 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBest Preprocessing Techniques for Sentiment Analysis
Jun 23, 2026Sentiment analysis in Twitter datasets is important because it enables monitoring public opinion on products and analysis of political and social movements. One critical step is preprocessing: the automated processing of text for machine learning algorithms. Preprocessing plays a critical role in reducing noise and improving efficiency. However, little research has systematically examined the order in which preprocessing techniques are implemented. We find that, when accounting for order, spelling correction is the least impactful preprocessing technique, whereas tokenisation is the most impactful. Stemming and stop-word removal are interchangeable, and it is better to remove stop words without removing negation. The best order for applying the preprocessing techniques was tokenisation, text cleaning, stemming, and then stopword removal. Our results provide a systematic approach for practitioners to deploy preprocessing to improve model output without the costly preprocessing exploratory phase.
Quantifying consistency and accuracy of Latent Dirichlet Allocation
Nov 17, 2025

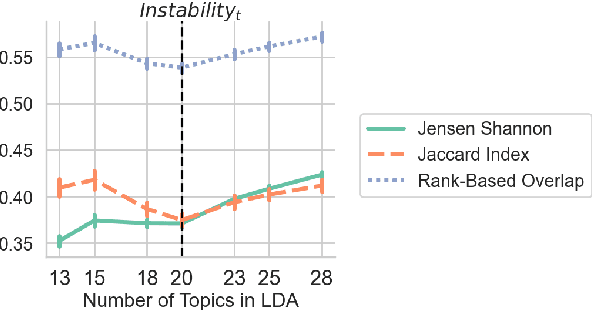
Topic modelling in Natural Language Processing uncovers hidden topics in large, unlabelled text datasets. It is widely applied in fields such as information retrieval, content summarisation, and trend analysis across various disciplines. However, probabilistic topic models can produce different results when rerun due to their stochastic nature, leading to inconsistencies in latent topics. Factors like corpus shuffling, rare text removal, and document elimination contribute to these variations. This instability affects replicability, reliability, and interpretation, raising concerns about whether topic models capture meaningful topics or just noise. To address these problems, we defined a new stability measure that incorporates accuracy and consistency and uses the generative properties of LDA to generate a new corpus with ground truth. These generated corpora are run through LDA 50 times to determine the variability in the output. We show that LDA can correctly determine the underlying number of topics in the documents. We also find that LDA is more internally consistent, as the multiple reruns return similar topics; however, these topics are not the true topics.
Probabilistic emotion and sentiment modelling of patient-reported experiences
Jan 09, 2024This study introduces a novel methodology for modelling patient emotions from online patient experience narratives. We employed metadata network topic modelling to analyse patient-reported experiences from Care Opinion, revealing key emotional themes linked to patient-caregiver interactions and clinical outcomes. We develop a probabilistic, context-specific emotion recommender system capable of predicting both multilabel emotions and binary sentiments using a naive Bayes classifier using contextually meaningful topics as predictors. The superior performance of our predicted emotions under this model compared to baseline models was assessed using the information retrieval metrics nDCG and Q-measure, and our predicted sentiments achieved an F1 score of 0.921, significantly outperforming standard sentiment lexicons. This method offers a transparent, cost-effective way to understand patient feedback, enhancing traditional collection methods and informing individualised patient care. Our findings are accessible via an R package and interactive dashboard, providing valuable tools for healthcare researchers and practitioners.
Personality Profiling: How informative are social media profiles in predicting personal information?
