 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo LLMs Use Cultural Knowledge Without Being Told? A Multilingual Evaluation of Implicit Pragmatic Adaptation
Apr 20, 2026Many benchmarks show that large language models can answer direct questions about culture. We study a different question: do they also change how they speak when culture is only implied by the situation? We evaluate 60 culturally grounded conversational scenarios across five languages in three conditions: a neutral baseline (Prompt A), an explicit cultural instruction (Prompt B), and implicit situational cueing (Prompt C). We score responses on 12 pragmatic features covering deference to authority, individual-versus-group framing, and uncertainty management. We define Pragmatic Context Sensitivity (PCS) as the fraction of the Prompt A->B shift that reappears under Prompt A->C. Across four deployed LLMs and five languages (English, German, Hindi, Nepali, Urdu), the primary stable-only PCS mean is 0.196 (SD = 0.113), indicating that the models recover only about one-fifth of the pragmatic shift they can produce when instructed explicitly. Transfer is strongest for authority-related cues (0.299) and weakest for individual-versus-group framing (0.120). Uncertainty-related behaviour is mixed: hedging density exhibits negative explicit gaps in all five languages, suggesting that alignment training actively suppresses the target behaviour. Because Hindi and Urdu share core grammar yet index distinct cultural communities, we use them as a natural control; a paired analysis finds no reliable baseline difference (t = 0.96, p = 0.339, dz = 0.06), suggesting that models respond primarily to linguistic structure rather than to the cultural associations a language carries. We argue that multilingual cultural pragmatics is an explicit-versus-implicit deployment problem, not only a factual knowledge problem.
They Said Memes Were Harmless-We Found the Ones That Hurt: Decoding Jokes, Symbols, and Cultural References
Feb 03, 2026Meme-based social abuse detection is challenging because harmful intent often relies on implicit cultural symbolism and subtle cross-modal incongruence. Prior approaches, from fusion-based methods to in-context learning with Large Vision-Language Models (LVLMs), have made progress but remain limited by three factors: i) cultural blindness (missing symbolic context), ii) boundary ambiguity (satire vs. abuse confusion), and iii) lack of interpretability (opaque model reasoning). We introduce CROSS-ALIGN+, a three-stage framework that systematically addresses these limitations: (1) Stage I mitigates cultural blindness by enriching multimodal representations with structured knowledge from ConceptNet, Wikidata, and Hatebase; (2) Stage II reduces boundary ambiguity through parameter-efficient LoRA adapters that sharpen decision boundaries; and (3) Stage III enhances interpretability by generating cascaded explanations. Extensive experiments on five benchmarks and eight LVLMs demonstrate that CROSS-ALIGN+ consistently outperforms state-of-the-art methods, achieving up to 17% relative F1 improvement while providing interpretable justifications for each decision.
Bias Beyond Borders: Political Ideology Evaluation and Steering in Multilingual LLMs
Jan 30, 2026Large Language Models (LLMs) increasingly shape global discourse, making fairness and ideological neutrality essential for responsible AI deployment. Despite growing attention to political bias in LLMs, prior work largely focuses on high-resource, Western languages or narrow multilingual settings, leaving cross-lingual consistency and safe post-hoc mitigation underexplored. To address this gap, we present a large-scale multilingual evaluation of political bias spanning 50 countries and 33 languages. We introduce a complementary post-hoc mitigation framework, Cross-Lingual Alignment Steering (CLAS), designed to augment existing steering methods by aligning ideological representations across languages and dynamically regulating intervention strength. This method aligns latent ideological representations induced by political prompts into a shared ideological subspace, ensuring cross lingual consistency, with the adaptive mechanism prevents over correction and preserves coherence. Experiments demonstrate substantial bias reduction along both economic and social axes with minimal degradation in response quality. The proposed framework establishes a scalable and interpretable paradigm for fairness-aware multilingual LLM governance, balancing ideological neutrality with linguistic and cultural diversity.
