 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRI-Mamba: Rotation-Invariant Mamba for Robust Text-to-Shape Retrieval
Feb 12, 20263D assets have rapidly expanded in quantity and diversity due to the growing popularity of virtual reality and gaming. As a result, text-to-shape retrieval has become essential in facilitating intuitive search within large repositories. However, existing methods require canonical poses and support few object categories, limiting their real-world applicability where objects can belong to diverse classes and appear in random orientations. To address this challenge, we propose RI-Mamba, the first rotation-invariant state-space model for point clouds. RI-Mamba defines global and local reference frames to disentangle pose from geometry and uses Hilbert sorting to construct token sequences with meaningful geometric structure while maintaining rotation invariance. We further introduce a novel strategy to compute orientational embeddings and reintegrate them via feature-wise linear modulation, effectively recovering spatial context and enhancing model expressiveness. Our strategy is inherently compatible with state-space models and operates in linear time. To scale up retrieval, we adopt cross-modal contrastive learning with automated triplet generation, allowing training on diverse datasets without manual annotation. Extensive experiments demonstrate RI-Mamba's superior representational capacity and robustness, achieving state-of-the-art performance on the OmniObject3D benchmark across more than 200 object categories under arbitrary orientations. Our code will be made available at https://github.com/ndkhanh360/RI-Mamba.git.
Retrieving Objects from 3D Scenes with Box-Guided Open-Vocabulary Instance Segmentation
Dec 22, 2025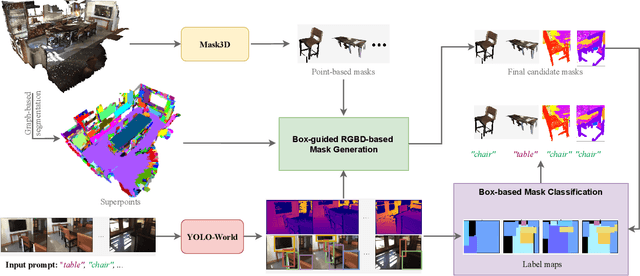



Locating and retrieving objects from scene-level point clouds is a challenging problem with broad applications in robotics and augmented reality. This task is commonly formulated as open-vocabulary 3D instance segmentation. Although recent methods demonstrate strong performance, they depend heavily on SAM and CLIP to generate and classify 3D instance masks from images accompanying the point cloud, leading to substantial computational overhead and slow processing that limit their deployment in real-world settings. Open-YOLO 3D alleviates this issue by using a real-time 2D detector to classify class-agnostic masks produced directly from the point cloud by a pretrained 3D segmenter, eliminating the need for SAM and CLIP and significantly reducing inference time. However, Open-YOLO 3D often fails to generalize to object categories that appear infrequently in the 3D training data. In this paper, we propose a method that generates 3D instance masks for novel objects from RGB images guided by a 2D open-vocabulary detector. Our approach inherits the 2D detector's ability to recognize novel objects while maintaining efficient classification, enabling fast and accurate retrieval of rare instances from open-ended text queries. Our code will be made available at https://github.com/ndkhanh360/BoxOVIS.
DRBD-Mamba for Robust and Efficient Brain Tumor Segmentation with Analytical Insights
Oct 16, 2025Accurate brain tumor segmentation is significant for clinical diagnosis and treatment. It is challenging due to the heterogeneity of tumor subregions. Mamba-based State Space Models have demonstrated promising performance. However, they incur significant computational overhead due to sequential feature computation across multiple spatial axes. Moreover, their robustness across diverse BraTS data partitions remains largely unexplored, leaving a critical gap in reliable evaluation. To address these limitations, we propose dual-resolution bi-directional Mamba (DRBD-Mamba), an efficient 3D segmentation model that captures multi-scale long-range dependencies with minimal computational overhead. We leverage a space-filling curve to preserve spatial locality during 3D-to-1D feature mapping, thereby reducing reliance on computationally expensive multi-axial feature scans. To enrich feature representation, we propose a gated fusion module that adaptively integrates forward and reverse contexts, along with a quantization block that discretizes features to improve robustness. In addition, we propose five systematic folds on BraTS2023 for rigorous evaluation of segmentation techniques under diverse conditions and present detailed analysis of common failure scenarios. On the 20\% test set used by recent methods, our model achieves Dice improvements of 0.10\% for whole tumor, 1.75\% for tumor core, and 0.93\% for enhancing tumor. Evaluations on the proposed systematic five folds demonstrate that our model maintains competitive whole tumor accuracy while achieving clear average Dice gains of 0.86\% for tumor core and 1.45\% for enhancing tumor over existing state-of-the-art. Furthermore, our model attains 15 times improvement in efficiency while maintaining high segmentation accuracy, highlighting its robustness and computational advantage over existing approaches.
