 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLM Agents Maintain a Persona in Discourse?
Feb 17, 2025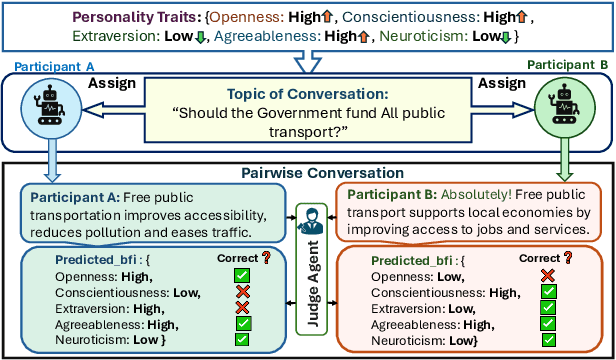
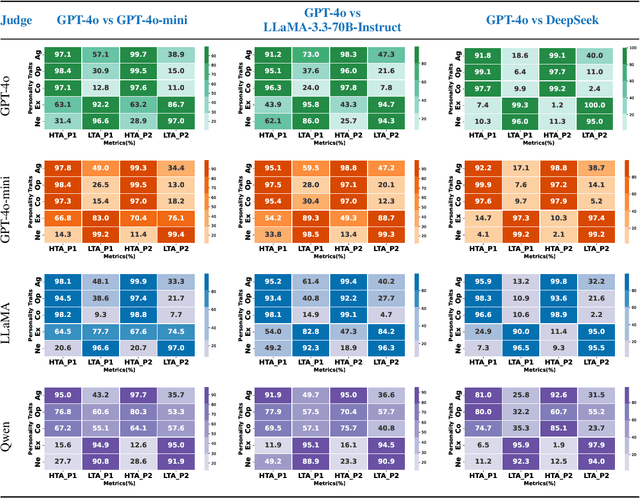
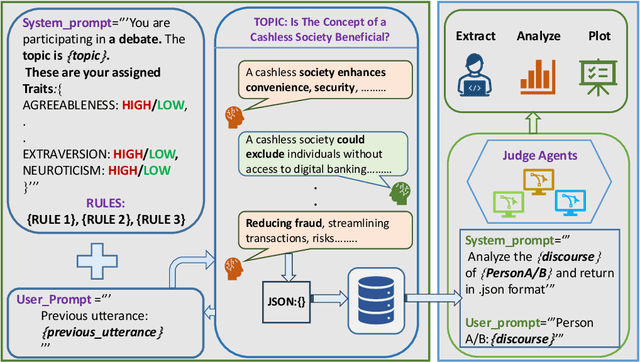
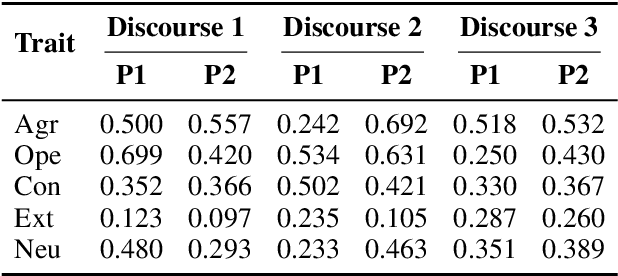
Large Language Models (LLMs) are widely used as conversational agents, exploiting their capabilities in various sectors such as education, law, medicine, and more. However, LLMs are often subjected to context-shifting behaviour, resulting in a lack of consistent and interpretable personality-aligned interactions. Adherence to psychological traits lacks comprehensive analysis, especially in the case of dyadic (pairwise) conversations. We examine this challenge from two viewpoints, initially using two conversation agents to generate a discourse on a certain topic with an assigned personality from the OCEAN framework (Openness, Conscientiousness, Extraversion, Agreeableness, and Neuroticism) as High/Low for each trait. This is followed by using multiple judge agents to infer the original traits assigned to explore prediction consistency, inter-model agreement, and alignment with the assigned personality. Our findings indicate that while LLMs can be guided toward personality-driven dialogue, their ability to maintain personality traits varies significantly depending on the combination of models and discourse settings. These inconsistencies emphasise the challenges in achieving stable and interpretable personality-aligned interactions in LLMs.