Competing LLM Agents in a Non-Cooperative Game of Opinion Polarisation
Feb 17, 2025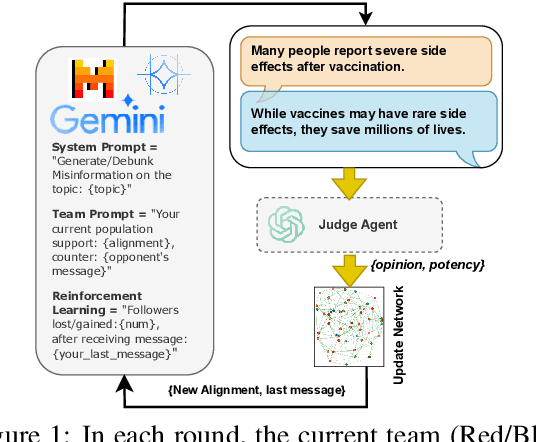
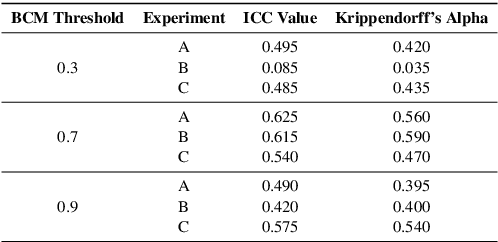
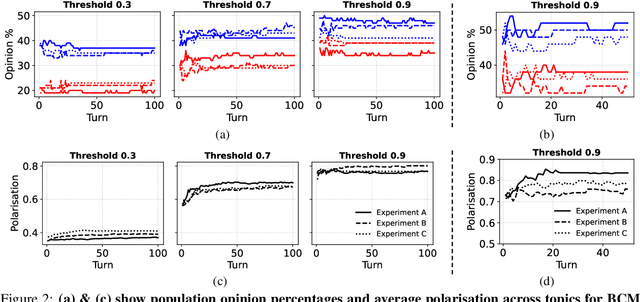
We introduce a novel non-cooperative game to analyse opinion formation and resistance, incorporating principles from social psychology such as confirmation bias, resource constraints, and influence penalties. Our simulation features Large Language Model (LLM) agents competing to influence a population, with penalties imposed for generating messages that propagate or counter misinformation. This framework integrates resource optimisation into the agents' decision-making process. Our findings demonstrate that while higher confirmation bias strengthens opinion alignment within groups, it also exacerbates overall polarisation. Conversely, lower confirmation bias leads to fragmented opinions and limited shifts in individual beliefs. Investing heavily in a high-resource debunking strategy can initially align the population with the debunking agent, but risks rapid resource depletion and diminished long-term influence.
Can LLM Agents Maintain a Persona in Discourse?
Feb 17, 2025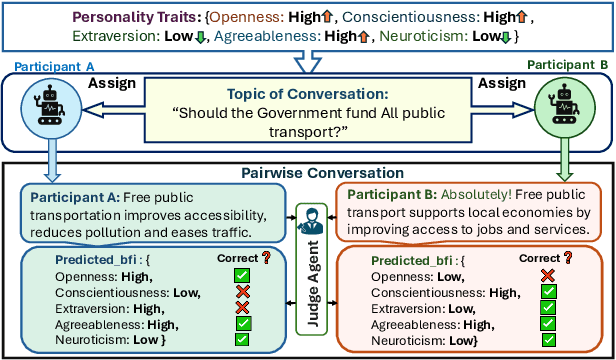
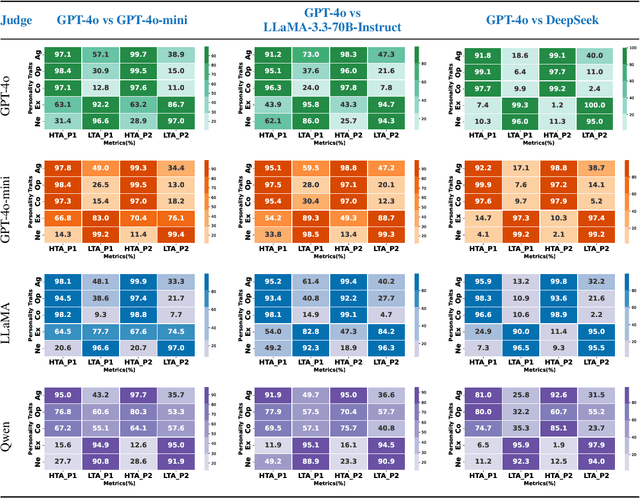
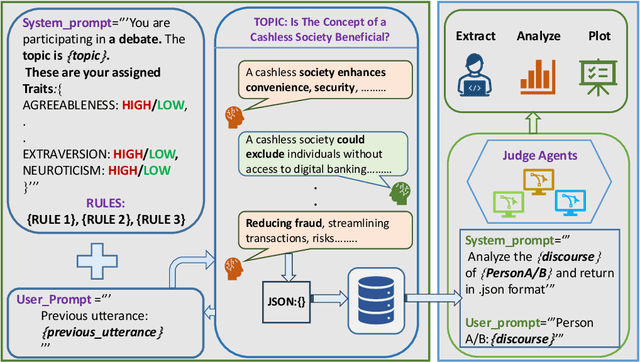
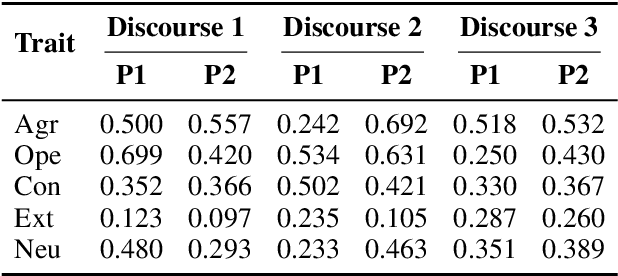
Large Language Models (LLMs) are widely used as conversational agents, exploiting their capabilities in various sectors such as education, law, medicine, and more. However, LLMs are often subjected to context-shifting behaviour, resulting in a lack of consistent and interpretable personality-aligned interactions. Adherence to psychological traits lacks comprehensive analysis, especially in the case of dyadic (pairwise) conversations. We examine this challenge from two viewpoints, initially using two conversation agents to generate a discourse on a certain topic with an assigned personality from the OCEAN framework (Openness, Conscientiousness, Extraversion, Agreeableness, and Neuroticism) as High/Low for each trait. This is followed by using multiple judge agents to infer the original traits assigned to explore prediction consistency, inter-model agreement, and alignment with the assigned personality. Our findings indicate that while LLMs can be guided toward personality-driven dialogue, their ability to maintain personality traits varies significantly depending on the combination of models and discourse settings. These inconsistencies emphasise the challenges in achieving stable and interpretable personality-aligned interactions in LLMs.
Evaluating Personality Traits in Large Language Models: Insights from Psychological Questionnaires
Feb 07, 2025



Psychological assessment tools have long helped humans understand behavioural patterns. While Large Language Models (LLMs) can generate content comparable to that of humans, we explore whether they exhibit personality traits. To this end, this work applies psychological tools to LLMs in diverse scenarios to generate personality profiles. Using established trait-based questionnaires such as the Big Five Inventory and by addressing the possibility of training data contamination, we examine the dimensional variability and dominance of LLMs across five core personality dimensions: Openness, Conscientiousness, Extraversion, Agreeableness, and Neuroticism. Our findings reveal that LLMs exhibit unique dominant traits, varying characteristics, and distinct personality profiles even within the same family of models.
