 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman language reveals a universal positivity bias
Paper and Code
Jun 15, 2014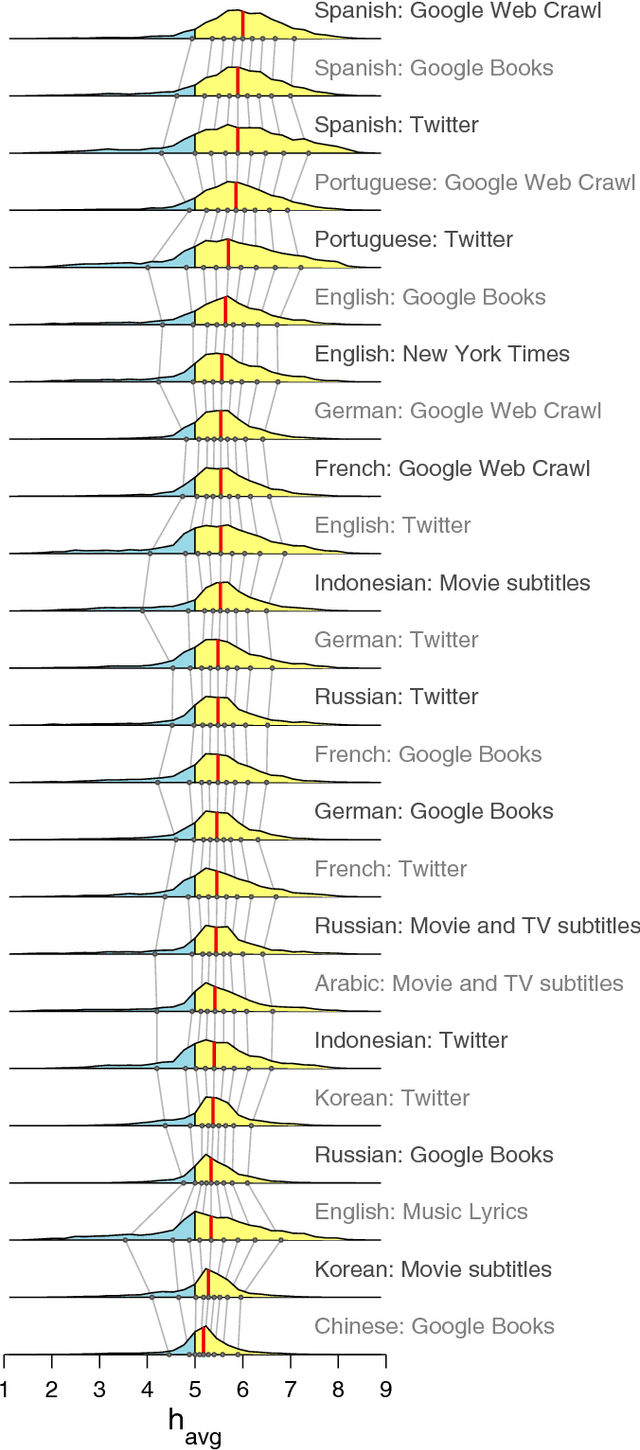
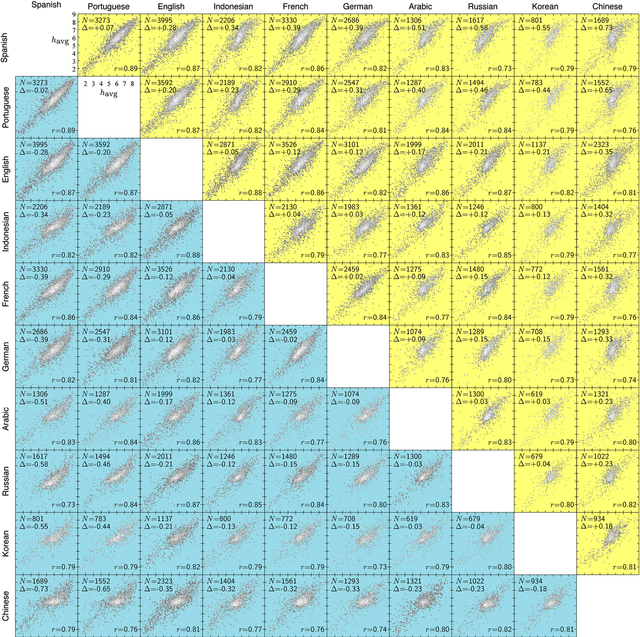
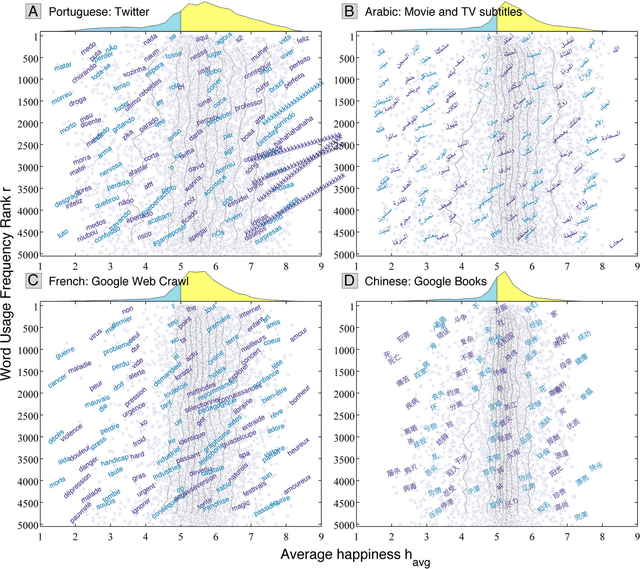
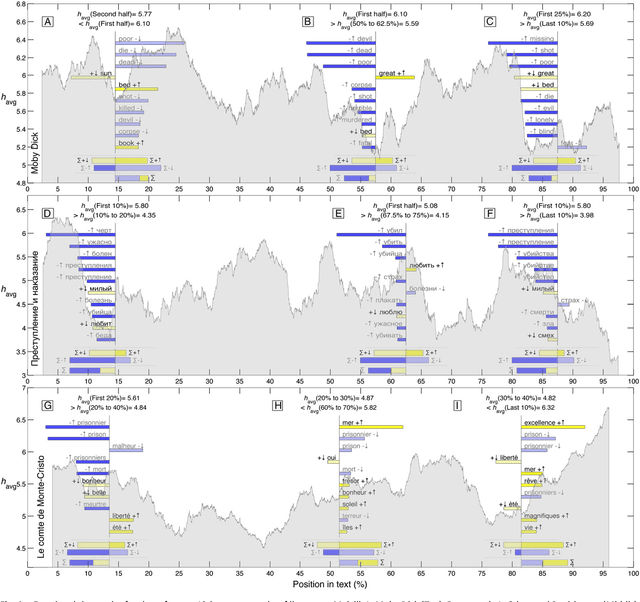
Using human evaluation of 100,000 words spread across 24 corpora in 10 languages diverse in origin and culture, we present evidence of a deep imprint of human sociality in language, observing that (1) the words of natural human language possess a universal positivity bias; (2) the estimated emotional content of words is consistent between languages under translation; and (3) this positivity bias is strongly independent of frequency of word usage. Alongside these general regularities, we describe inter-language variations in the emotional spectrum of languages which allow us to rank corpora. We also show how our word evaluations can be used to construct physical-like instruments for both real-time and offline measurement of the emotional content of large-scale texts.