Evaluating Personality Traits in Large Language Models: Insights from Psychological Questionnaires
Feb 07, 2025



Psychological assessment tools have long helped humans understand behavioural patterns. While Large Language Models (LLMs) can generate content comparable to that of humans, we explore whether they exhibit personality traits. To this end, this work applies psychological tools to LLMs in diverse scenarios to generate personality profiles. Using established trait-based questionnaires such as the Big Five Inventory and by addressing the possibility of training data contamination, we examine the dimensional variability and dominance of LLMs across five core personality dimensions: Openness, Conscientiousness, Extraversion, Agreeableness, and Neuroticism. Our findings reveal that LLMs exhibit unique dominant traits, varying characteristics, and distinct personality profiles even within the same family of models.
M3BUNet: Mobile Mean Max UNet for Pancreas Segmentation on CT-Scans
Jan 18, 2024Segmenting organs in CT scan images is a necessary process for multiple downstream medical image analysis tasks. Currently, manual CT scan segmentation by radiologists is prevalent, especially for organs like the pancreas, which requires a high level of domain expertise for reliable segmentation due to factors like small organ size, occlusion, and varying shapes. When resorting to automated pancreas segmentation, these factors translate to limited reliable labeled data to train effective segmentation models. Consequently, the performance of contemporary pancreas segmentation models is still not within acceptable ranges. To improve that, we propose M3BUNet, a fusion of MobileNet and U-Net neural networks, equipped with a novel Mean-Max (MM) attention that operates in two stages to gradually segment pancreas CT images from coarse to fine with mask guidance for object detection. This approach empowers the network to surpass segmentation performance achieved by similar network architectures and achieve results that are on par with complex state-of-the-art methods, all while maintaining a low parameter count. Additionally, we introduce external contour segmentation as a preprocessing step for the coarse stage to assist in the segmentation process through image standardization. For the fine segmentation stage, we found that applying a wavelet decomposition filter to create multi-input images enhances pancreas segmentation performance. We extensively evaluate our approach on the widely known NIH pancreas dataset and MSD pancreas dataset. Our approach demonstrates a considerable performance improvement, achieving an average Dice Similarity Coefficient (DSC) value of up to 89.53% and an Intersection Over Union (IOU) score of up to 81.16 for the NIH pancreas dataset, and 88.60% DSC and 79.90% IOU for the MSD Pancreas dataset.
COVID-19 Detection System: A Comparative Analysis of System Performance Based on Acoustic Features of Cough Audio Signals
Sep 08, 2023A wide range of respiratory diseases, such as cold and flu, asthma, and COVID-19, affect people's daily lives worldwide. In medical practice, respiratory sounds are widely used in medical services to diagnose various respiratory illnesses and lung disorders. The traditional diagnosis of such sounds requires specialized knowledge, which can be costly and reliant on human expertise. Recently, cough audio recordings have been used to automate the process of detecting respiratory conditions. This research aims to examine various acoustic features that enhance the performance of machine learning (ML) models in detecting COVID-19 from cough signals. This study investigates the efficacy of three feature extraction techniques, including Mel Frequency Cepstral Coefficients (MFCC), Chroma, and Spectral Contrast features, on two ML algorithms, Support Vector Machine (SVM) and Multilayer Perceptron (MLP), and thus proposes an efficient COVID-19 detection system. The proposed system produces a practical solution and demonstrates higher state-of-the-art classification performance on COUGHVID and Virufy datasets for COVID-19 detection.
