 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Word Shift Graphs: A Method for Visualizing and Explaining Pairwise Comparisons Between Texts
Aug 05, 2020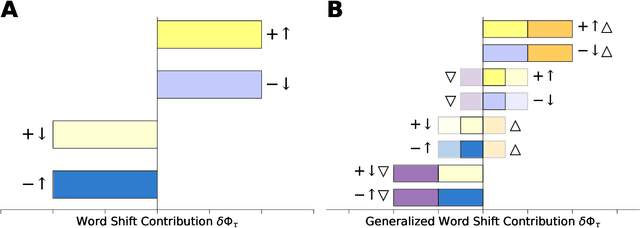
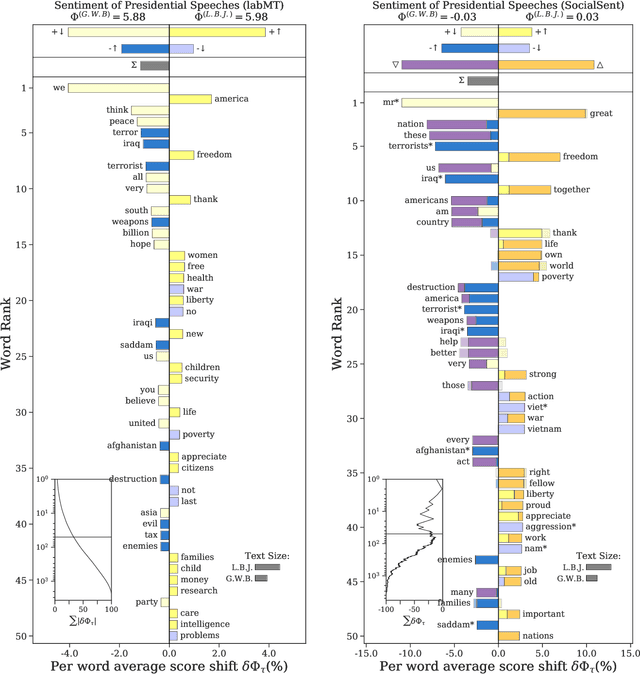
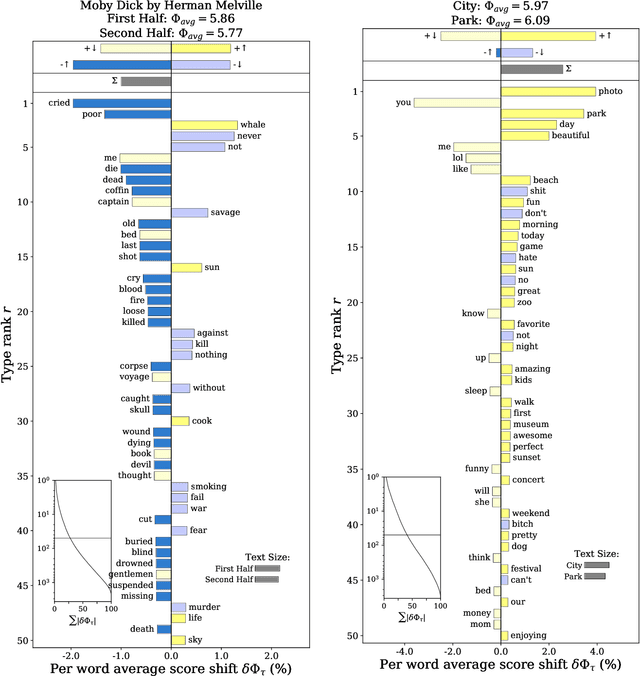
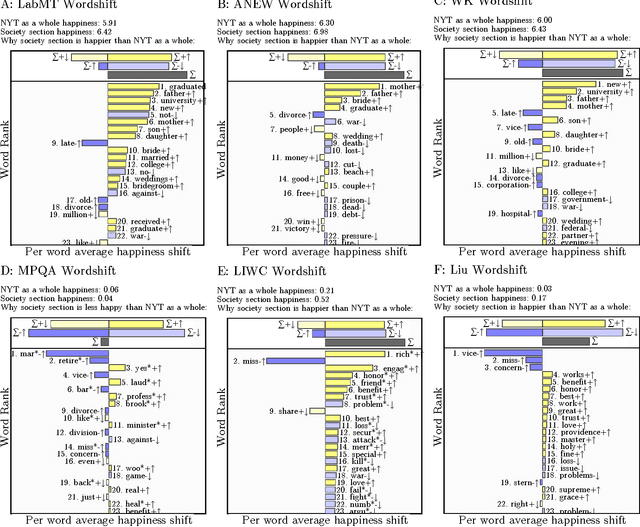
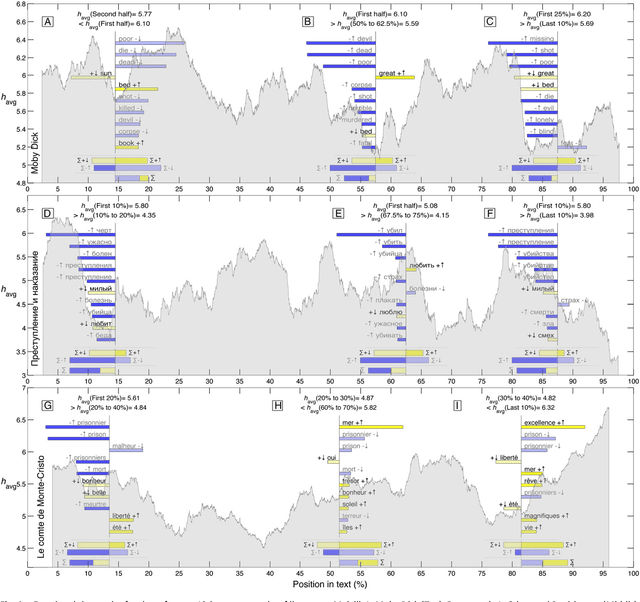
A common task in computational text analyses is to quantify how two corpora differ according to a measurement like word frequency, sentiment, or information content. However, collapsing the texts' rich stories into a single number is often conceptually perilous, and it is difficult to confidently interpret interesting or unexpected textual patterns without looming concerns about data artifacts or measurement validity. To better capture fine-grained differences between texts, we introduce generalized word shift graphs, visualizations which yield a meaningful and interpretable summary of how individual words contribute to the variation between two texts for any measure that can be formulated as a weighted average. We show that this framework naturally encompasses many of the most commonly used approaches for comparing texts, including relative frequencies, dictionary scores, and entropy-based measures like the Kullback-Leibler and Jensen-Shannon divergences. Through several case studies, we demonstrate how generalized word shift graphs can be flexibly applied across domains for diagnostic investigation, hypothesis generation, and substantive interpretation. By providing a detailed lens into textual shifts between corpora, generalized word shift graphs help computational social scientists, digital humanists, and other text analysis practitioners fashion more robust scientific narratives.
