship between different linguistic features and the caption-level correlation of the learned metrics. We also compare metrics trained with different training examples to measure the variations in their evaluation. Moreover, we perform a robustness analysis, which highlights the sensitivity of learned and handcrafted metrics to various sentence perturbations. Our empirical analysis shows that our proposed metric not only outperforms the existing metrics in terms of caption-level correlation but it also shows a strong system-level correlation against human assessments.