Decoupled Sparse Priors Guided Diffusion Compression Model for Point Clouds
Nov 21, 2024



Lossy compression methods rely on an autoencoder to transform a point cloud into latent points for storage, leaving the inherent redundancy of latent representations unexplored. To reduce redundancy in latent points, we propose a sparse priors guided method that achieves high reconstruction quality, especially at high compression ratios. This is accomplished by a dual-density scheme separately processing the latent points (intended for reconstruction) and the decoupled sparse priors (intended for storage). Our approach features an efficient dual-density data flow that relaxes size constraints on latent points, and hybridizes a progressive conditional diffusion model to encapsulate essential details for reconstruction within the conditions, which are decoupled hierarchically to intra-point and inter-point priors. Specifically, our method encodes the original point cloud into latent points and decoupled sparse priors through separate encoders. Latent points serve as intermediates, while sparse priors act as adaptive conditions. We then employ a progressive attention-based conditional denoiser to generate latent points conditioned on the decoupled priors, allowing the denoiser to dynamically attend to geometric and semantic cues from the priors at each encoding and decoding layer. Additionally, we integrate the local distribution into the arithmetic encoder and decoder to enhance local context modeling of the sparse points. The original point cloud is reconstructed through a point decoder. Compared to state-of-the-art, our method obtains superior rate-distortion trade-off, evidenced by extensive evaluations on the ShapeNet dataset and standard test datasets from MPEG group including 8iVFB, and Owlii.
Context-Enhanced Video Moment Retrieval with Large Language Models
May 21, 2024Current methods for Video Moment Retrieval (VMR) struggle to align complex situations involving specific environmental details, character descriptions, and action narratives. To tackle this issue, we propose a Large Language Model-guided Moment Retrieval (LMR) approach that employs the extensive knowledge of Large Language Models (LLMs) to improve video context representation as well as cross-modal alignment, facilitating accurate localization of target moments. Specifically, LMR introduces a context enhancement technique with LLMs to generate crucial target-related context semantics. These semantics are integrated with visual features for producing discriminative video representations. Finally, a language-conditioned transformer is designed to decode free-form language queries, on the fly, using aligned video representations for moment retrieval. Extensive experiments demonstrate that LMR achieves state-of-the-art results, outperforming the nearest competitor by up to 3.28\% and 4.06\% on the challenging QVHighlights and Charades-STA benchmarks, respectively. More importantly, the performance gains are significantly higher for localization of complex queries.
Gathering Cyber Threat Intelligence from Twitter Using Novelty Classification
Jul 03, 2019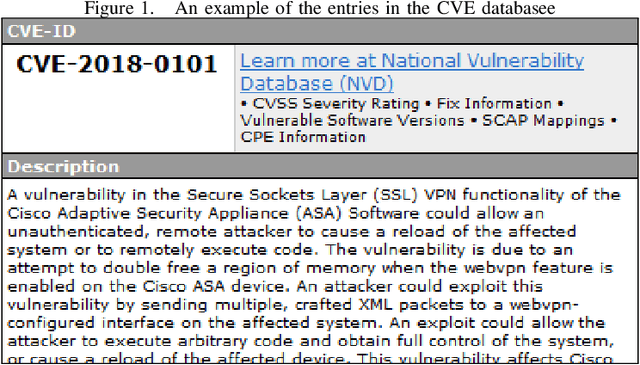
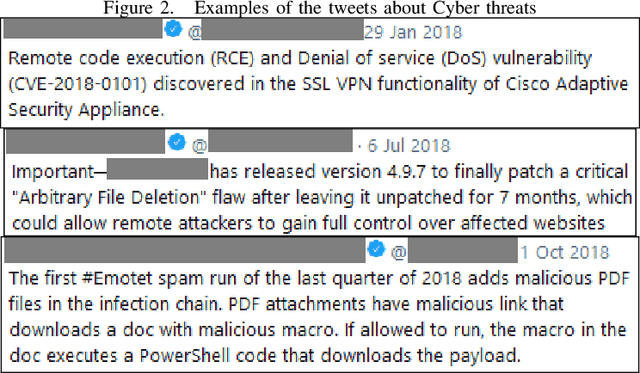

Preventing organizations from Cyber exploits needs timely intelligence about Cyber vulnerabilities and attacks, referred as threats. Cyber threat intelligence can be extracted from various sources including social media platforms where users publish the threat information in real time. Gathering Cyber threat intelligence from social media sites is a time consuming task for security analysts that can delay timely response to emerging Cyber threats. We propose a framework for automatically gathering Cyber threat intelligence from Twitter by using a novelty detection model. Our model learns the features of Cyber threat intelligence from the threat descriptions published in public repositories such as Common Vulnerabilities and Exposures (CVE) and classifies a new unseen tweet as either normal or anomalous to Cyber threat intelligence. We evaluate our framework using a purpose-built data set of tweets from 50 influential Cyber security related accounts over twelve months (in 2018). Our classifier achieves the F1-score of 0.643 for classifying Cyber threat tweets and outperforms several baselines including binary classification models. Our analysis of the classification results suggests that Cyber threat relevant tweets on Twitter do not often include the CVE identifier of the related threats. Hence, it would be valuable to collect these tweets and associate them with the related CVE identifier for cyber security applications.