Sep 15, 2023Personality profiling has been utilised by companies for targeted advertising, political campaigns and vaccine campaigns. However, the accuracy and versatility of such models still remains relatively unknown. Consequently, we aim to explore the extent to which peoples' online digital footprints can be used to profile their Myers-Briggs personality type. We analyse and compare the results of four models: logistic regression, naive Bayes, support vector machines (SVMs) and random forests. We discover that a SVM model achieves the best accuracy of 20.95% for predicting someones complete personality type. However, logistic regression models perform only marginally worse and are significantly faster to train and perform predictions. We discover that many labelled datasets present substantial class imbalances of personal characteristics on social media, including our own. As a result, we highlight the need for attentive consideration when reporting model performance on these datasets and compare a number of methods for fixing the class-imbalance problems. Moreover, we develop a statistical framework for assessing the importance of different sets of features in our models. We discover some features to be more informative than others in the Intuitive/Sensory (p = 0.032) and Thinking/Feeling (p = 0.019) models. While we apply these methods to Myers-Briggs personality profiling, they could be more generally used for any labelling of individuals on social media.
Revealing Patient-Reported Experiences in Healthcare from Social Media using the DAPMAV Framework
Oct 09, 2022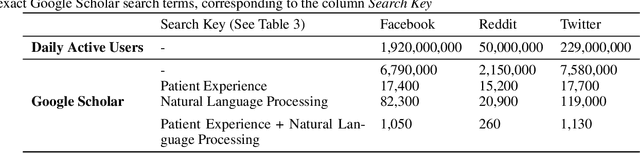
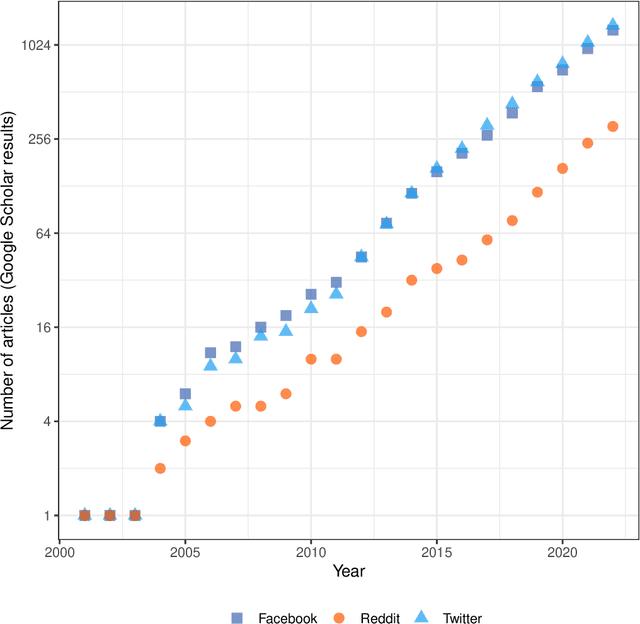
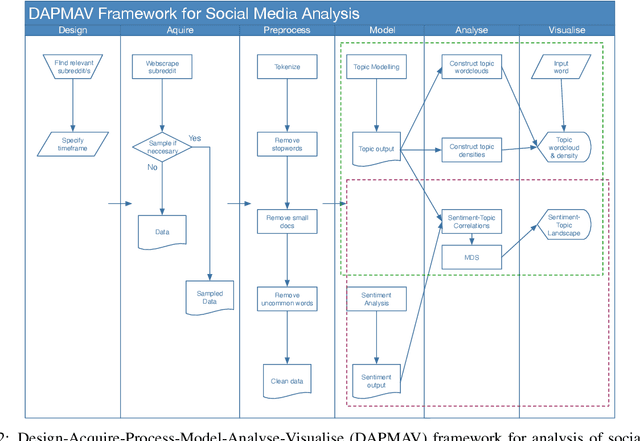
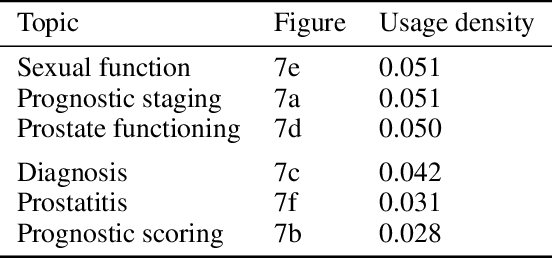
Understanding patient experience in healthcare is increasingly important and desired by medical professionals in a patient-centred care approach. Healthcare discourse on social media presents an opportunity to gain a unique perspective on patient-reported experiences, complementing traditional survey data. These social media reports often appear as first-hand accounts of patients' journeys through the healthcare system, whose details extend beyond the confines of structured surveys and at a far larger scale than focus groups. However, in contrast with the vast presence of patient-experience data on social media and the potential benefits the data offers, it attracts comparatively little research attention due to the technical proficiency required for text analysis. In this paper, we introduce the Design-Acquire-Process-Model-Analyse-Visualise (DAPMAV) framework to equip non-technical domain experts with a structured approach that will enable them to capture patient-reported experiences from social media data. We apply this framework in a case study on prostate cancer data from /r/ProstateCancer, demonstrate the framework's value in capturing specific aspects of patient concern (such as sexual dysfunction), provide an overview of the discourse, and show narrative and emotional progression through these stories. We anticipate this framework to apply to a wide variety of areas in healthcare, including capturing and differentiating experiences across minority groups, geographic boundaries, and types of illnesses.