Storywrangler: A massive exploratorium for sociolinguistic, cultural, socioeconomic, and political timelines using Twitter
Jul 25, 2020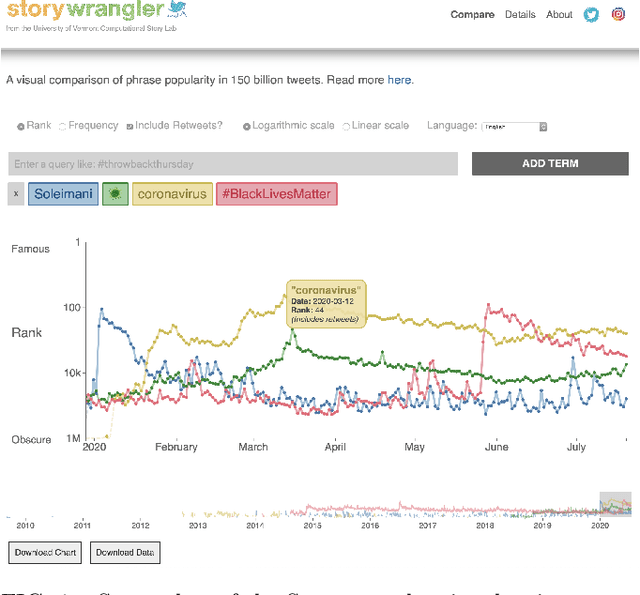
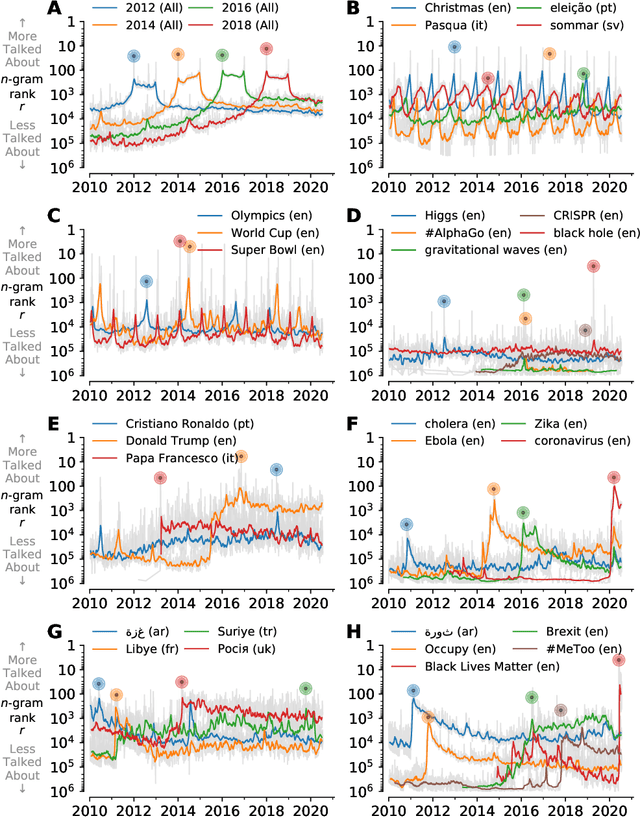
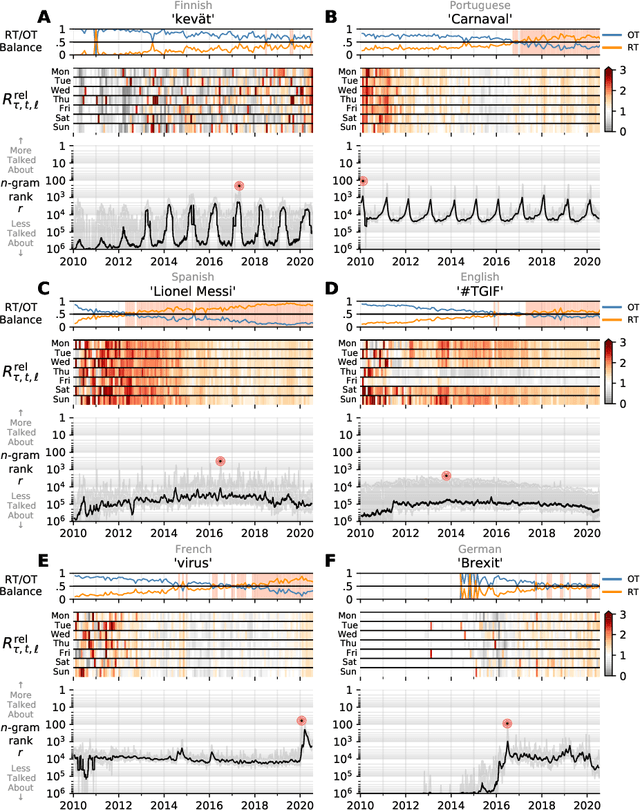
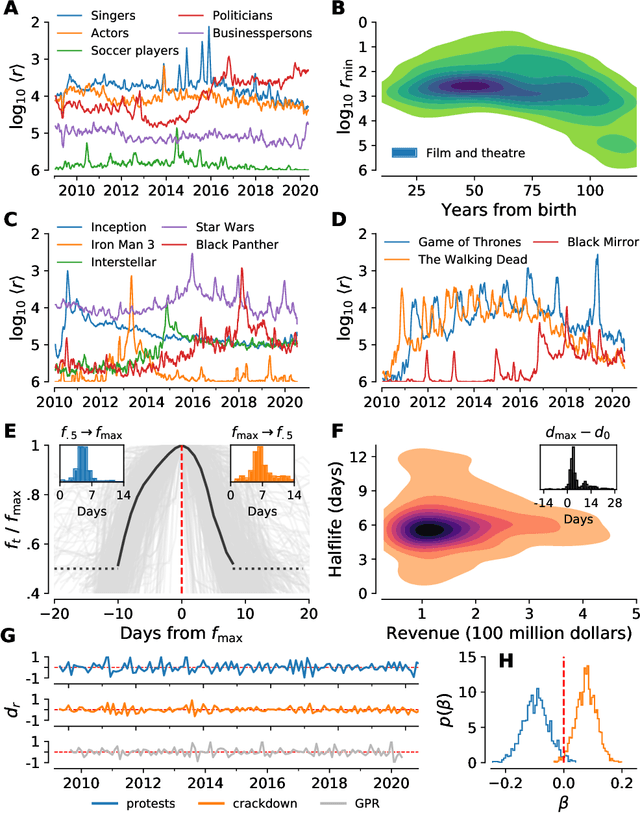
In real-time, Twitter strongly imprints world events, popular culture, and the day-to-day; Twitter records an ever growing compendium of language use and change; and Twitter has been shown to enable certain kinds of prediction. Vitally, and absent from many standard corpora such as books and news archives, Twitter also encodes popularity and spreading through retweets. Here, we describe Storywrangler, an ongoing, day-scale curation of over 100 billion tweets containing around 1 trillion 1-grams from 2008 to 2020. For each day, we break tweets into 1-, 2-, and 3-grams across 150+ languages, record usage frequencies, and generate Zipf distributions. We make the data set available through an interactive time series viewer, and as downloadable time series and daily distributions. We showcase a few examples of the many possible avenues of study we aim to enable including how social amplification can be visualized through 'contagiograms'.
