 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeeping Notes: Conditional Natural Language Generation with a Scratchpad Mechanism
Jun 13, 2019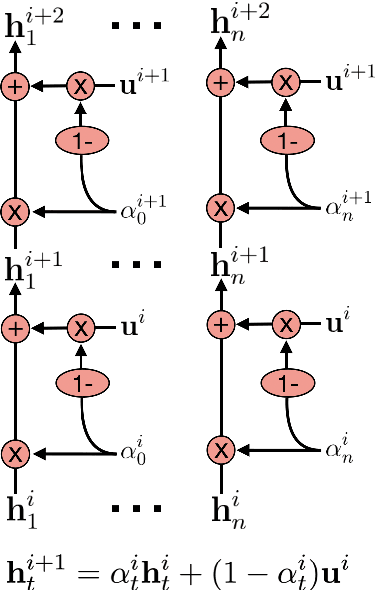
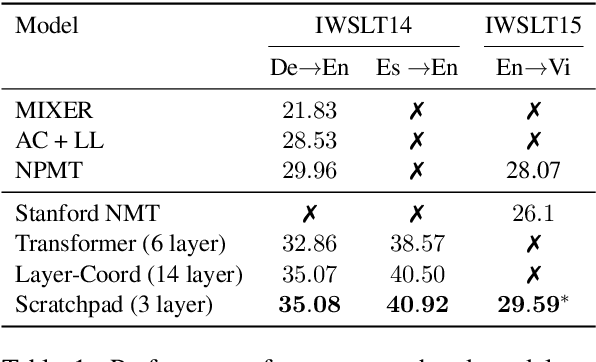
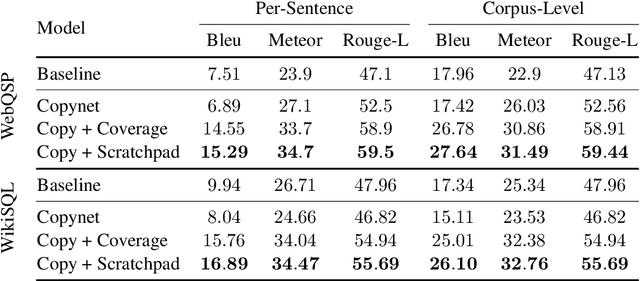
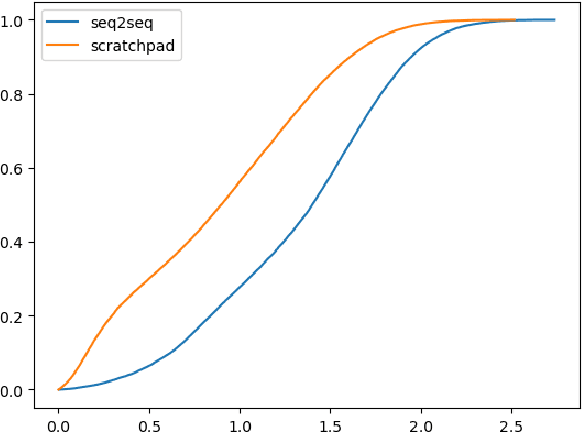
We introduce the Scratchpad Mechanism, a novel addition to the sequence-to-sequence (seq2seq) neural network architecture and demonstrate its effectiveness in improving the overall fluency of seq2seq models for natural language generation tasks. By enabling the decoder at each time step to write to all of the encoder output layers, Scratchpad can employ the encoder as a "scratchpad" memory to keep track of what has been generated so far and thereby guide future generation. We evaluate Scratchpad in the context of three well-studied natural language generation tasks --- Machine Translation, Question Generation, and Text Summarization --- and obtain state-of-the-art or comparable performance on standard datasets for each task. Qualitative assessments in the form of human judgements (question generation), attention visualization (MT), and sample output (summarization) provide further evidence of the ability of Scratchpad to generate fluent and expressive output.