Symptom extraction from the narratives of personal experiences with COVID-19 on Reddit
May 21, 2020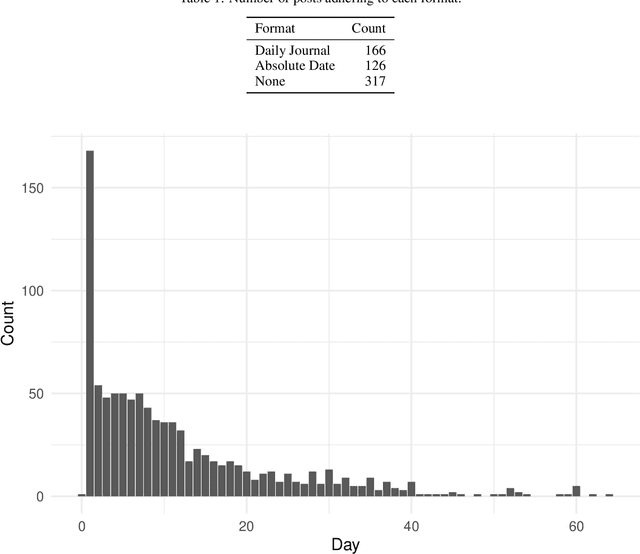
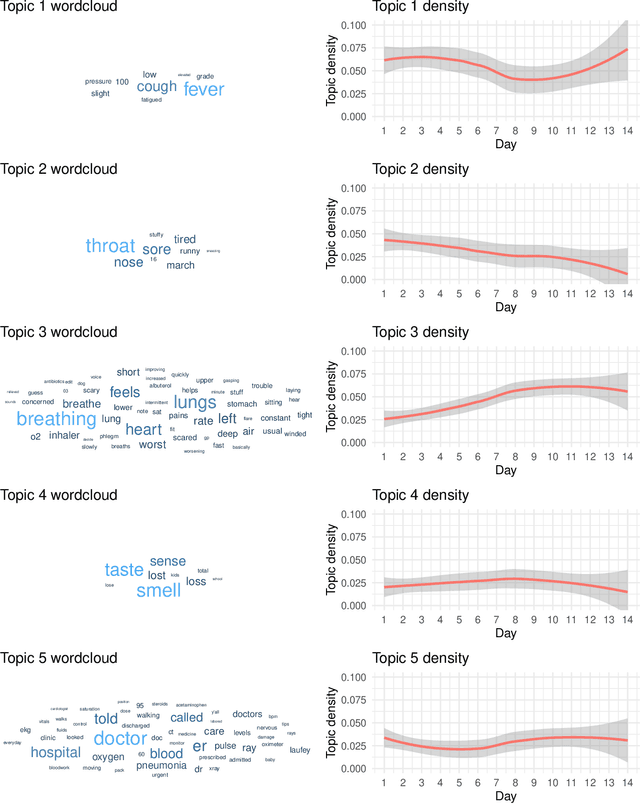

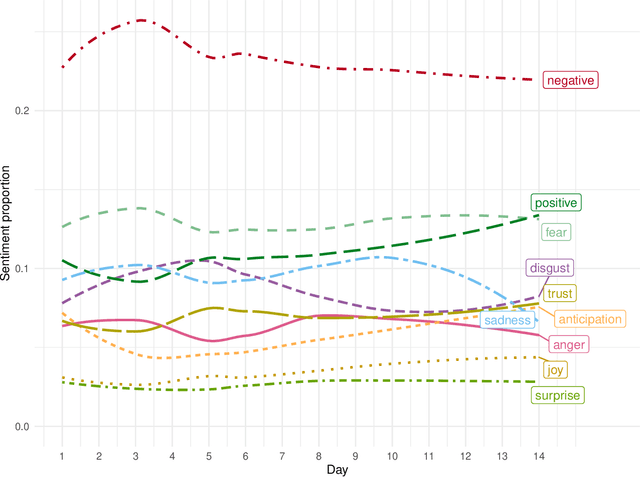
Social media discussion of COVID-19 provides a rich source of information into how the virus affects people's lives that is qualitatively different from traditional public health datasets. In particular, when individuals self-report their experiences over the course of the virus on social media, it can allow for identification of the emotions each stage of symptoms engenders in the patient. Posts to the Reddit forum r/COVID19Positive contain first-hand accounts from COVID-19 positive patients, giving insight into personal struggles with the virus. These posts often feature a temporal structure indicating the number of days after developing symptoms the text refers to. Using topic modelling and sentiment analysis, we quantify the change in discussion of COVID-19 throughout individuals' experiences for the first 14 days since symptom onset. Discourse on early symptoms such as fever, cough, and sore throat was concentrated towards the beginning of the posts, while language indicating breathing issues peaked around ten days. Some conversation around critical cases was also identified and appeared at a roughly constant rate. We identified two clear clusters of positive and negative emotions associated with the evolution of