English verb regularization in books and tweets
Mar 26, 2018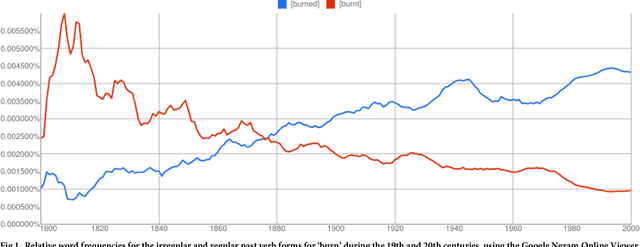
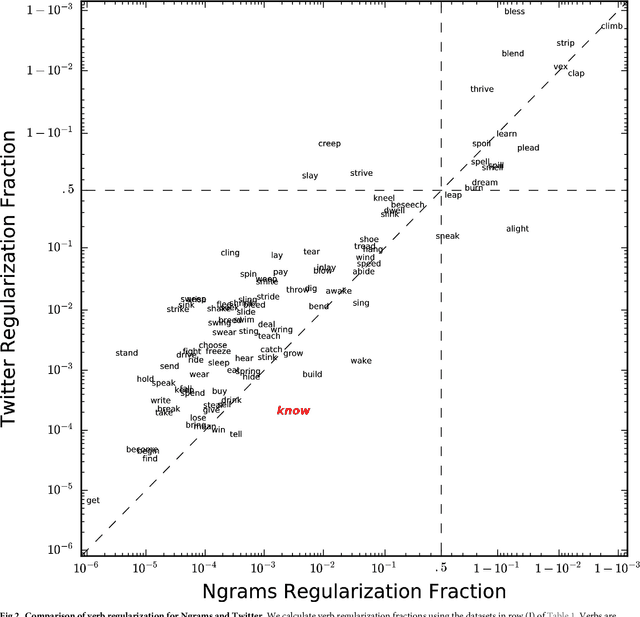

The English language has evolved dramatically throughout its lifespan, to the extent that a modern speaker of Old English would be incomprehensible without translation. One concrete indicator of this process is the movement from irregular to regular (-ed) forms for the past tense of verbs. In this study we quantify the extent of verb regularization using two vastly disparate datasets: (1) Six years of published books scanned by Google (2003--2008), and (2) A decade of social media messages posted to Twitter (2008--2017). We find that the extent of verb regularization is greater on Twitter, taken as a whole, than in English Fiction books. Regularization is also greater for tweets geotagged in the United States relative to American English books, but the opposite is true for tweets geotagged in the United Kingdom relative to British English books. We also find interesting regional variations in regularization across counties in the United States. However, once differences in population are accounted for, we do not identify strong correlations with socio-demographic variables such as education or income.
