 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkeletonContext: Skeleton-side Context Prompt Learning for Zero-Shot Skeleton-based Action Recognition
Mar 31, 2026Zero-shot skeleton-based action recognition aims to recognize unseen actions by transferring knowledge from seen categories through semantic descriptions. Most existing methods typically align skeleton features with textual embeddings within a shared latent space. However, the absence of contextual cues, such as objects involved in the action, introduces an inherent gap between skeleton and semantic representations, making it difficult to distinguish visually similar actions. To address this, we propose SkeletonContext, a prompt-based framework that enriches skeletal motion representations with language-driven contextual semantics. Specifically, we introduce a Cross-Modal Context Prompt Module, which leverages a pretrained language model to reconstruct masked contextual prompts under guidance derived from LLMs. This design effectively transfers linguistic context to the skeleton encoder for instance-level semantic grounding and improved cross-modal alignment. In addition, a Key-Part Decoupling Module is incorporated to decouple motion-relevant joint features, ensuring robust action understanding even in the absence of explicit object interactions. Extensive experiments on multiple benchmarks demonstrate that SkeletonContext achieves state-of-the-art performance under both conventional and generalized zero-shot settings, validating its effectiveness in reasoning about context and distinguishing fine-grained, visually similar actions.
Fact or Fake? Assessing the Role of Deepfake Detectors in Multimodal Misinformation Detection
Feb 02, 2026In multimodal misinformation, deception usually arises not just from pixel-level manipulations in an image, but from the semantic and contextual claim jointly expressed by the image-text pair. Yet most deepfake detectors, engineered to detect pixel-level forgeries, do not account for claim-level meaning, despite their growing integration in automated fact-checking (AFC) pipelines. This raises a central scientific and practical question: Do pixel-level detectors contribute useful signal for verifying image-text claims, or do they instead introduce misleading authenticity priors that undermine evidence-based reasoning? We provide the first systematic analysis of deepfake detectors in the context of multimodal misinformation detection. Using two complementary benchmarks, MMFakeBench and DGM4, we evaluate: (1) state-of-the-art image-only deepfake detectors, (2) an evidence-driven fact-checking system that performs tool-guided retrieval via Monte Carlo Tree Search (MCTS) and engages in deliberative inference through Multi-Agent Debate (MAD), and (3) a hybrid fact-checking system that injects detector outputs as auxiliary evidence. Results across both benchmark datasets show that deepfake detectors offer limited standalone value, achieving F1 scores in the range of 0.26-0.53 on MMFakeBench and 0.33-0.49 on DGM4, and that incorporating their predictions into fact-checking pipelines consistently reduces performance by 0.04-0.08 F1 due to non-causal authenticity assumptions. In contrast, the evidence-centric fact-checking system achieves the highest performance, reaching F1 scores of approximately 0.81 on MMFakeBench and 0.55 on DGM4. Overall, our findings demonstrate that multimodal claim verification is driven primarily by semantic understanding and external evidence, and that pixel-level artifact signals do not reliably enhance reasoning over real-world image-text misinformation.
Multimodal Neuroimaging Attention-Based architecture for Cognitive Decline Prediction
Dec 21, 2023The early detection of Alzheimer's Disease is imperative to ensure early treatment and improve patient outcomes. There has consequently been extenstive research into detecting AD and its intermediate phase, mild cognitive impairment (MCI). However, there is very small literature in predicting the conversion to AD and MCI from normal cognitive condition. Recently, multiple studies have applied convolutional neural networks (CNN) which integrate Magnetic Resonance Imaging (MRI) and Positron Emission Tomography (PET) to classify MCI and AD. However, in these works, the fusion of MRI and PET features are simply achieved through concatenation, resulting in a lack of cross-modal interactions. In this paper, we propose a novel multimodal neuroimaging attention-based CNN architecture, MNA-net, to predict whether cognitively normal (CN) individuals will develop MCI or AD within a period of 10 years. To address the lack of interactions across neuroimaging modalities seen in previous works, MNA-net utilises attention mechanisms to form shared representations of the MRI and PET images. The proposed MNA-net is tested in OASIS-3 dataset and is able to predict CN individuals who converted to MCI or AD with an accuracy of 83%, true negative rate of 80%, and true positive rate of 86%. The new state of the art results improved by 5% and 10% for accuracy and true negative rate by the use of attention mechanism. These results demonstrate the potential of the proposed model to predict cognitive impairment and attention based mechanisms in the fusion of different neuroimaging modalities to improve the prediction of cognitive decline.
