 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Sentiment Analysis of Breast Cancer Treatment Experiences and Healthcare Perceptions Across Twitter
Oct 12, 2018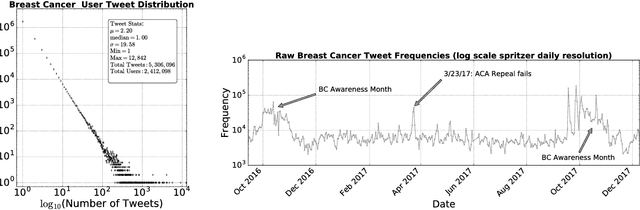
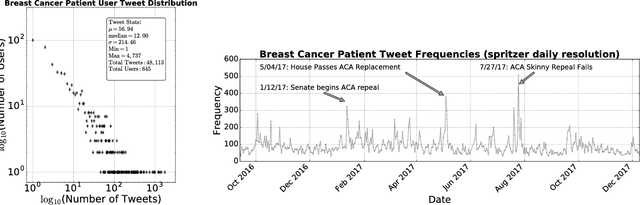
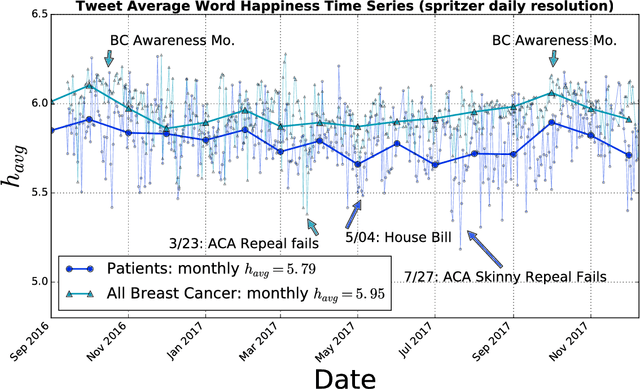
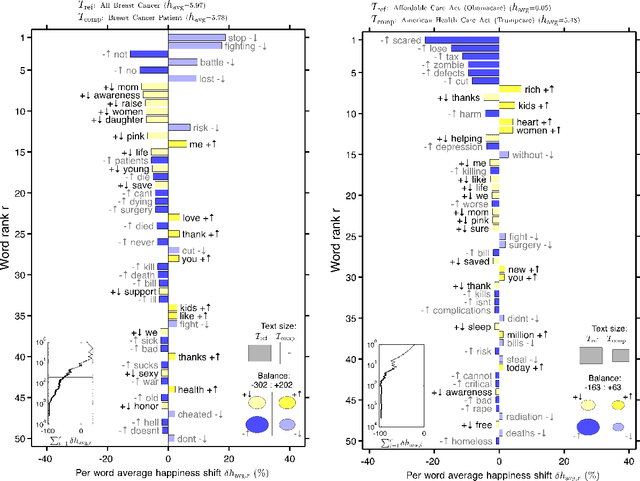
Background: Social media has the capacity to afford the healthcare industry with valuable feedback from patients who reveal and express their medical decision-making process, as well as self-reported quality of life indicators both during and post treatment. In prior work, [Crannell et. al.], we have studied an active cancer patient population on Twitter and compiled a set of tweets describing their experience with this disease. We refer to these online public testimonies as "Invisible Patient Reported Outcomes" (iPROs), because they carry relevant indicators, yet are difficult to capture by conventional means of self-report. Methods: Our present study aims to identify tweets related to the patient experience as an additional informative tool for monitoring public health. Using Twitter's public streaming API, we compiled over 5.3 million "breast cancer" related tweets spanning September 2016 until mid December 2017. We combined supervised machine learning methods with natural language processing to sift tweets relevant to breast cancer patient experiences. We analyzed a sample of 845 breast cancer patient and survivor accounts, responsible for over 48,000 posts. We investigated tweet content with a hedonometric sentiment analysis to quantitatively extract emotionally charged topics. Results: We found that positive experiences were shared regarding patient treatment, raising support, and spreading awareness. Further discussions related to healthcare were prevalent and largely negative focusing on fear of political legislation that could result in loss of coverage. Conclusions: Social media can provide a positive outlet for patients to discuss their needs and concerns regarding their healthcare coverage and treatment needs. Capturing iPROs from online communication can help inform healthcare professionals and lead to more connected and personalized treatment regimens.