Towards a science of human stories: using sentiment analysis and emotional arcs to understand the building blocks of complex social systems
Dec 17, 2017

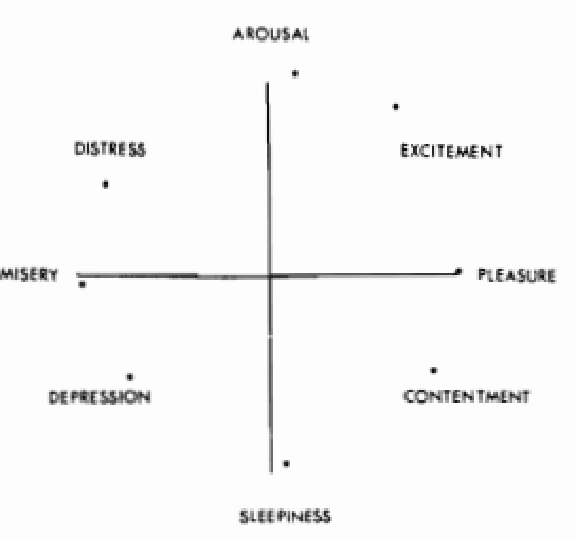
Given the growing assortment of sentiment measuring instruments, it is imperative to understand which aspects of sentiment dictionaries contribute to both their classification accuracy and their ability to provide richer understanding of texts. Here, we perform detailed, quantitative tests and qualitative assessments of 6 dictionary-based methods applied, and briefly examine a further 20 methods. We show that while inappropriate for sentences, dictionary-based methods are generally robust in their classification accuracy for longer texts. Stories often following distinct emotional trajectories, forming patterns that are meaningful to us. By classifying the emotional arcs for a filtered subset of 4,803 stories from Project Gutenberg's fiction collection, we find a set of six core trajectories which form the building blocks of complex narratives. Of profound scientific interest will be the degree to which we can eventually understand the full landscape of human stories, and data driven approaches will play a crucial role. Finally, we utilize web-scale data from Twitter to study the limits of what social data can tell us about public health, mental illness, discourse around the protest movement of #BlackLivesMatter, discourse around climate change, and hidden networks. We conclude with a review of published works in complex systems that separately analyze charitable donations, the happiness of words in 10 languages, 100 years of daily temperature data across the United States, and Australian Rules Football games.
Divergent discourse between protests and counter-protests: #BlackLivesMatter and #AllLivesMatter
May 20, 2017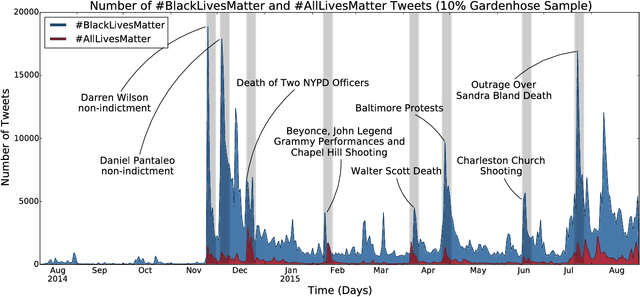
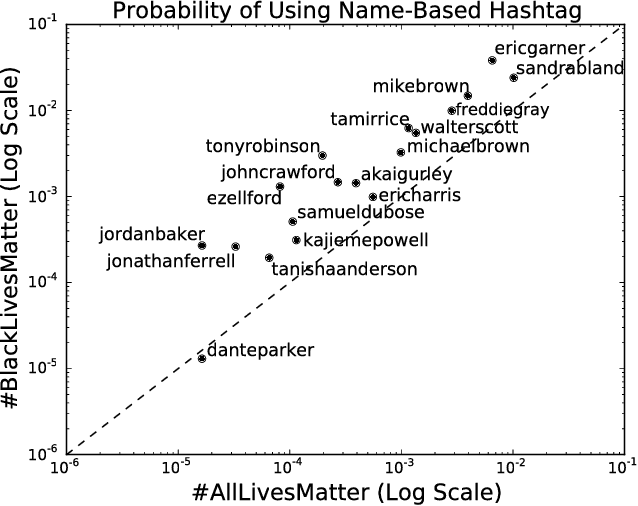
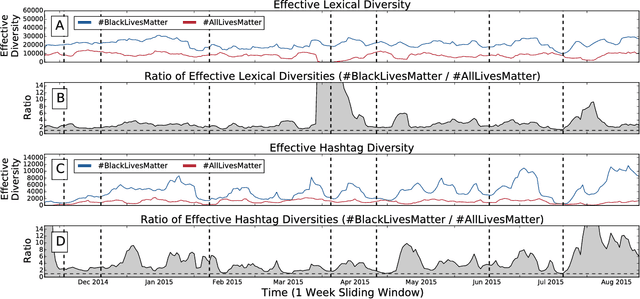
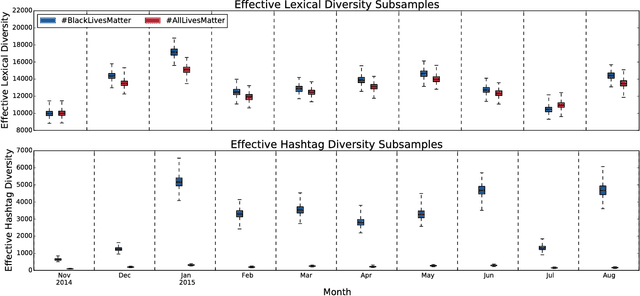
Since the shooting of Black teenager Michael Brown by White police officer Darren Wilson in Ferguson, Missouri, the protest hashtag #BlackLivesMatter has amplified critiques of extrajudicial killings of Black Americans. In response to #BlackLivesMatter, other Twitter users have adopted #AllLivesMatter, a counter-protest hashtag whose content argues that equal attention should be given to all lives regardless of race. Through a multi-level analysis of over 860,000 tweets, we study how these protests and counter-protests diverge by quantifying aspects of their discourse. We find that #AllLivesMatter facilitates opposition between #BlackLivesMatter and hashtags such as #PoliceLivesMatter and #BlueLivesMatter in such a way that historically echoes the tension between Black protesters and law enforcement. In addition, we show that a significant portion of #AllLivesMatter use stems from hijacking by #BlackLivesMatter advocates. Beyond simply injecting #AllLivesMatter with #BlackLivesMatter content, these hijackers use the hashtag to directly confront the counter-protest notion of "All lives matter." Our findings suggest that Black Lives Matter movement was able to grow, exhibit diverse conversations, and avoid derailment on social media by making discussion of counter-protest opinions a central topic of #AllLivesMatter, rather than the movement itself.