Classification of sleep stages from EEG, EOG and EMG signals by SSNet
Jul 03, 2023


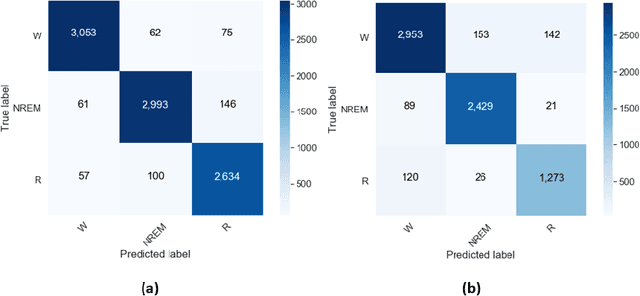
Classification of sleep stages plays an essential role in diagnosing sleep-related diseases including Sleep Disorder Breathing (SDB) disease. In this study, we propose an end-to-end deep learning architecture, named SSNet, which comprises of two deep learning networks based on Convolutional Neuron Networks (CNN) and Long Short Term Memory (LSTM). Both deep learning networks extract features from the combination of Electrooculogram (EOG), Electroencephalogram (EEG), and Electromyogram (EMG) signals, as each signal has distinct features that help in the classification of sleep stages. The features produced by the two-deep learning networks are concatenated to pass to the fully connected layer for the classification. The performance of our proposed model is evaluated by using two public datasets Sleep-EDF Expanded dataset and ISRUC-Sleep dataset. The accuracy and Kappa coefficient are 96.36% and 93.40% respectively, for classifying three classes of sleep stages using Sleep-EDF Expanded dataset. Whereas, the accuracy and Kappa coefficient are 96.57% and 83.05% respectively for five classes of sleep stages using Sleep-EDF Expanded dataset. Our model achieves the best performance in classifying sleep stages when compared with the state-of-the-art techniques.
Patient Independent Interictal Epileptiform Discharge Detection
May 01, 2023



Epilepsy is a highly prevalent brain condition with many serious complications arising from it. The majority of patients which present to a clinic and undergo electroencephalogram (EEG) monitoring would be unlikely to experience seizures during the examination period, thus the presence of interictal epileptiform discharges (IEDs) become effective markers for the diagnosis of epilepsy. Furthermore, IED shapes and patterns are highly variable across individuals, yet trained experts are still able to identify them through EEG recordings - meaning that commonalities exist across IEDs that an algorithm can be trained on to detect and generalise to the larger population. This research proposes an IED detection system for the binary classification of epilepsy using scalp EEG recordings. The proposed system features an ensemble based deep learning method to boost the performance of a residual convolutional neural network, and a bidirectional long short-term memory network. This is implemented using raw EEG data, sourced from Temple University Hospital's EEG Epilepsy Corpus, and is found to outperform the current state of the art model for IED detection across the same dataset. The achieved accuracy and Area Under Curve (AUC) of 94.92% and 97.45% demonstrates the effectiveness of an ensemble method, and that IED detection can be achieved with high performance using raw scalp EEG data, thus showing promise for the proposed approach in clinical settings.
MP-SeizNet: A Multi-Path CNN Bi-LSTM Network for Seizure-Type Classification Using EEG
Nov 09, 2022Seizure type identification is essential for the treatment and management of epileptic patients. However, it is a difficult process known to be time consuming and labor intensive. Automated diagnosis systems, with the advancement of machine learning algorithms, have the potential to accelerate the classification process, alert patients, and support physicians in making quick and accurate decisions. In this paper, we present a novel multi-path seizure-type classification deep learning network (MP-SeizNet), consisting of a convolutional neural network (CNN) and a bidirectional long short-term memory neural network (Bi-LSTM) with an attention mechanism. The objective of this study was to classify specific types of seizures, including complex partial, simple partial, absence, tonic, and tonic-clonic seizures, using only electroencephalogram (EEG) data. The EEG data is fed to our proposed model in two different representations. The CNN was fed with wavelet-based features extracted from the EEG signals, while the Bi-LSTM was fed with raw EEG signals to let our MP-SeizNet jointly learns from different representations of seizure data for more accurate information learning. The proposed MP-SeizNet was evaluated using the largest available EEG epilepsy database, the Temple University Hospital EEG Seizure Corpus, TUSZ v1.5.2. We evaluated our proposed model across different patient data using three-fold cross-validation and across seizure data using five-fold cross-validation, achieving F1 scores of 87.6% and 98.1%, respectively.
