 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying consistency and accuracy of Latent Dirichlet Allocation
Nov 17, 2025

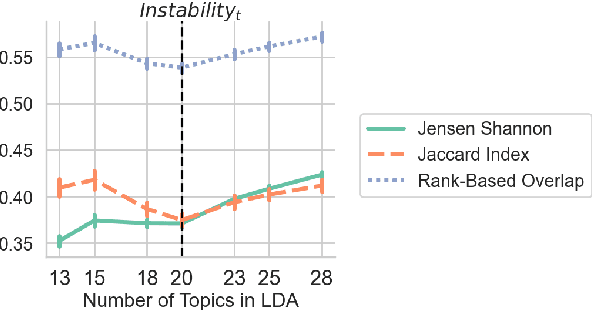
Topic modelling in Natural Language Processing uncovers hidden topics in large, unlabelled text datasets. It is widely applied in fields such as information retrieval, content summarisation, and trend analysis across various disciplines. However, probabilistic topic models can produce different results when rerun due to their stochastic nature, leading to inconsistencies in latent topics. Factors like corpus shuffling, rare text removal, and document elimination contribute to these variations. This instability affects replicability, reliability, and interpretation, raising concerns about whether topic models capture meaningful topics or just noise. To address these problems, we defined a new stability measure that incorporates accuracy and consistency and uses the generative properties of LDA to generate a new corpus with ground truth. These generated corpora are run through LDA 50 times to determine the variability in the output. We show that LDA can correctly determine the underlying number of topics in the documents. We also find that LDA is more internally consistent, as the multiple reruns return similar topics; however, these topics are not the true topics.
Data Denoising and Derivative Estimation for Data-Driven Modeling of Nonlinear Dynamical Systems
Sep 17, 2025Data-driven modeling of nonlinear dynamical systems is often hampered by measurement noise. We propose a denoising framework, called Runge-Kutta and Total Variation Based Implicit Neural Representation (RKTV-INR), that represents the state trajectory with an implicit neural representation (INR) fitted directly to noisy observations. Runge-Kutta integration and total variation are imposed as constraints to ensure that the reconstructed state is a trajectory of a dynamical system that remains close to the original data. The trained INR yields a clean, continuous trajectory and provides accurate first-order derivatives via automatic differentiation. These denoised states and derivatives are then supplied to Sparse Identification of Nonlinear Dynamics (SINDy) to recover the governing equations. Experiments demonstrate effective noise suppression, precise derivative estimation, and reliable system identification.
Hierarchical Representations for Evolving Acyclic Vector Autoregressions (HEAVe)
May 19, 2025Causal networks offer an intuitive framework to understand influence structures within time series systems. However, the presence of cycles can obscure dynamic relationships and hinder hierarchical analysis. These networks are typically identified through multivariate predictive modelling, but enforcing acyclic constraints significantly increases computational and analytical complexity. Despite recent advances, there remains a lack of simple, flexible approaches that are easily tailorable to specific problem instances. We propose an evolutionary approach to fitting acyclic vector autoregressive processes and introduces a novel hierarchical representation that directly models structural elements within a time series system. On simulated datasets, our model retains most of the predictive accuracy of unconstrained models and outperforms permutation-based alternatives. When applied to a dataset of 100 cryptocurrency return series, our method generates acyclic causal networks capturing key structural properties of the unconstrained model. The acyclic networks are approximately sub-graphs of the unconstrained networks, and most of the removed links originate from low-influence nodes. Given the high levels of feature preservation, we conclude that this cryptocurrency price system functions largely hierarchically. Our findings demonstrate a flexible, intuitive approach for identifying hierarchical causal networks in time series systems, with broad applications to fields like econometrics and social network analysis.