Pachinko Prediction: A Bayesian method for event prediction from social media data
Sep 22, 2018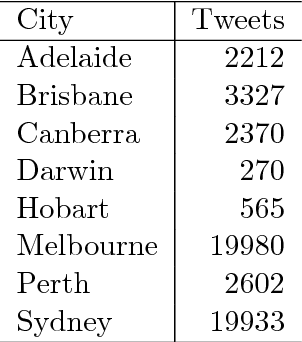
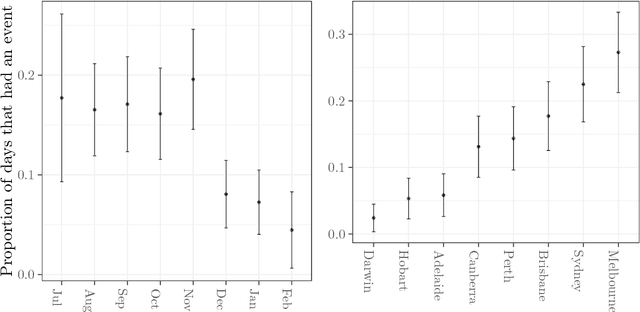
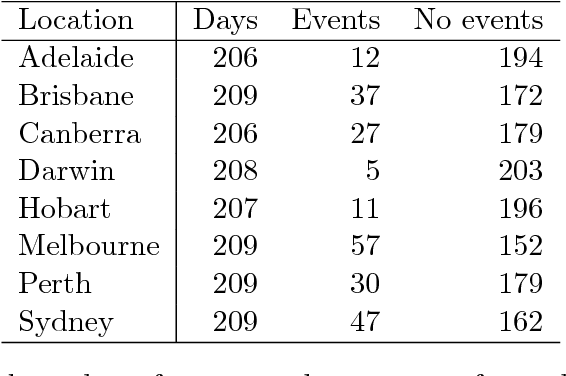
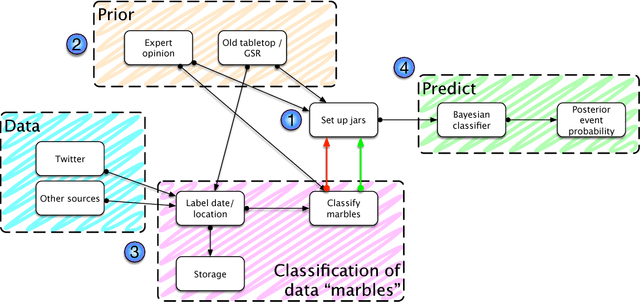
The combination of large open data sources with machine learning approaches presents a potentially powerful way to predict events such as protest or social unrest. However, accounting for uncertainty in such models, particularly when using diverse, unstructured datasets such as social media, is essential to guarantee the appropriate use of such methods. Here we develop a Bayesian method for predicting social unrest events in Australia using social media data. This method uses machine learning methods to classify individual postings to social media as being relevant, and an empirical Bayesian approach to calculate posterior event probabilities. We use the method to predict events in Australian cities over a period in 2017/18.