 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbstractDifferentiation.jl: Backend-Agnostic Differentiable Programming in Julia
Sep 25, 2021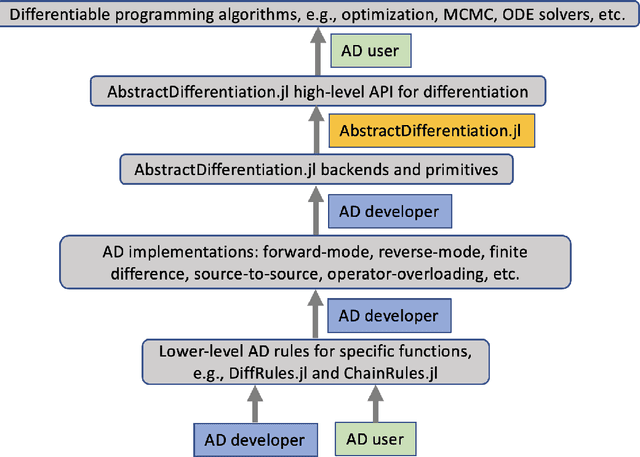
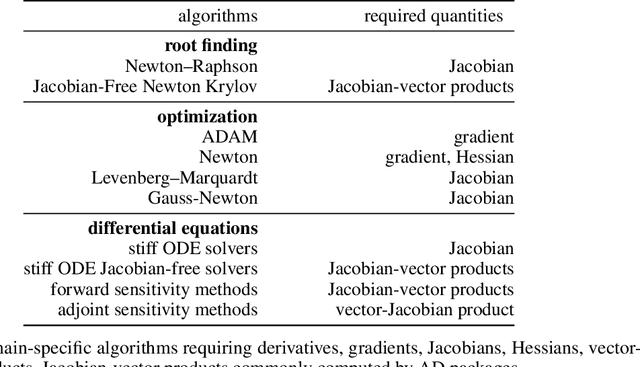
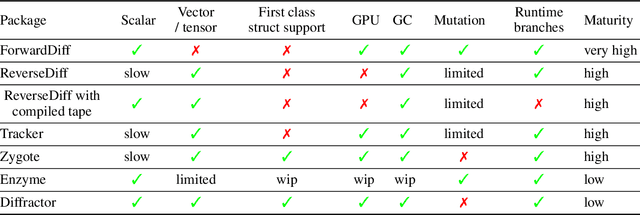
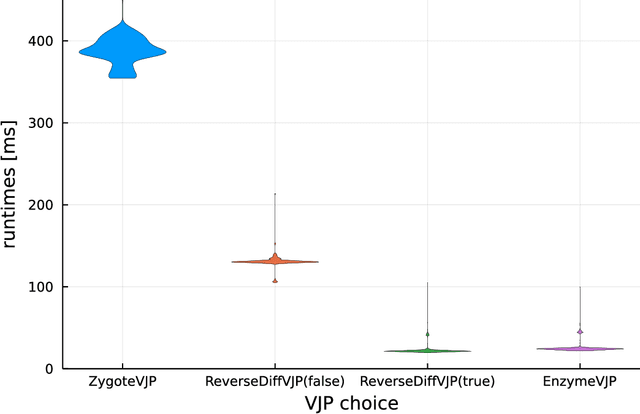
No single Automatic Differentiation (AD) system is the optimal choice for all problems. This means informed selection of an AD system and combinations can be a problem-specific variable that can greatly impact performance. In the Julia programming language, the major AD systems target the same input and thus in theory can compose. Hitherto, switching between AD packages in the Julia Language required end-users to familiarize themselves with the user-facing API of the respective packages. Furthermore, implementing a new, usable AD package required AD package developers to write boilerplate code to define convenience API functions for end-users. As a response to these issues, we present AbstractDifferentiation.jl for the automatized generation of an extensive, unified, user-facing API for any AD package. By splitting the complexity between AD users and AD developers, AD package developers only need to implement one or two primitive definitions to support various utilities for AD users like Jacobians, Hessians and lazy product operators from native primitives such as pullbacks or pushforwards, thus removing tedious -- but so far inevitable -- boilerplate code, and enabling the easy switching and composing between AD implementations for end-users.
WEmbSim: A Simple yet Effective Metric for Image Captioning
Dec 24, 2020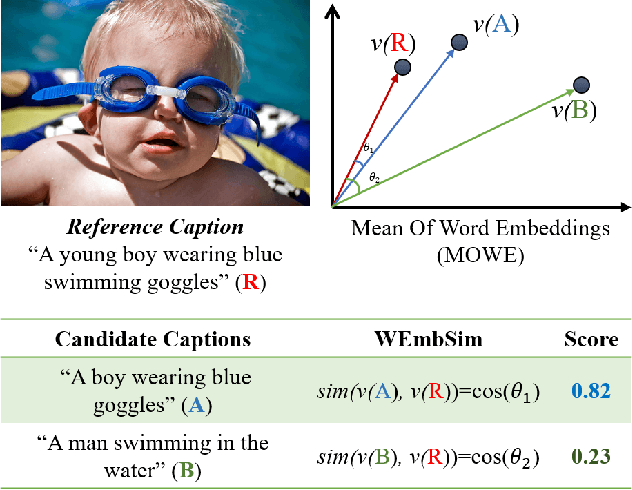
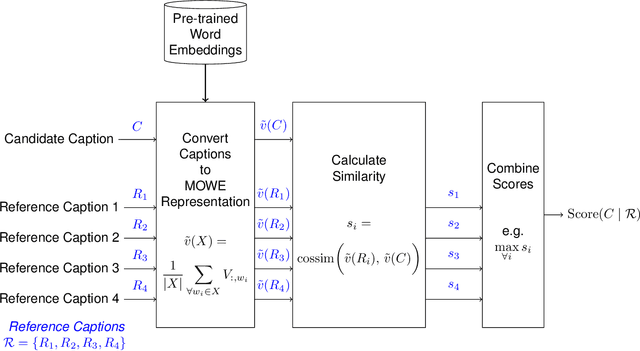