Modified CMA-ES Algorithm for Multi-Modal Optimization: Incorporating Niching Strategies and Dynamic Adaptation Mechanism
Jul 01, 2024This study modifies the Covariance Matrix Adaptation Evolution Strategy (CMA-ES) algorithm for multi-modal optimization problems. The enhancements focus on addressing the challenges of multiple global minima, improving the algorithm's ability to maintain diversity and explore complex fitness landscapes. We incorporate niching strategies and dynamic adaptation mechanisms to refine the algorithm's performance in identifying and optimizing multiple global optima. The algorithm generates a population of candidate solutions by sampling from a multivariate normal distribution centered around the current mean vector, with the spread determined by the step size and covariance matrix. Each solution's fitness is evaluated as a weighted sum of its contributions to all global minima, maintaining population diversity and preventing premature convergence. We implemented the algorithm on 8 tunable composite functions for the GECCO 2024 Competition on Benchmarking Niching Methods for Multi-Modal Optimization (MMO), adhering to the competition's benchmarking framework. The results are presenting in many ways such as Peak Ratio, F1 score on various dimensions. They demonstrate the algorithm's robustness and effectiveness in handling both global optimization and MMO- specific challenges, providing a comprehensive solution for complex multi-modal optimization problems.
Orthogonally Initiated Particle Swarm Optimization with Advanced Mutation for Real-Parameter Optimization
May 21, 2024

This article introduces an enhanced particle swarm optimizer (PSO), termed Orthogonal PSO with Mutation (OPSO-m). Initially, it proposes an orthogonal array-based learning approach to cultivate an improved initial swarm for PSO, significantly boosting the adaptability of swarm-based optimization algorithms. The article further presents archive-based self-adaptive learning strategies, dividing the population into regular and elite subgroups. Each subgroup employs distinct learning mechanisms. The regular group utilizes efficient learning schemes derived from three unique archives, which categorize individuals based on their quality levels. Additionally, a mutation strategy is implemented to update the positions of elite individuals. Comparative studies are conducted to assess the effectiveness of these learning strategies in OPSO-m, evaluating its optimization capacity through exploration-exploitation dynamics and population diversity analysis. The proposed OPSO-m model is tested on real-parameter challenges from the CEC 2017 suite in 10, 30, 50, and 100-dimensional search spaces, with its results compared to contemporary state-of-the-art algorithms using a sensitivity metric. OPSO-m exhibits distinguished performance in the precision of solutions, rapidity of convergence, efficiency in search, and robust stability, thus highlighting its superior aptitude for resolving intricate optimization issues.
Probabilistic emotion and sentiment modelling of patient-reported experiences
Jan 09, 2024This study introduces a novel methodology for modelling patient emotions from online patient experience narratives. We employed metadata network topic modelling to analyse patient-reported experiences from Care Opinion, revealing key emotional themes linked to patient-caregiver interactions and clinical outcomes. We develop a probabilistic, context-specific emotion recommender system capable of predicting both multilabel emotions and binary sentiments using a naive Bayes classifier using contextually meaningful topics as predictors. The superior performance of our predicted emotions under this model compared to baseline models was assessed using the information retrieval metrics nDCG and Q-measure, and our predicted sentiments achieved an F1 score of 0.921, significantly outperforming standard sentiment lexicons. This method offers a transparent, cost-effective way to understand patient feedback, enhancing traditional collection methods and informing individualised patient care. Our findings are accessible via an R package and interactive dashboard, providing valuable tools for healthcare researchers and practitioners.
Personality Profiling: How informative are social media profiles in predicting personal information?