Sifting Robotic from Organic Text: A Natural Language Approach for Detecting Automation on Twitter
Jun 14, 2016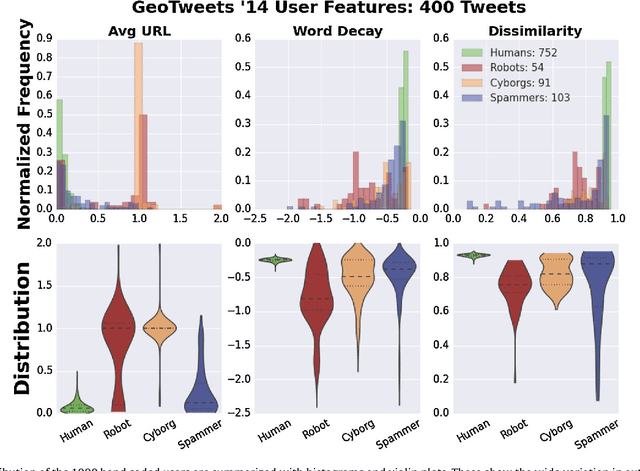
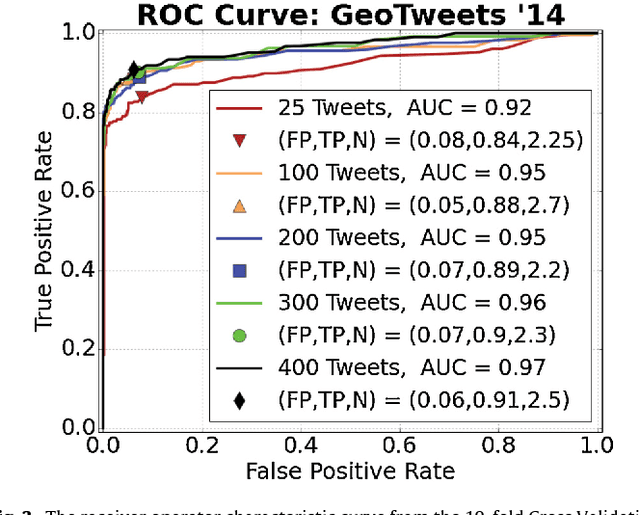
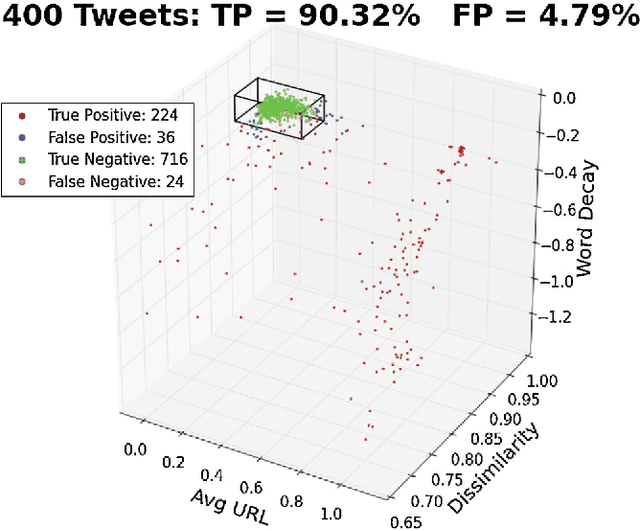
Twitter, a popular social media outlet, has evolved into a vast source of linguistic data, rich with opinion, sentiment, and discussion. Due to the increasing popularity of Twitter, its perceived potential for exerting social influence has led to the rise of a diverse community of automatons, commonly referred to as bots. These inorganic and semi-organic Twitter entities can range from the benevolent (e.g., weather-update bots, help-wanted-alert bots) to the malevolent (e.g., spamming messages, advertisements, or radical opinions). Existing detection algorithms typically leverage meta-data (time between tweets, number of followers, etc.) to identify robotic accounts. Here, we present a powerful classification scheme that exclusively uses the natural language text from organic users to provide a criterion for identifying accounts posting automated messages. Since the classifier operates on text alone, it is flexible and may be applied to any textual data beyond the Twitter-sphere.