The emotional arcs of stories are dominated by six basic shapes
Sep 26, 2016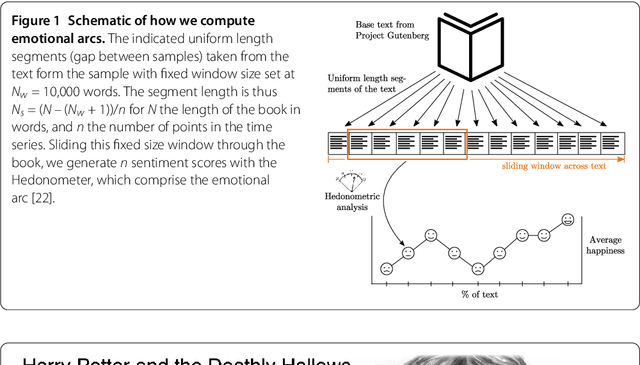
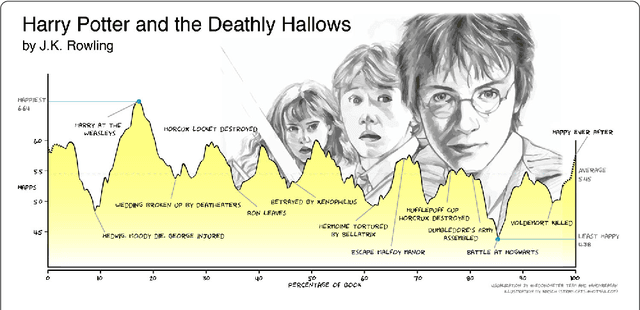
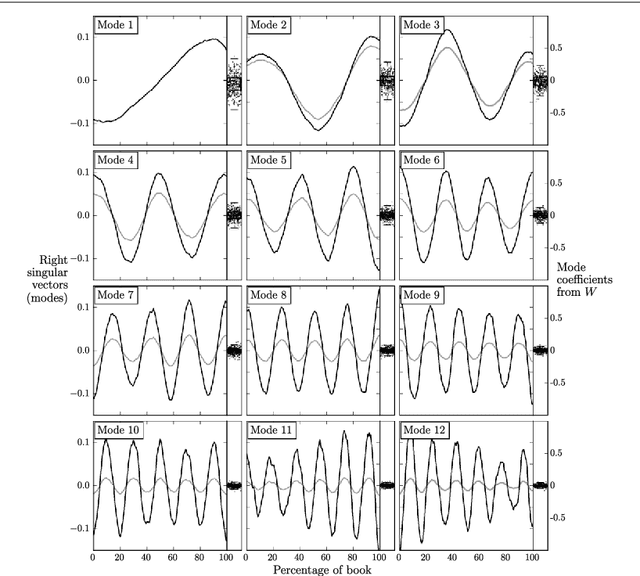
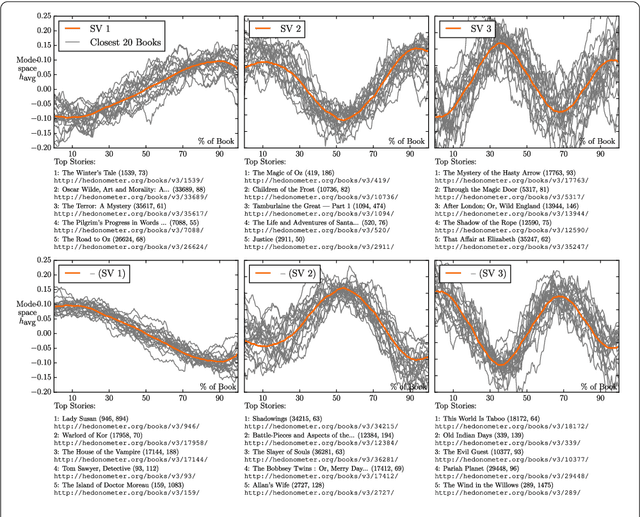
Advances in computing power, natural language processing, and digitization of text now make it possible to study a culture's evolution through its texts using a "big data" lens. Our ability to communicate relies in part upon a shared emotional experience, with stories often following distinct emotional trajectories and forming patterns that are meaningful to us. Here, by classifying the emotional arcs for a filtered subset of 1,327 stories from Project Gutenberg's fiction collection, we find a set of six core emotional arcs which form the essential building blocks of complex emotional trajectories. We strengthen our findings by separately applying Matrix decomposition, supervised learning, and unsupervised learning. For each of these six core emotional arcs, we examine the closest characteristic stories in publication today and find that particular emotional arcs enjoy greater success, as measured by downloads.