Sep 15, 2023Personality profiling has been utilised by companies for targeted advertising, political campaigns and vaccine campaigns. However, the accuracy and versatility of such models still remains relatively unknown. Consequently, we aim to explore the extent to which peoples' online digital footprints can be used to profile their Myers-Briggs personality type. We analyse and compare the results of four models: logistic regression, naive Bayes, support vector machines (SVMs) and random forests. We discover that a SVM model achieves the best accuracy of 20.95% for predicting someones complete personality type. However, logistic regression models perform only marginally worse and are significantly faster to train and perform predictions. We discover that many labelled datasets present substantial class imbalances of personal characteristics on social media, including our own. As a result, we highlight the need for attentive consideration when reporting model performance on these datasets and compare a number of methods for fixing the class-imbalance problems. Moreover, we develop a statistical framework for assessing the importance of different sets of features in our models. We discover some features to be more informative than others in the Intuitive/Sensory (p = 0.032) and Thinking/Feeling (p = 0.019) models. While we apply these methods to Myers-Briggs personality profiling, they could be more generally used for any labelling of individuals on social media.
Revealing Patient-Reported Experiences in Healthcare from Social Media using the DAPMAV Framework
Oct 09, 2022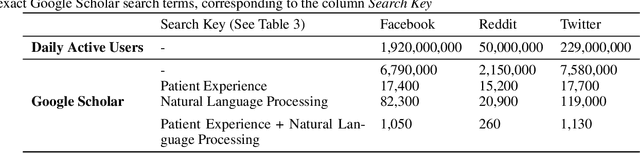
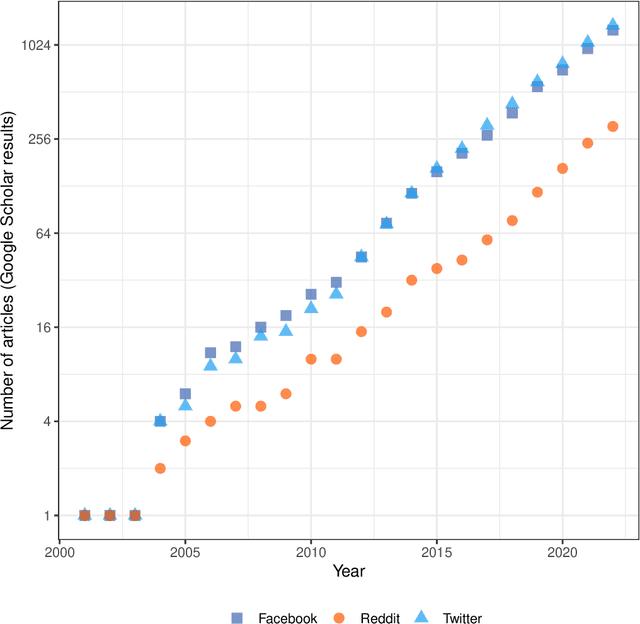
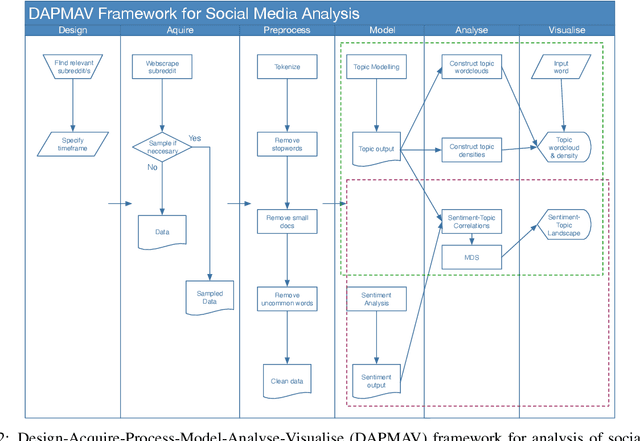
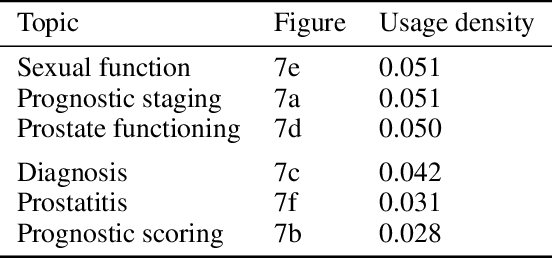
Understanding patient experience in healthcare is increasingly important and desired by medical professionals in a patient-centred care approach. Healthcare discourse on social media presents an opportunity to gain a unique perspective on patient-reported experiences, complementing traditional survey data. These social media reports often appear as first-hand accounts of patients' journeys through the healthcare system, whose details extend beyond the confines of structured surveys and at a far larger scale than focus groups. However, in contrast with the vast presence of patient-experience data on social media and the potential benefits the data offers, it attracts comparatively little research attention due to the technical proficiency required for text analysis. In this paper, we introduce the Design-Acquire-Process-Model-Analyse-Visualise (DAPMAV) framework to equip non-technical domain experts with a structured approach that will enable them to capture patient-reported experiences from social media data. We apply this framework in a case study on prostate cancer data from /r/ProstateCancer, demonstrate the framework's value in capturing specific aspects of patient concern (such as sexual dysfunction), provide an overview of the discourse, and show narrative and emotional progression through these stories. We anticipate this framework to apply to a wide variety of areas in healthcare, including capturing and differentiating experiences across minority groups, geographic boundaries, and types of illnesses.