Identifying missing dictionary entries with frequency-conserving context models
Jul 29, 2015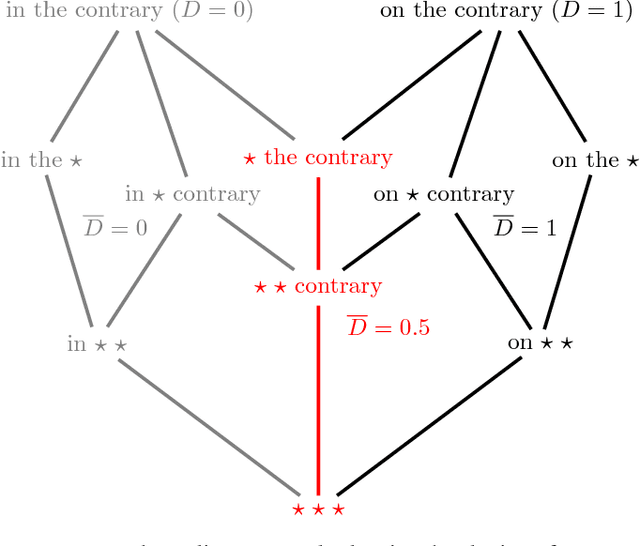
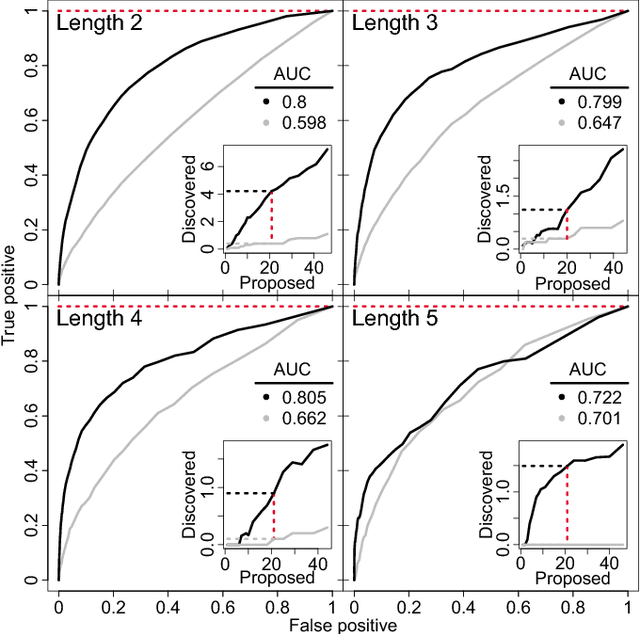
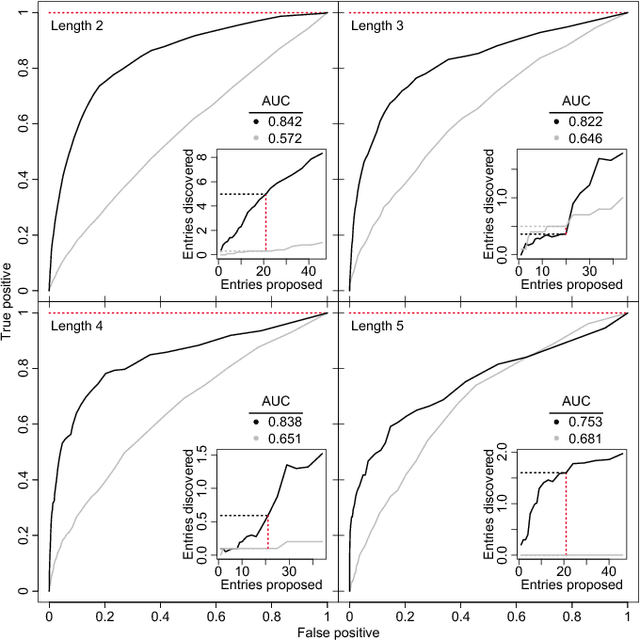
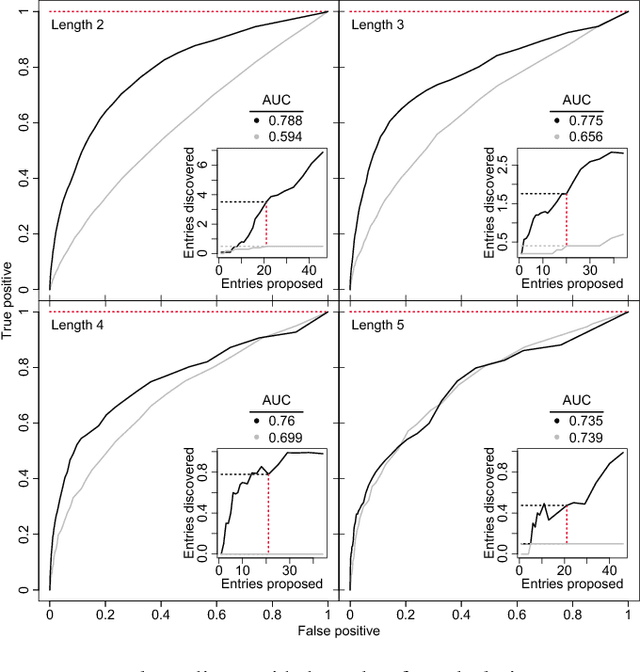
In an effort to better understand meaning from natural language texts, we explore methods aimed at organizing lexical objects into contexts. A number of these methods for organization fall into a family defined by word ordering. Unlike demographic or spatial partitions of data, these collocation models are of special importance for their universal applicability. While we are interested here in text and have framed our treatment appropriately, our work is potentially applicable to other areas of research (e.g., speech, genomics, and mobility patterns) where one has ordered categorical data, (e.g., sounds, genes, and