Zipf's law holds for phrases, not words
Mar 04, 2015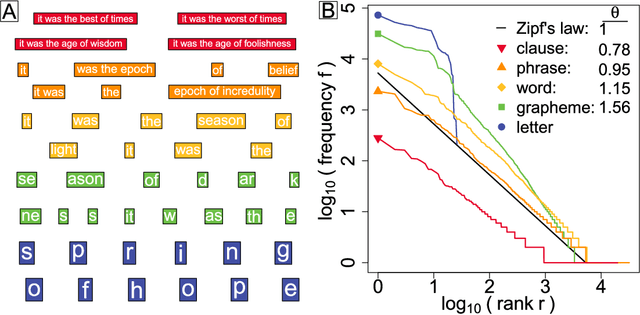

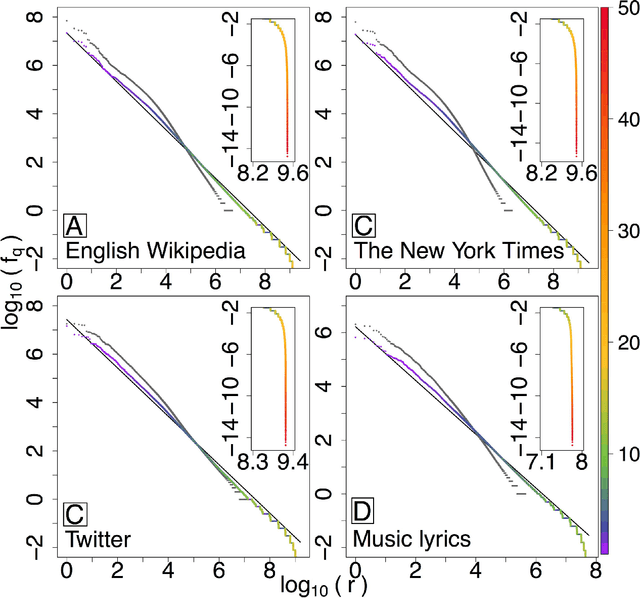
With Zipf's law being originally and most famously observed for word frequency, it is surprisingly limited in its applicability to human language, holding over no more than three to four orders of magnitude before hitting a clear break in scaling. Here, building on the simple observation that phrases of one or more words comprise the most coherent units of meaning in language, we show empirically that Zipf's law for phrases extends over as many as nine orders of rank magnitude. In doing so, we develop a principled and scalable statistical mechanical method of random text partitioning, which opens up a rich frontier of rigorous text analysis via a rank ordering of mixed length phrases.
Human language reveals a universal positivity bias
Jun 15, 2014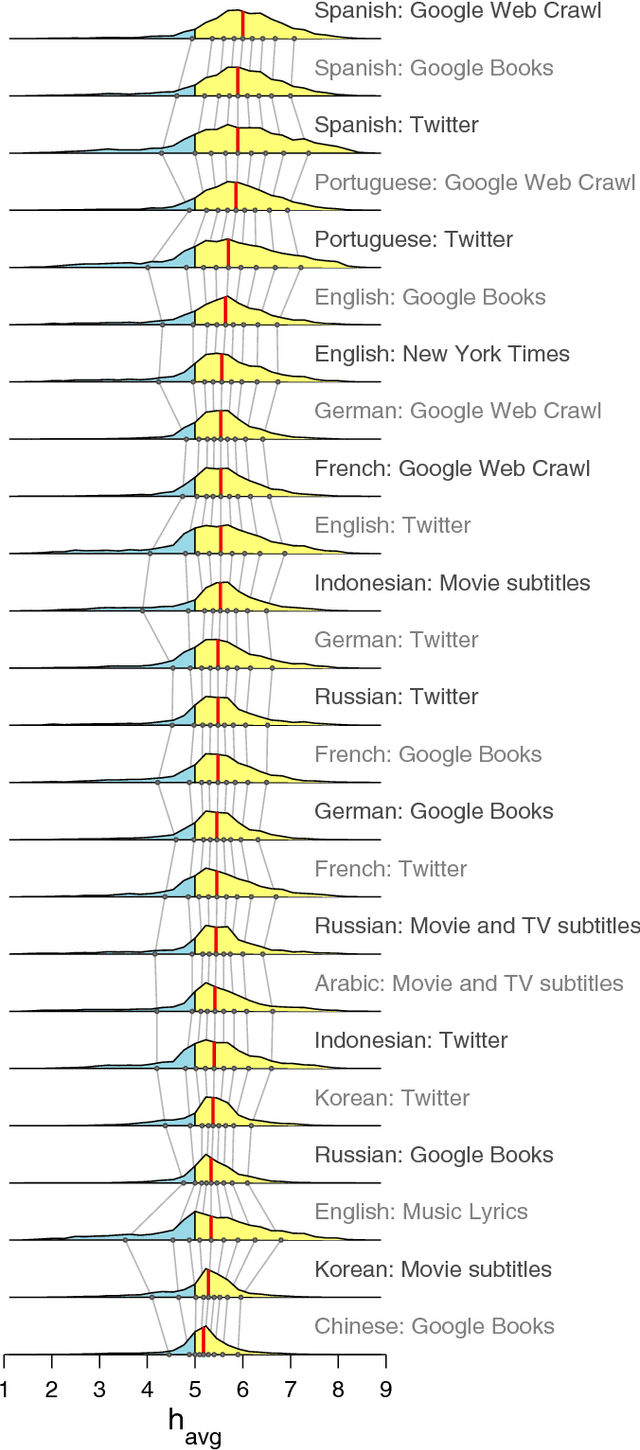