Generalized Word Shift Graphs: A Method for Visualizing and Explaining Pairwise Comparisons Between Texts
Aug 05, 2020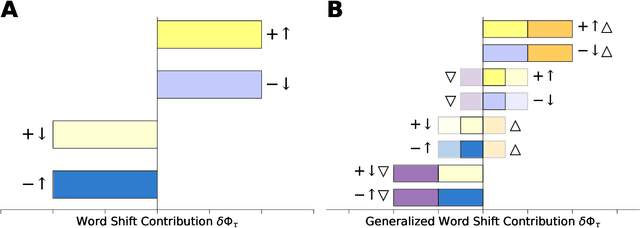
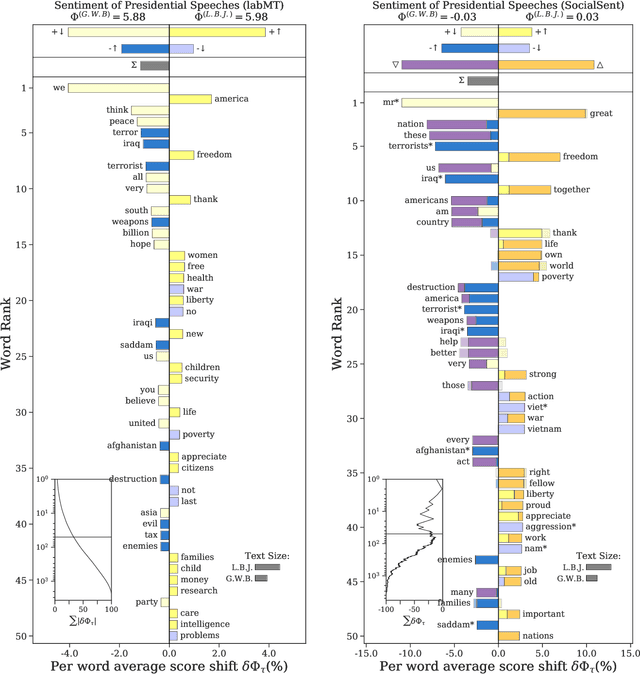
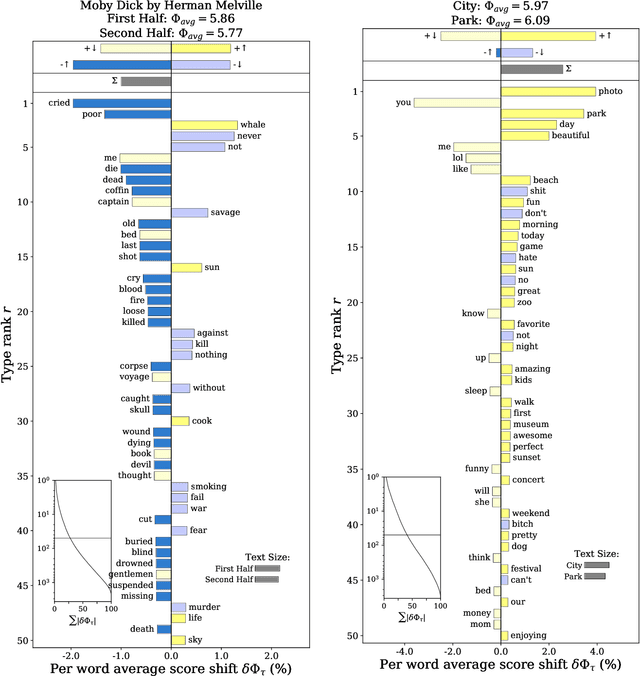
A common task in computational text analyses is to quantify how two corpora differ according to a measurement like word frequency, sentiment, or information content. However, collapsing the texts' rich stories into a single number is often conceptually perilous, and it is difficult to confidently interpret interesting or unexpected textual patterns without looming concerns about data artifacts or measurement validity. To better capture fine-grained differences between texts, we introduce generalized word shift graphs, visualizations which yield a meaningful and interpretable summary of how individual words contribute to the variation between two texts for any measure that can be formulated as a weighted average. We show that this framework naturally encompasses many of the most commonly used approaches for comparing texts, including relative frequencies, dictionary scores, and