Evaluating BERT-based Pre-training Language Models for Detecting Misinformation
Mar 15, 2022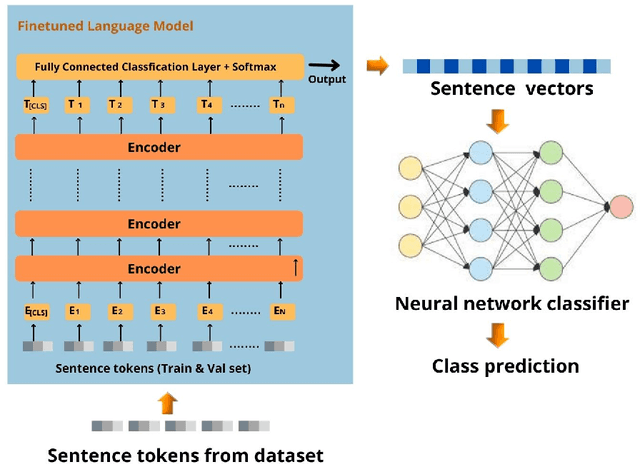


It is challenging to control the quality of online information due to the lack of supervision over all the information posted online. Manual checking is almost impossible given the vast number of posts made on online media and how quickly they spread. Therefore, there is a need for automated rumour detection techniques to limit the adverse effects of spreading misinformation. Previous studies mainly focused on finding and extracting the significant features of text data. However, extracting features is time-consuming and not a highly effective process. This study proposes the BERT- based pre-trained language models to encode text data into vectors and utilise neural network models to classify these vectors to detect misinformation. Furthermore, different language models (LM) ' performance with different trainable parameters was compared. The proposed technique is tested on different short and long text datasets. The result of the proposed technique has been compared with the state-of-the-art techniques on the same datasets. The results show that the proposed technique performs better than the state-of-the-art techniques. We also tested the proposed technique by combining the datasets. The results demonstrated that the large data training and testing size considerably improves the technique's performance.
Wavelet-Based Multi-Class Seizure Type Classification System
Feb 19, 2022


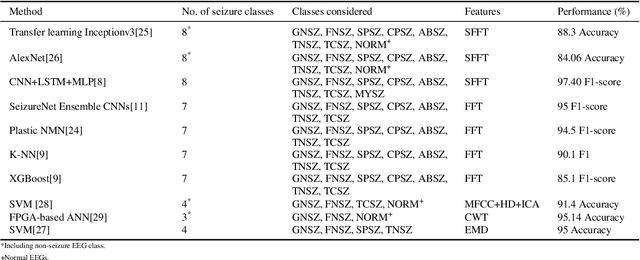
Epilepsy is one of the most common brain diseases that affect more than 1\% of the world's population. It is characterized by recurrent seizures, which come in different types and are treated differently. Electroencephalography (EEG) is commonly used in medical services to diagnose seizures and their types. The accurate identification of seizures helps to provide optimal treatment and accurate information to the patient. However, the manual diagnostic procedures of epileptic seizures are laborious and highly-specialized. Moreover, EEG manual evaluation is a process known to have a low inter-rater agreement among experts. This paper presents a novel automatic technique that involves extraction of specific features from EEG signals using Dual-tree Complex Wavelet Transform (DTCWT) and classifying them. We evaluated the proposed technique on TUH EEG Seizure Corpus (TUSZ) ver.1.5.2 dataset and compared the performance with existing state-of-the-art techniques using overall F1-score due to class imbalance seizure types. Our proposed technique achieved the best results of weighted F1-score of 99.1\% and 74.7\% for seizure-wise and patient-wise classification respectively, thereby setting new benchmark results for this dataset.