Benchmarking sentiment analysis methods for large-scale texts: A case for using continuum-scored words and word shift graphs
Sep 07, 2016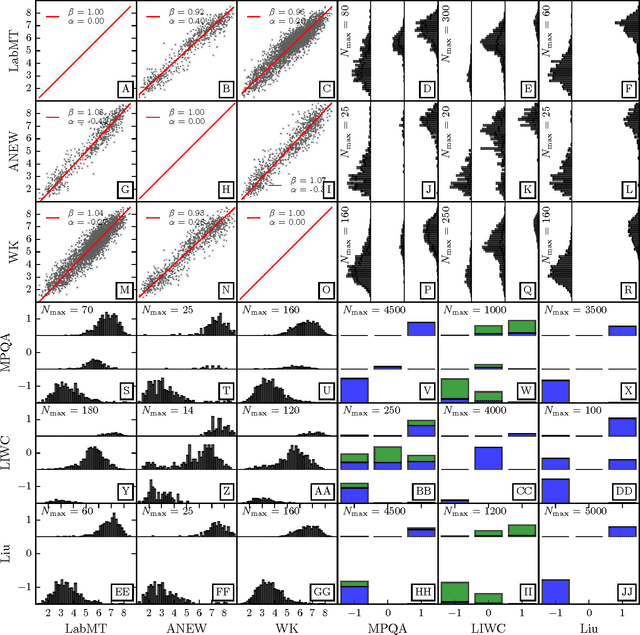
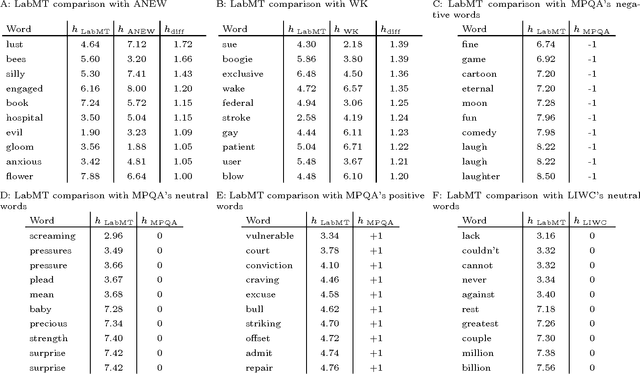
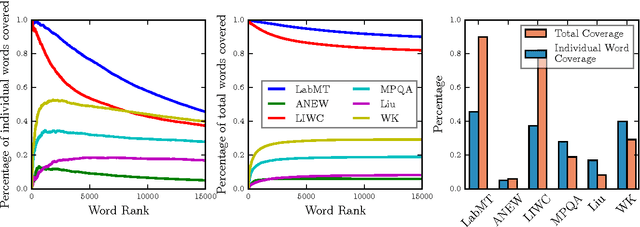
The emergence and global adoption of social media has rendered possible the real-time estimation of population-scale sentiment, bearing profound implications for our understanding of human behavior. Given the growing assortment of sentiment measuring instruments, comparisons between them are evidently required. Here, we perform detailed tests of 6 dictionary-based methods applied to 4 different corpora, and briefly examine a further 20 methods. We show that a dictionary-based method will only perform both reliably and meaningfully if (1) the dictionary covers a sufficiently large enough portion of a given text's lexicon when weighted by word usage frequency; and (2) words are scored on a continuous scale.