entropy-based measures like the Kullback-Leibler and Jensen-Shannon divergences. Through several case studies, we demonstrate how generalized word shift graphs can be flexibly applied across domains for diagnostic investigation, hypothesis generation, and substantive interpretation. By providing a detailed lens into textual shifts between corpora, generalized word shift graphs help computational social scientists, digital humanists, and other text analysis practitioners fashion more robust scientific narratives.
Symptom extraction from the narratives of personal experiences with COVID-19 on Reddit
May 21, 2020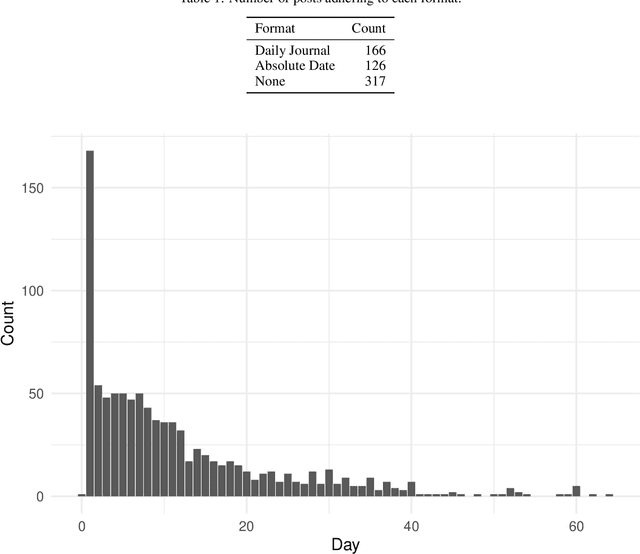
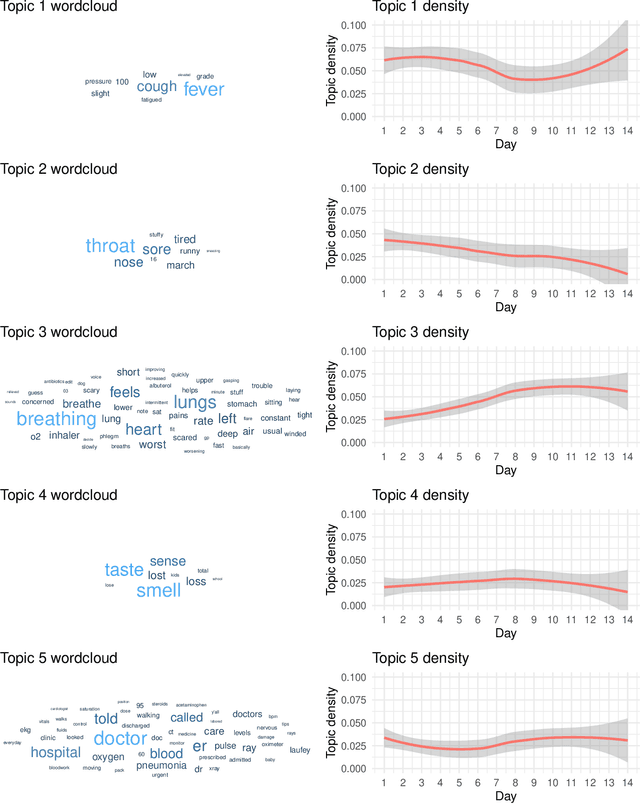

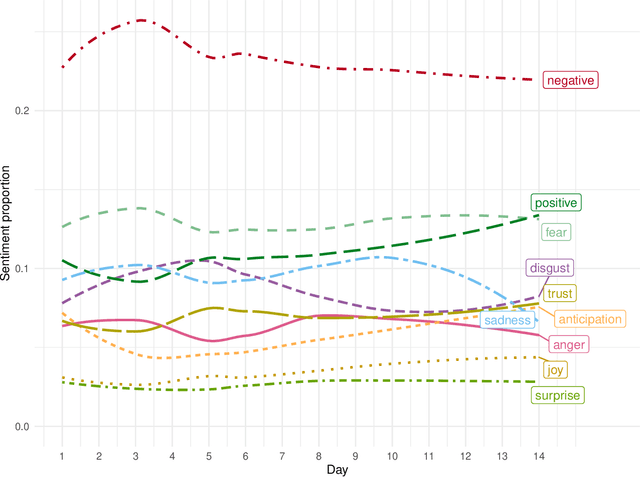
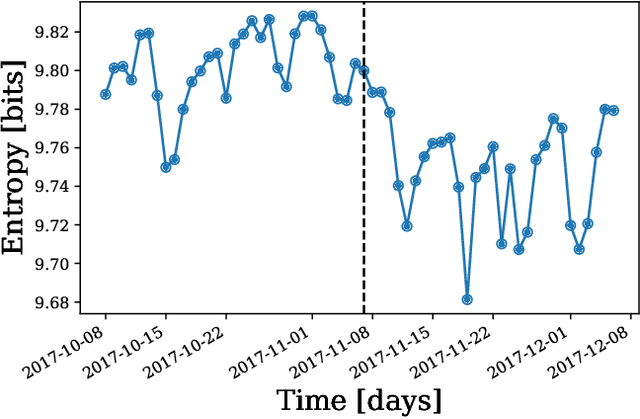
Social media discussion of COVID-19 provides a rich source of information into how the virus affects people's lives that is qualitatively different from traditional public health datasets. In particular, when individuals self-report their experiences over the course of the virus on social media, it can allow for identification of the emotions each stage of symptoms engenders in the patient. Posts to the Reddit forum r/COVID19Positive contain first-hand accounts from COVID-19 positive patients, giving insight into personal struggles with the virus. These posts often feature a temporal structure indicating the number of days after developing symptoms the text refers to. Using topic modelling and sentiment analysis, we quantify the change in discussion of COVID-19 throughout individuals' experiences for the first 14 days since symptom onset. Discourse on early symptoms such as fever, cough, and sore throat was concentrated towards the beginning of the posts, while language indicating breathing issues peaked around ten days. Some conversation around critical cases was also identified and appeared at a roughly constant rate. We identified two clear clusters of positive and negative emotions associated with the evolution of these symptoms and mapped their relationships. Our results provide a perspective on the patient experience of COVID-19 that complements other medical data streams and can potentially reveal when mental health issues might appear.