locations). Our approach focuses on the phrase (whether word or larger) as the primary meaning-bearing lexical unit and object of study. To do so, we employ our previously developed framework for generating word-conserving phrase-frequency data. Upon training our model with the Wiktionary---an extensive, online, collaborative, and open-source dictionary that contains over 100,000 phrasal-definitions---we develop highly effective filters for the identification of meaningful, missing phrase-entries. With our predictions we then engage the editorial community of the Wiktionary and propose short lists of potential missing entries for definition, developing a breakthrough, lexical extraction technique, and expanding our knowledge of the defined English lexicon of phrases.
Human language reveals a universal positivity bias
Jun 15, 2014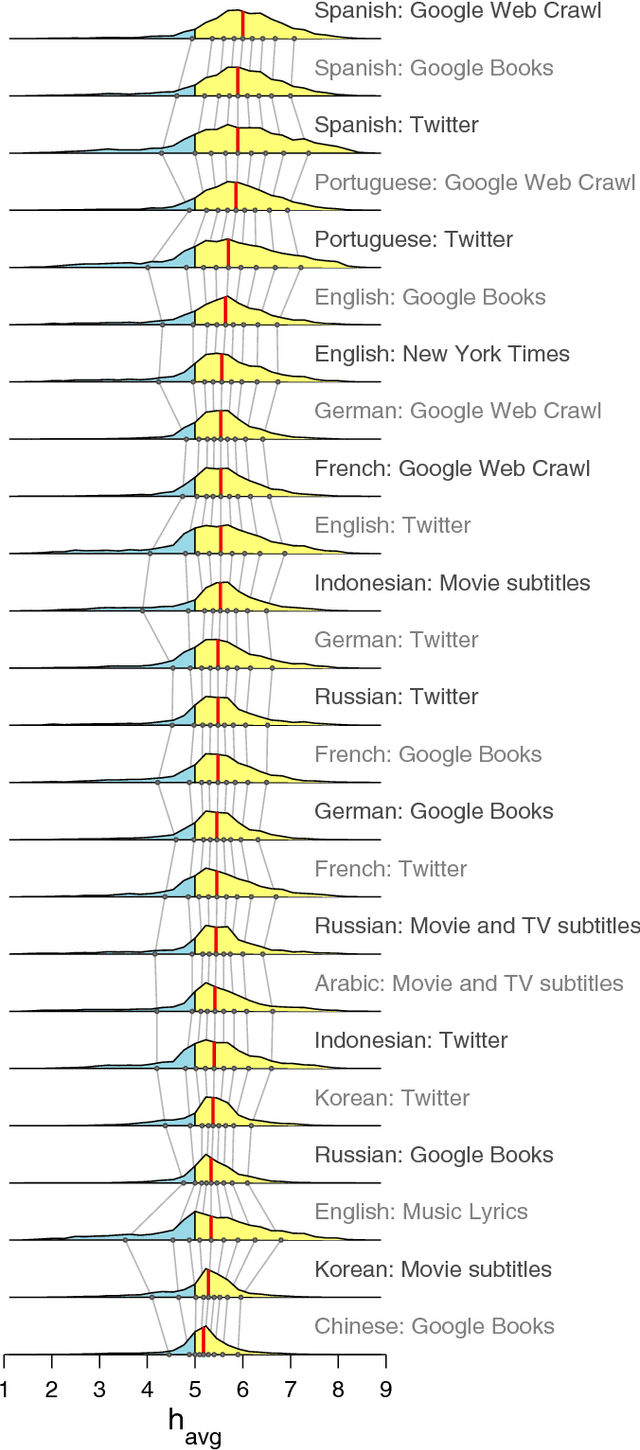