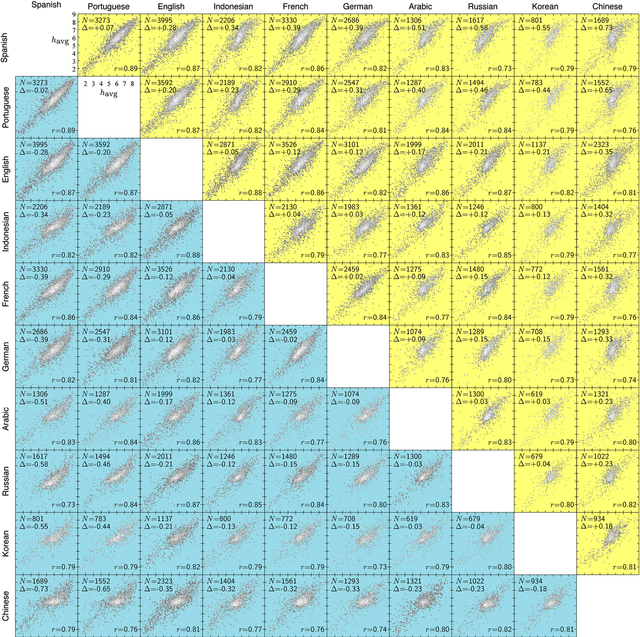
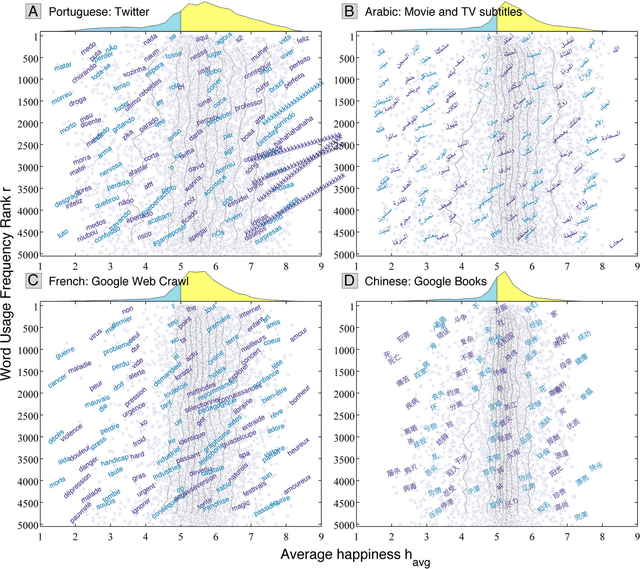
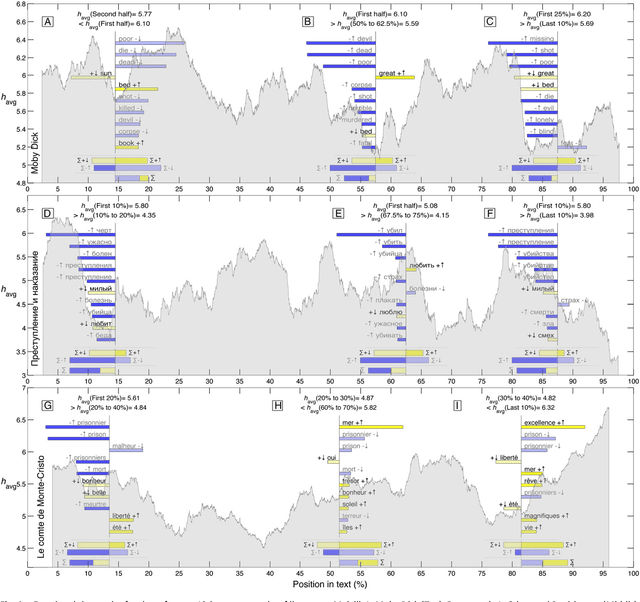
Using human evaluation of 100,000 words spread across 24 corpora in 10 languages diverse in origin and culture, we present evidence of a deep imprint of human sociality in language, observing that (1) the words of natural human language possess a universal positivity bias; (2) the estimated emotional content of words is consistent between languages under translation; and (3) this positivity bias is strongly independent of frequency of word usage. Alongside these general regularities, we describe inter-language variations in the emotional spectrum of languages which allow us to rank corpora. We also show how our word evaluations can be used to construct physical-like instruments for both real-time and offline measurement of the emotional content of large-scale texts.