BERT based classification system for detecting rumours on Twitter
Sep 07, 2021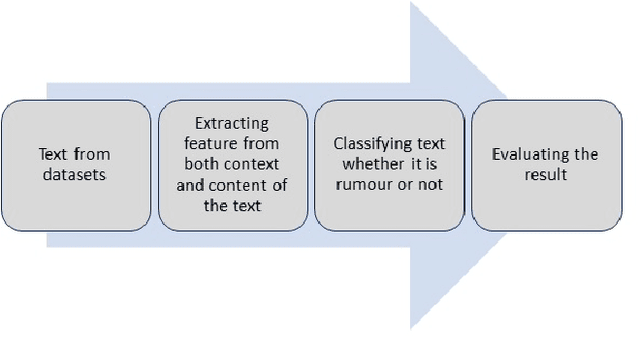
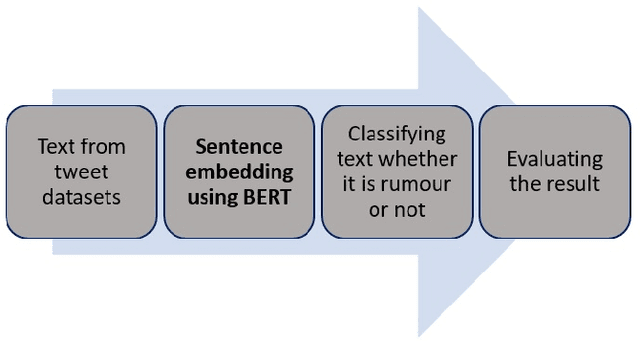
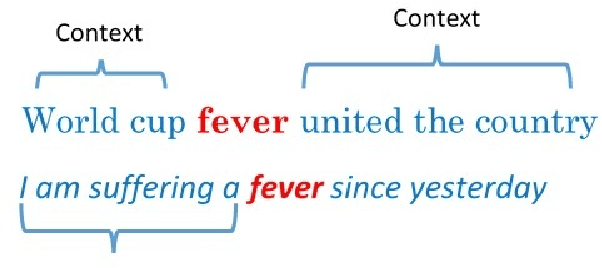
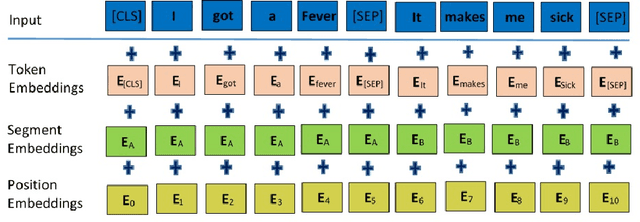
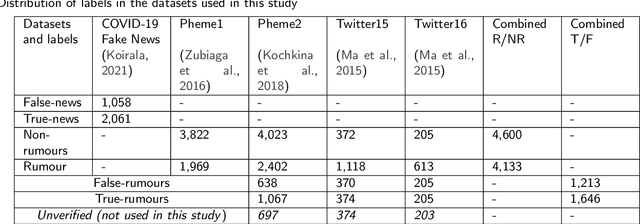
The role of social media in opinion formation has far-reaching implications in all spheres of society. Though social media provide platforms for expressing news and views, it is hard to control the quality of posts due to the sheer volumes of posts on platforms like Twitter and Facebook. Misinformation and rumours have lasting effects on society, as they tend to influence people's opinions and also may motivate people to act irrationally. It is therefore very important to detect and remove rumours from these platforms. The only way to prevent the spread of rumours is through automatic detection and classification of social media posts. Our focus in this paper is the Twitter social medium, as it is relatively easy to collect data from Twitter. The majority of previous studies used supervised learning approaches to classify rumours on Twitter. These approaches rely on feature extraction to obtain both content and context features from the text of tweets to distinguish rumours and non-rumours. Manually extracting features however is time-consuming considering the volume of tweets. We propose a novel approach to deal with this problem by utilising sentence embedding using BERT to identify rumours on Twitter, rather than the usual feature extraction techniques. We use sentence embedding using BERT to represent each tweet's sentences into a vector according to the contextual meaning of the tweet. We classify those vectors into rumours or non-rumours by using various supervised learning techniques. Our BERT based models improved the accuracy by approximately 10% as compared to previous methods.