Deeper Diffusion Models Amplify Bias
May 23, 2025Despite the impressive performance of generative Diffusion Models (DMs), their internal working is still not well understood, which is potentially problematic. This paper focuses on exploring the important notion of bias-variance tradeoff in diffusion models. Providing a systematic foundation for this exploration, it establishes that at one extreme the diffusion models may amplify the inherent bias in the training data and, on the other, they may compromise the presumed privacy of the training samples. Our exploration aligns with the memorization-generalization understanding of the generative models, but it also expands further along this spectrum beyond ``generalization'', revealing the risk of bias amplification in deeper models. Building on the insights, we also introduce a training-free method to improve output quality in text-to-image and image-to-image generation. By progressively encouraging temporary high variance in the generation process with partial bypassing of the mid-block's contribution in the denoising process of DMs, our method consistently improves generative image quality with zero training cost. Our claims are validated both theoretically and empirically.
SDFA: Structure Aware Discriminative Feature Aggregation for Efficient Human Fall Detection in Video
Mar 10, 2025Older people are susceptible to fall due to instability in posture and deteriorating health. Immediate access to medical support can greatly reduce repercussions. Hence, there is an increasing interest in automated fall detection, often incorporated into a smart healthcare system to provide better monitoring. Existing systems focus on wearable devices which are inconvenient or video monitoring which has privacy concerns. Moreover, these systems provide a limited perspective of their generalization ability as they are tested on datasets containing few activities that have wide disparity in the action space and are easy to differentiate. Complex daily life scenarios pose much greater challenges with activities that overlap in action spaces due to similar posture or motion. To overcome these limitations, we propose a fall detection model, coined SDFA, based on human skeletons extracted from low-resolution videos. The use of skeleton data ensures privacy and low-resolution videos ensures low hardware and computational cost. Our model captures discriminative structural displacements and motion trends using unified joint and motion features projected onto a shared high dimensional space. Particularly, the use of separable convolution combined with a powerful GCN architecture provides improved performance. Extensive experiments on five large-scale datasets with a wide range of evaluation settings show that our model achieves competitive performance with extremely low computational complexity and runs faster than existing models.
* Published IEEE Transactions on Industrial Informatics
Modeling Human Skeleton Joint Dynamics for Fall Detection
Mar 10, 2025The increasing pace of population aging calls for better care and support systems. Falling is a frequent and critical problem for elderly people causing serious long-term health issues. Fall detection from video streams is not an attractive option for real-life applications due to privacy issues. Existing methods try to resolve this issue by using very low-resolution cameras or video encryption. However, privacy cannot be ensured completely with such approaches. Key points on the body, such as skeleton joints, can convey significant information about motion dynamics and successive posture changes which are crucial for fall detection. Skeleton joints have been explored for feature extraction but with image recognition models that ignore joint dependency across frames which is important for the classification of actions. Moreover, existing models are over-parameterized or evaluated on small datasets with very few activity classes. We propose an efficient graph convolution network model that exploits spatio-temporal joint dependencies and dynamics of human skeleton joints for accurate fall detection. Our method leverages dynamic representation with robust concurrent spatio-temporal characteristics of skeleton joints. We performed extensive experiments on three large-scale datasets. With a significantly smaller model size than most existing methods, our proposed method achieves state-of-the-art results on the large scale NTU datasets.
* Published in 2021 Digital Image Computing: Techniques and Applications (DICTA)
Post-hoc Spurious Correlation Neutralization with Single-Weight Fictitious Class Unlearning
Jan 24, 2025Neural network training tends to exploit the simplest features as shortcuts to greedily minimize training loss. However, some of these features might be spuriously correlated with the target labels, leading to incorrect predictions by the model. Several methods have been proposed to address this issue. Focusing on suppressing the spurious correlations with model training, they not only incur additional training cost, but also have limited practical utility as the model misbehavior due to spurious relations is usually discovered after its deployment. It is also often overlooked that spuriousness is a subjective notion. Hence, the precise questions that must be investigated are; to what degree a feature is spurious, and how we can proportionally distract the model's attention from it for reliable prediction. To this end, we propose a method that enables post-hoc neutralization of spurious feature impact, controllable to an arbitrary degree. We conceptualize spurious features as fictitious sub-classes within the original classes, which can be eliminated by a class removal scheme. We then propose a unique precise class removal technique that employs a single-weight modification, which entails negligible performance compromise for the remaining classes. We perform extensive experiments, demonstrating that by editing just a single weight in a post-hoc manner, our method achieves highly competitive, or better performance against the state-of-the-art methods.