WEmbSim: A Simple yet Effective Metric for Image Captioning
Dec 24, 2020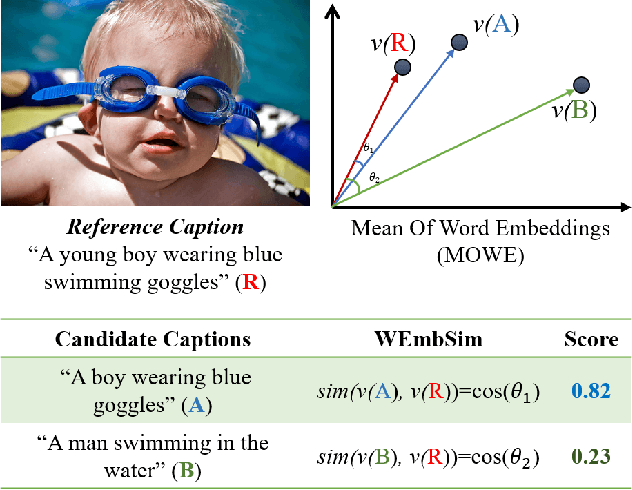
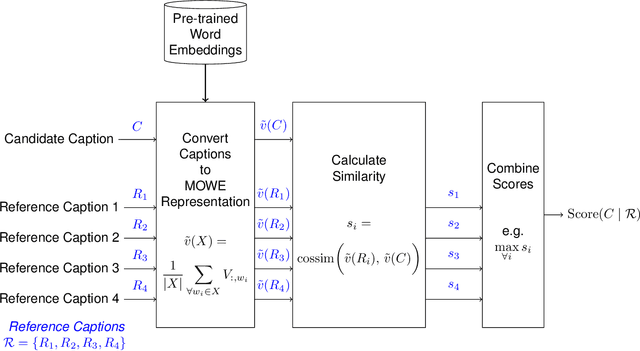

The area of automatic image caption evaluation is still undergoing intensive research to address the needs of generating captions which can meet adequacy and fluency requirements. Based on our past attempts at developing highly sophisticated learning-based metrics, we have discovered that a simple cosine similarity measure using the Mean of Word Embeddings(MOWE) of captions can actually achieve a surprisingly high performance on unsupervised caption evaluation. This inspires our proposed work on an effective metric WEmbSim, which beats complex measures such as SPICE, CIDEr and WMD at system-level correlation with human judgments. Moreover, it also achieves the best accuracy at matching human consensus scores for caption pairs, against commonly used unsupervised methods. Therefore, we believe that WEmbSim sets a new baseline for any complex metric to be justified.