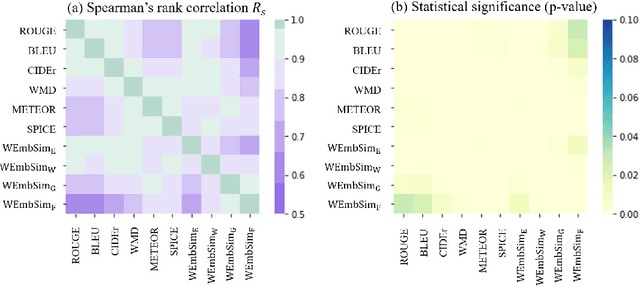
The area of automatic image caption evaluation is still undergoing intensive research to address the needs of generating captions which can meet adequacy and fluency requirements. Based on our past attempts at developing highly sophisticated learning-based metrics, we have discovered that a simple cosine similarity measure using the Mean of Word Embeddings(MOWE) of captions can actually achieve a surprisingly high performance on unsupervised caption evaluation. This inspires our proposed work on an effective metric WEmbSim, which beats complex measures such as SPICE, CIDEr and WMD at system-level correlation with human judgments. Moreover, it also achieves the best accuracy at matching human consensus scores for caption pairs, against commonly used unsupervised methods. Therefore, we believe that WEmbSim sets a new baseline for any complex metric to be justified.
* 7 pages
LCEval: Learned Composite Metric for Caption Evaluation
Dec 24, 2020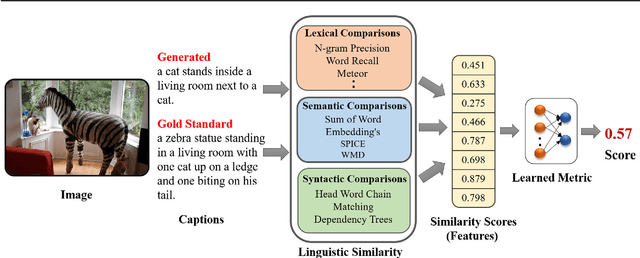

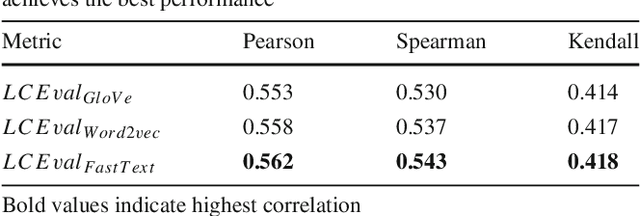
Automatic evaluation metrics hold a fundamental importance in the development and fine-grained analysis of captioning systems. While current evaluation metrics tend to achieve an acceptable correlation with human judgements at the system level, they fail to do so at the caption level. In this work, we propose a neural network-based learned metric to improve the caption-level caption evaluation. To get a deeper insight into the parameters which impact a learned metrics performance, this paper investigates the relationship between different linguistic features and the caption-level correlation of the learned metrics. We also compare metrics trained with different training examples to measure the variations in their evaluation. Moreover, we perform a robustness analysis, which highlights the sensitivity of learned and handcrafted metrics to various sentence perturbations. Our empirical analysis shows that our proposed metric not only outperforms the existing metrics in terms of caption-level correlation but it also shows a strong system-level correlation against human assessments.
* 18 pages
DiffEqFlux.jl - A Julia Library for Neural Differential Equations
Feb 06, 2019DiffEqFlux.jl is a library for fusing neural networks and differential equations. In this work we describe differential equations from the viewpoint of data science and discuss the complementary nature between machine learning models and differential equations. We demonstrate the ability to incorporate DifferentialEquations.jl-defined differential equation problems into a Flux-defined neural network, and vice versa. The advantages of being able to use the entire DifferentialEquations.jl suite for this purpose is demonstrated by counter examples where simple integration strategies fail, but the sophisticated integration strategies provided by the DifferentialEquations.jl library succeed. This is followed by a demonstration of delay differential equations and stochastic differential equations inside of neural networks. We show high-level functionality for defining neural ordinary differential equations (neural networks embedded into the differential equation) and describe the extra models in the Flux model zoo which includes neural stochastic differential equations. We conclude by discussing the various adjoint methods used for backpropogation of the differential equation solvers. DiffEqFlux.jl is an important contribution to the area, as it allows the full weight of the differential equation solvers developed from decades of research in the scientific computing field to be readily applied to the challenges posed by machine learning and data science.
Learning Distributions of Meant Color
May 03, 2018


When a speaker says the name of a color, the color that they picture is not necessarily the same as the listener imagines. Color is a grounded semantic task, but that grounding is not a mapping of a single word (or phrase) to a single point in color-space. Proper understanding of color language requires the capacity to map a sequence of words to a probability distribution in color-space. A distribution is required as there is no clear agreement between people as to what a particular color describes -- different people have a different idea of what it means to be `very dark orange'. We propose a novel GRU-based model to handle this case. Learning how each word in a color name contributes to the color described, allows for knowledge sharing between uses of the words in different color names. This knowledge sharing significantly improves predicative capacity for color names with sparse training data. The extreme case of this challenge in data sparsity is for color names without any direct training data. Our model is able to predict reasonable distributions for these cases, as evaluated on a held-out dataset consisting only of such terms.