Zipf's law is a consequence of coherent language production
Aug 05, 2016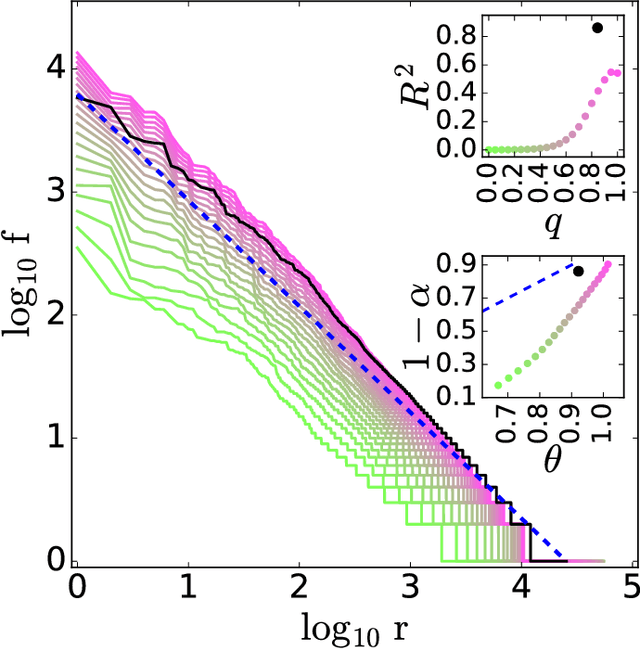
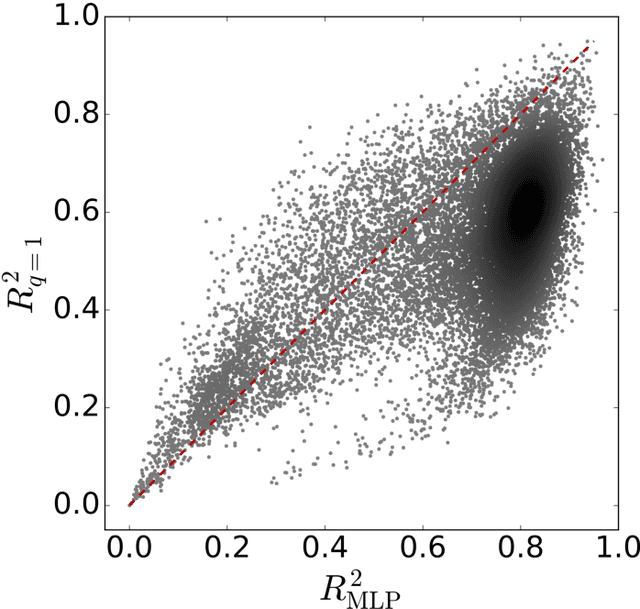
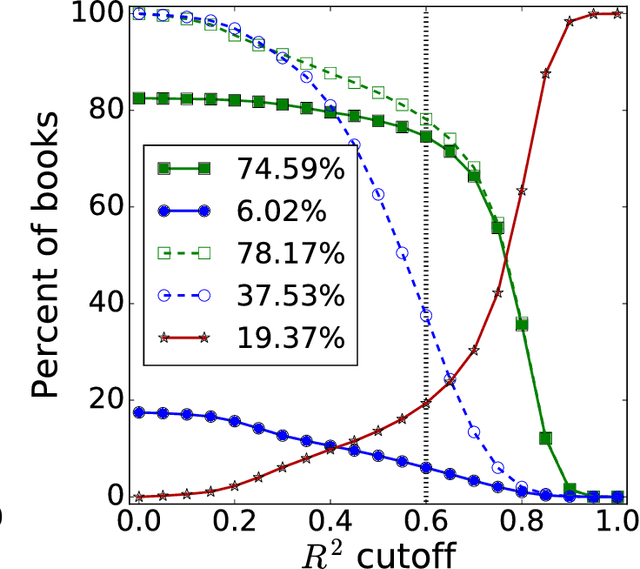
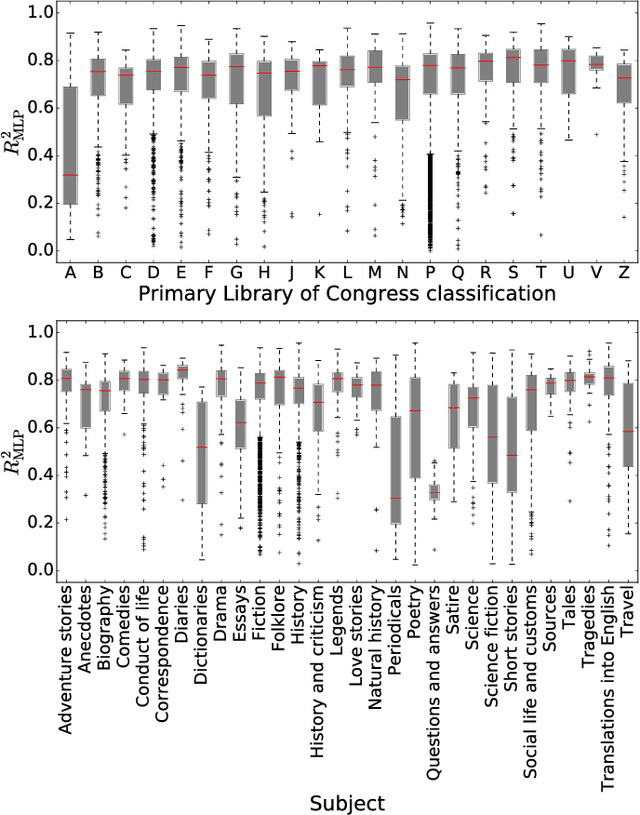
The task of text segmentation may be undertaken at many levels in text analysis---paragraphs, sentences, words, or even letters. Here, we focus on a relatively fine scale of segmentation, hypothesizing it to be in accord with a stochastic model of language generation, as the smallest scale where independent units of meaning are produced. Our goals in this letter include the development of methods for the segmentation of these minimal independent units, which produce feature-representations of texts that align with the independence assumption of the bag-of-terms model, commonly used for prediction and classification in computational text analysis. We also propose the measurement of texts' association (with respect to realized segmentations) to the model of language generation. We find (1) that our segmentations of phrases exhibit much better associations to the generation model than words and (2), that texts which are well fit are generally topically homogeneous. Because our generative model produces Zipf's law, our study further suggests that Zipf's law may be a consequence of homogeneity in language production.