these symptoms and mapped their relationships. Our results provide a perspective on the patient experience of COVID-19 that complements other medical data streams and can potentially reveal when mental health issues might appear.
A framework for streamlined statistical prediction using topic models
Apr 15, 2019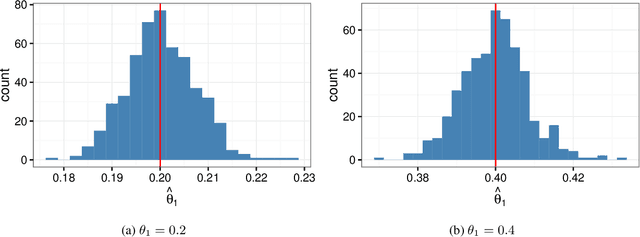
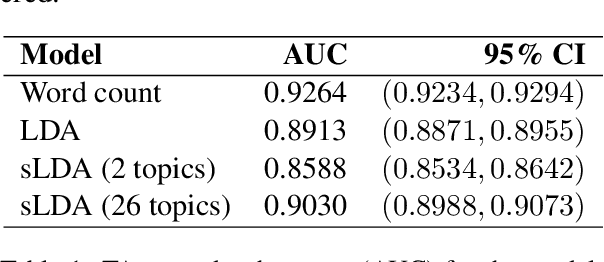
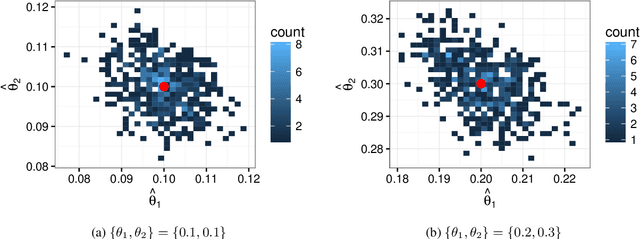
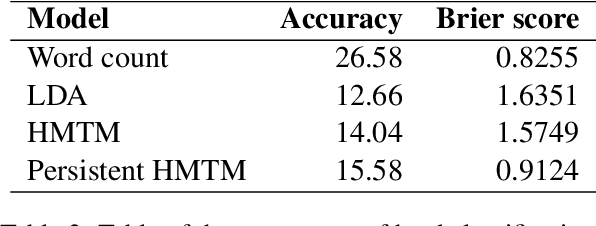
In the Humanities and Social Sciences, there is increasing interest in approaches to information extraction, prediction, intelligent linkage, and dimension reduction applicable to large text corpora. With approaches in these fields being grounded in traditional statistical techniques, the need arises for frameworks whereby advanced NLP techniques such as topic modelling may be incorporated within classical methodologies. This paper provides a classical, supervised, statistical learning framework for prediction from text, using topic models as a data reduction method and the topics themselves as predictors, alongside typical statistical tools for predictive modelling. We apply this framework in a Social Sciences context (applied animal behaviour) as well as a Humanities context (narrative analysis) as examples of this framework. The results show that topic regression models perform comparably to their much less efficient equivalents that use individual words as predictors.