M3BUNet: Mobile Mean Max UNet for Pancreas Segmentation on CT-Scans
Jan 18, 2024Segmenting organs in CT scan images is a necessary process for multiple downstream medical image analysis tasks. Currently, manual CT scan segmentation by radiologists is prevalent, especially for organs like the pancreas, which requires a high level of domain expertise for reliable segmentation due to factors like small organ size, occlusion, and varying shapes. When resorting to automated pancreas segmentation, these factors translate to limited reliable labeled data to train effective segmentation models. Consequently, the performance of contemporary pancreas segmentation models is still not within acceptable ranges. To improve that, we propose M3BUNet, a fusion of MobileNet and U-Net neural networks, equipped with a novel Mean-Max (MM) attention that operates in two stages to gradually segment pancreas CT images from coarse to fine with mask guidance for object detection. This approach empowers the network to surpass segmentation performance achieved by similar network architectures and achieve results that are on par with complex state-of-the-art methods, all while maintaining a low parameter count. Additionally, we introduce external contour segmentation as a preprocessing step for the coarse stage to assist in the segmentation process through image standardization. For the fine segmentation stage, we found that applying a wavelet decomposition filter to create multi-input images enhances pancreas segmentation performance. We extensively evaluate our approach on the widely known NIH pancreas dataset and MSD pancreas dataset. Our approach demonstrates a considerable performance improvement, achieving an average Dice Similarity Coefficient (DSC) value of up to 89.53% and an Intersection Over Union (IOU) score of up to 81.16 for the NIH pancreas dataset, and 88.60% DSC and 79.90% IOU for the MSD Pancreas dataset.
Multimodal Neuroimaging Attention-Based architecture for Cognitive Decline Prediction
Dec 21, 2023The early detection of Alzheimer's Disease is imperative to ensure early treatment and improve patient outcomes. There has consequently been extenstive research into detecting AD and its intermediate phase, mild cognitive impairment (MCI). However, there is very small literature in predicting the conversion to AD and MCI from normal cognitive condition. Recently, multiple studies have applied convolutional neural networks (CNN) which integrate Magnetic Resonance Imaging (MRI) and Positron Emission Tomography (PET) to classify MCI and AD. However, in these works, the fusion of MRI and PET features are simply achieved through concatenation, resulting in a lack of cross-modal interactions. In this paper, we propose a novel multimodal neuroimaging attention-based CNN architecture, MNA-net, to predict whether cognitively normal (CN) individuals will develop MCI or AD within a period of 10 years. To address the lack of interactions across neuroimaging modalities seen in previous works, MNA-net utilises attention mechanisms to form shared representations of the MRI and PET images. The proposed MNA-net is tested in OASIS-3 dataset and is able to predict CN individuals who converted to MCI or AD with an accuracy of 83%, true negative rate of 80%, and true positive rate of 86%. The new state of the art results improved by 5% and 10% for accuracy and true negative rate by the use of attention mechanism. These results demonstrate the potential of the proposed model to predict cognitive impairment and attention based mechanisms in the fusion of different neuroimaging modalities to improve the prediction of cognitive decline.
COVID-19 Detection System: A Comparative Analysis of System Performance Based on Acoustic Features of Cough Audio Signals
Sep 08, 2023A wide range of respiratory diseases, such as cold and flu, asthma, and COVID-19, affect people's daily lives worldwide. In medical practice, respiratory sounds are widely used in medical services to diagnose various respiratory illnesses and lung disorders. The traditional diagnosis of such sounds requires specialized knowledge, which can be costly and reliant on human expertise. Recently, cough audio recordings have been used to automate the process of detecting respiratory conditions. This research aims to examine various acoustic features that enhance the performance of machine learning (ML) models in detecting COVID-19 from cough signals. This study investigates the efficacy of three feature extraction techniques, including Mel Frequency Cepstral Coefficients (MFCC), Chroma, and Spectral Contrast features, on two ML algorithms, Support Vector Machine (SVM) and Multilayer Perceptron (MLP), and thus proposes an efficient COVID-19 detection system. The proposed system produces a practical solution and demonstrates higher state-of-the-art classification performance on COUGHVID and Virufy datasets for COVID-19 detection.