* 7 pages
LCEval: Learned Composite Metric for Caption Evaluation
Dec 24, 2020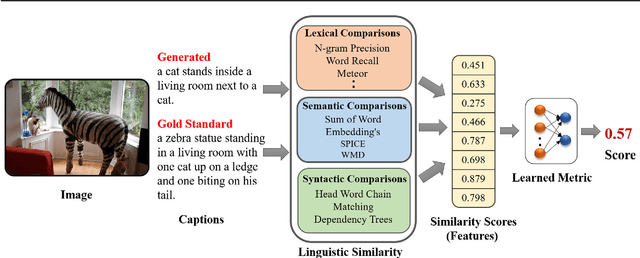

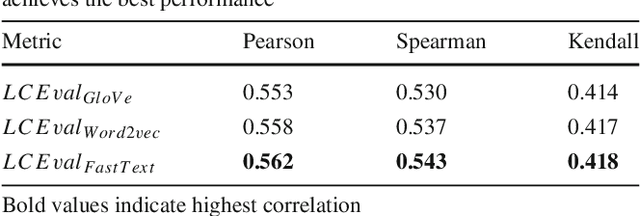
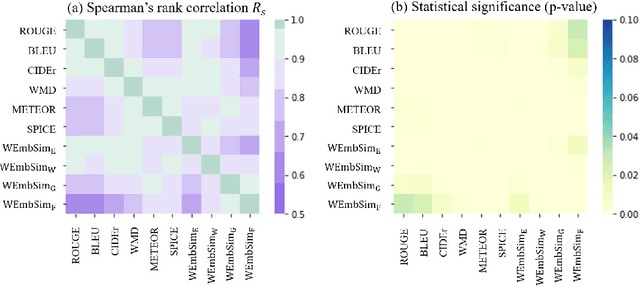
Automatic evaluation metrics hold a fundamental importance in the development and fine-grained analysis of captioning systems. While current evaluation metrics tend to achieve an acceptable correlation with human judgements at the system level, they fail to do so at the caption level. In this work, we propose a neural network-based learned metric to improve the caption-level caption evaluation. To get a deeper insight into the parameters which impact a learned metrics performance, this paper investigates the relationship between different linguistic features and the caption-level correlation of the learned metrics. We also compare metrics trained with different training examples to measure the variations in their evaluation. Moreover, we perform a robustness analysis, which highlights the sensitivity of learned and handcrafted metrics to various sentence perturbations. Our empirical analysis shows that our proposed metric not only outperforms the existing metrics in terms of caption-level correlation but it also shows a strong system-level correlation against human assessments.
* 18 pages
SubICap: Towards Subword-informed Image Captioning
Dec 24, 2020
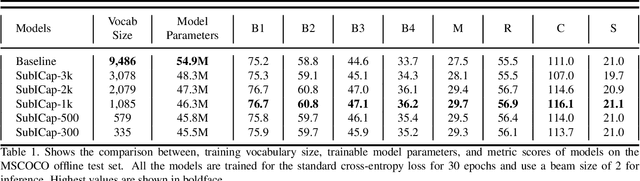
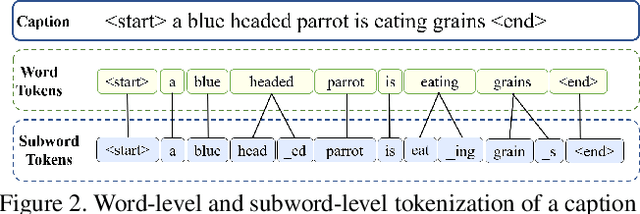
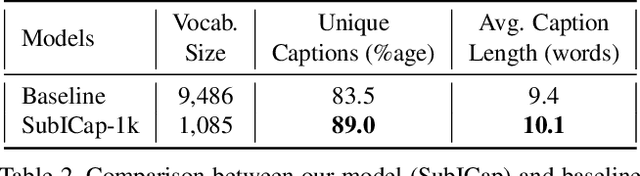
Existing Image Captioning (IC) systems model words as atomic units in captions and are unable to exploit the structural information in the words. This makes representation of rare words very difficult and out-of-vocabulary words impossible. Moreover, to avoid computational complexity, existing IC models operate over a modest sized vocabulary of frequent words, such that the identity of rare words is lost. In this work we address this common limitation of IC systems in dealing with rare words in the corpora. We decompose words into smaller constituent units 'subwords' and represent captions as a sequence of subwords instead of words. This helps represent all words in the corpora using a significantly lower subword vocabulary, leading to better parameter learning. Using subword language modeling, our captioning system improves various metric scores, with a training vocabulary size approximately 90% less than the baseline and various state-of-the-art word-level models. Our quantitative and qualitative results and analysis signify the efficacy of our proposed approach.
* 8 pages