Human language reveals a universal positivity bias
Jun 15, 2014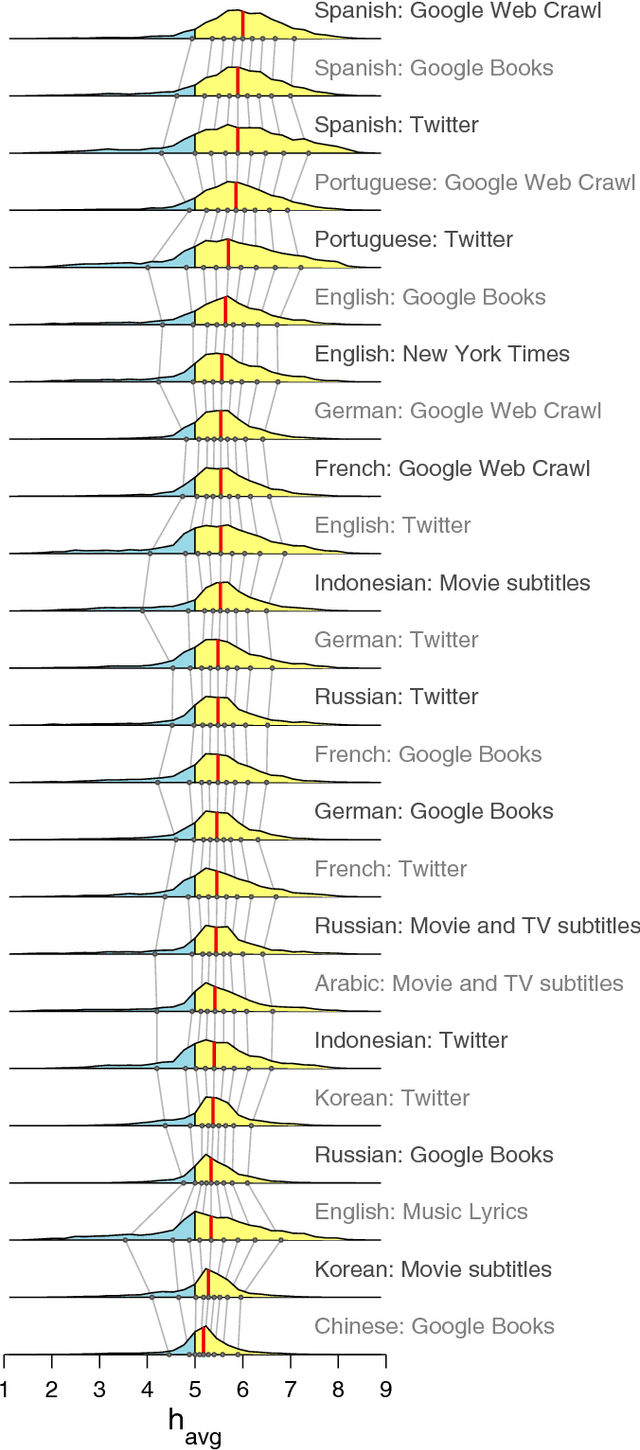
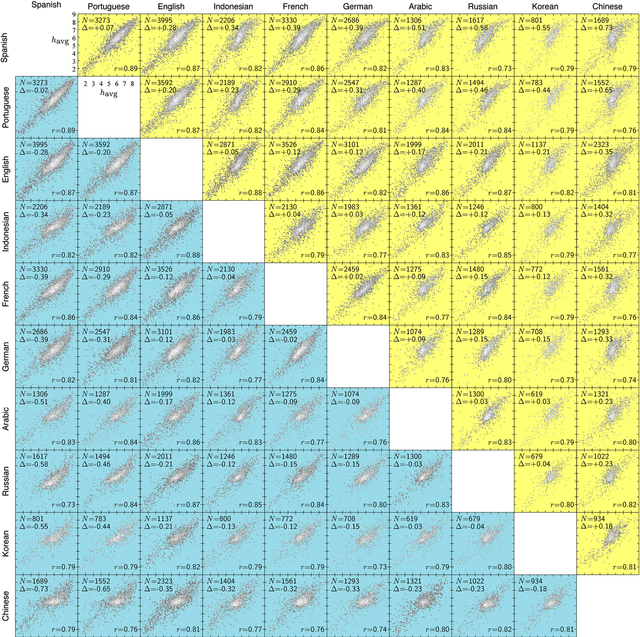
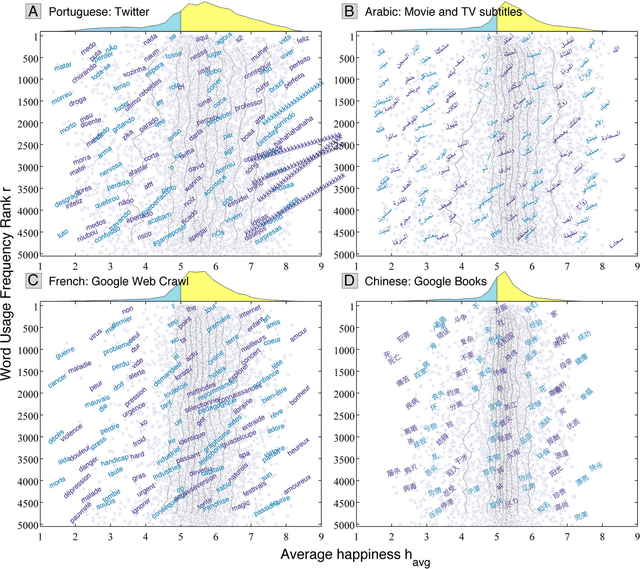
Using human evaluation of 100,000 words spread across 24 corpora in 10 languages diverse in origin and culture, we present evidence of a deep imprint of human sociality in language, observing that (1) the words of natural human language possess a universal positivity bias; (2) the estimated emotional content of words is consistent between languages under translation; and (3) this positivity bias is strongly independent of frequency of word usage. Alongside these general regularities, we describe inter-language variations in the emotional spectrum of languages which allow us to rank corpora. We also show how our word evaluations can be used to construct physical-like instruments for both real-time and offline measurement of the emotional content of large-scale texts.