Pachinko Prediction: A Bayesian method for event prediction from social media data
Sep 22, 2018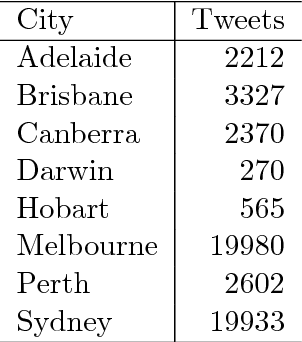
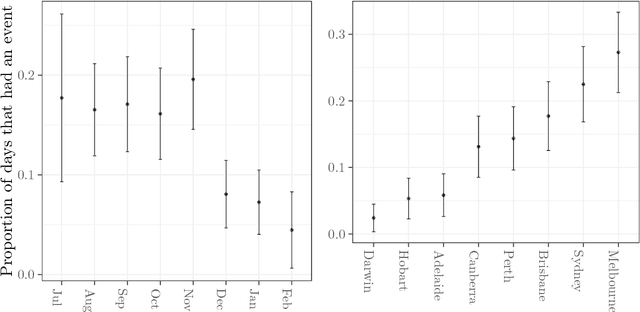
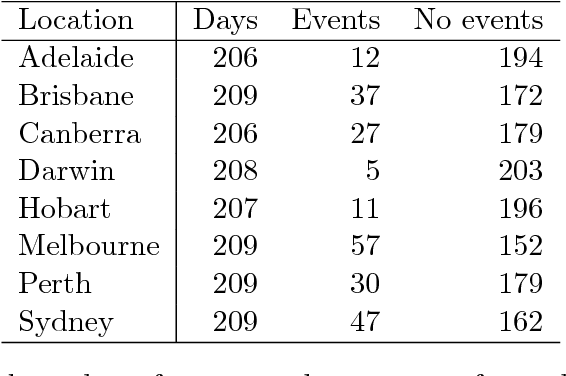
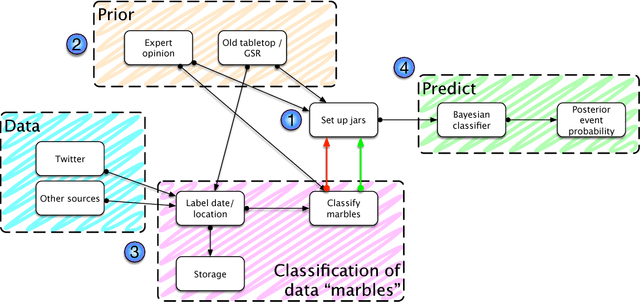
The combination of large open data sources with machine learning approaches presents a potentially powerful way to predict events such as protest or social unrest. However, accounting for uncertainty in such models, particularly when using diverse, unstructured datasets such as social media, is essential to guarantee the appropriate use of such methods. Here we develop a Bayesian method for predicting social unrest events in Australia using social media data. This method uses machine learning methods to classify individual postings to social media as being relevant, and an empirical Bayesian approach to calculate posterior event probabilities. We use the method to predict events in Australian cities over a period in 2017/18.