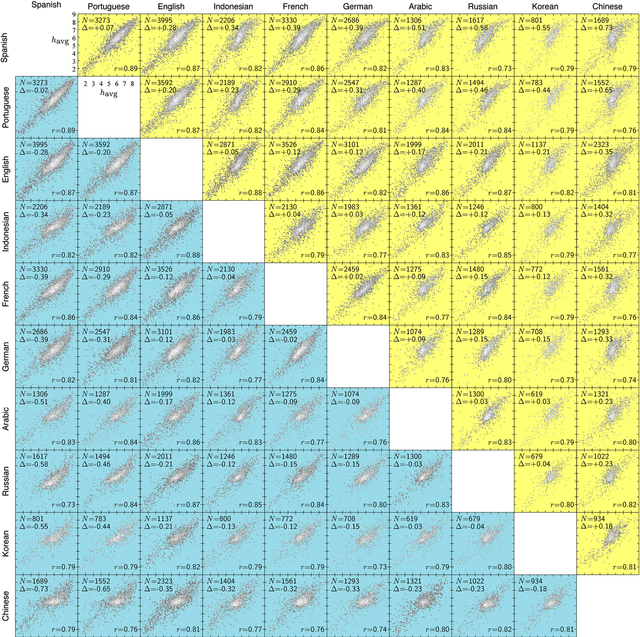
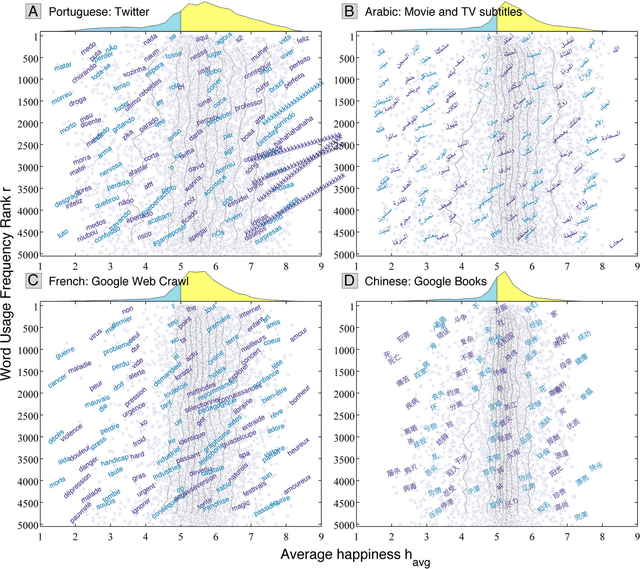
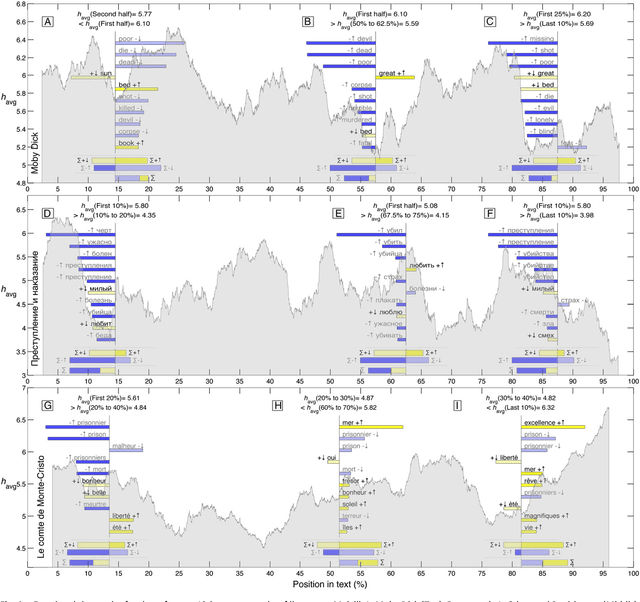
Using human evaluation of 100,000 words spread across 24 corpora in 10 languages diverse in origin and culture, we present evidence of a deep imprint of human sociality in language, observing that (1) the words of natural human language possess a universal positivity bias; (2) the estimated emotional content of words is consistent between languages under translation; and (3) this positivity bias is strongly independent of frequency of word usage. Alongside these general regularities, we describe inter-language variations in the emotional spectrum of languages which allow us to rank corpora. We also show how our word evaluations can be used to construct physical-like instruments for both real-time and offline measurement of the emotional content of large-scale texts.