 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBit Cipher -- A Simple yet Powerful Word Representation System that Integrates Efficiently with Language Models
Nov 18, 2023While Large Language Models (LLMs) become ever more dominant, classic pre-trained word embeddings sustain their relevance through computational efficiency and nuanced linguistic interpretation. Drawing from recent studies demonstrating that the convergence of GloVe and word2vec optimizations all tend towards log-co-occurrence matrix variants, we construct a novel word representation system called Bit-cipher that eliminates the need of backpropagation while leveraging contextual information and hyper-efficient dimensionality reduction techniques based on unigram frequency, providing strong interpretability, alongside efficiency. We use the bit-cipher algorithm to train word vectors via a two-step process that critically relies on a hyperparameter -- bits -- that controls the vector dimension. While the first step trains the bit-cipher, the second utilizes it under two different aggregation modes -- summation or concatenation -- to produce contextually rich representations from word co-occurrences. We extend our investigation into bit-cipher's efficacy, performing probing experiments on part-of-speech (POS) tagging and named entity recognition (NER) to assess its competitiveness with classic embeddings like word2vec and GloVe. Additionally, we explore its applicability in LM training and fine-tuning. By replacing embedding layers with cipher embeddings, our experiments illustrate the notable efficiency of cipher in accelerating the training process and attaining better optima compared to conventional training paradigms. Experiments on the integration of bit-cipher embedding layers with Roberta, T5, and OPT, prior to or as a substitute for fine-tuning, showcase a promising enhancement to transfer learning, allowing rapid model convergence while preserving competitive performance.
Reducing the Need for Backpropagation and Discovering Better Optima With Explicit Optimizations of Neural Networks
Nov 13, 2023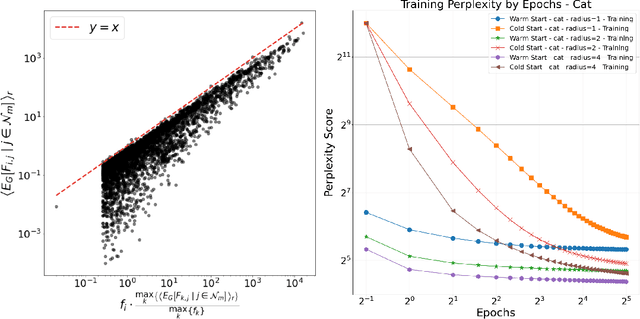

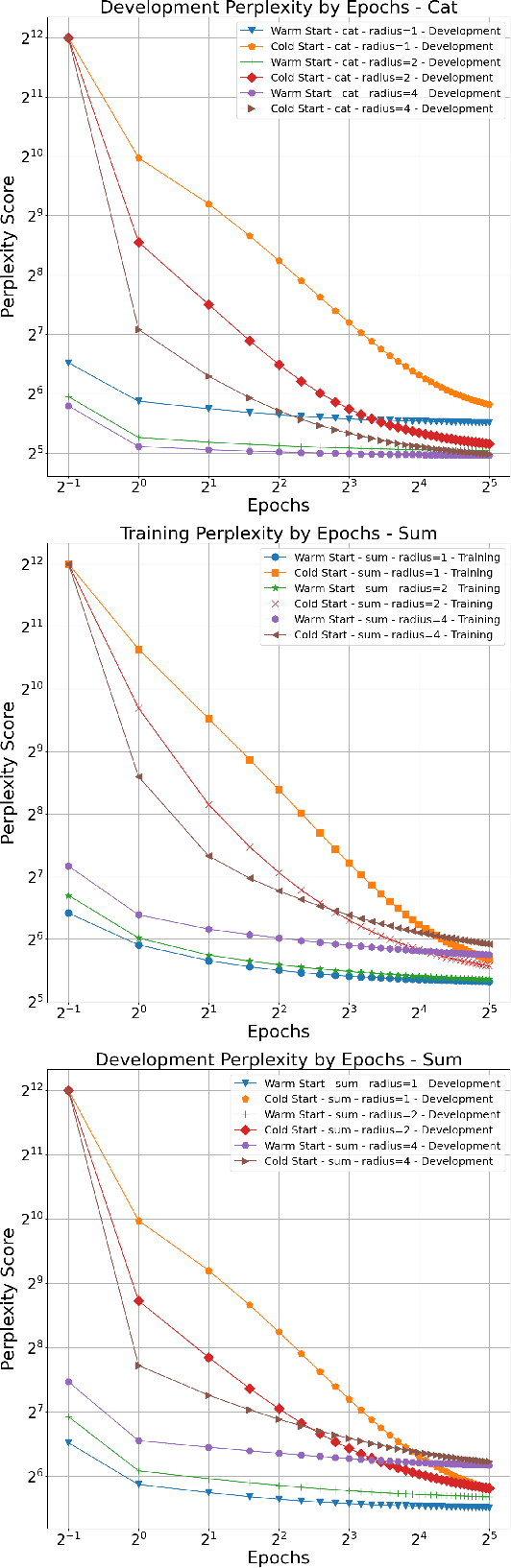
Iterative differential approximation methods that rely upon backpropagation have enabled the optimization of neural networks; however, at present, they remain computationally expensive, especially when training models at scale. In this paper, we propose a computationally efficient alternative for optimizing neural networks that can both reduce the costs of scaling neural networks and provide high-efficiency optimizations for low-resource applications. We derive an explicit solution to a simple feed-forward language model (LM) by mathematically analyzing its gradients. This solution generalizes from single-layer LMs to the class of all single-layer feed-forward softmax-activated neural models trained on positive-valued features, as is demonstrated by our extension of this solution application to MNIST digit classification. For both LM and digit classifiers, we find computationally that explicit solutions perform near-optimality in experiments showing that 1) iterative optimization only marginally improves the explicit solution parameters and 2) randomly initialized parameters iteratively optimize towards the explicit solution. We also preliminarily apply the explicit solution locally by layer in multi-layer networks and discuss how the solution's computational savings increase with model complexity -- for both single- and mult-layer applications of the explicit solution, we emphasize that the optima achieved cannot be reached by backpropagation alone, i.e., better optima appear discoverable only after explicit solutions are applied. Finally, we discuss the solution's computational savings alongside its impact on model interpretability and suggest future directions for the derivation of explicit solutions to complex- and multi-layer architectures.
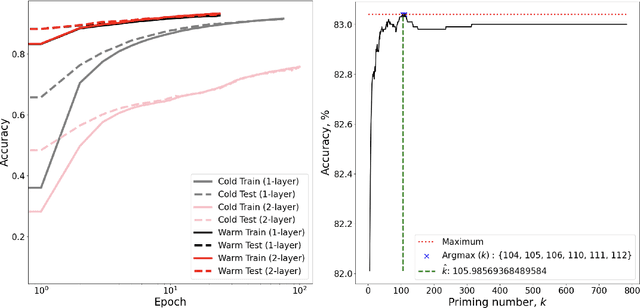
Explicit Foundation Model Optimization with Self-Attentive Feed-Forward Neural Units
Nov 13, 2023Iterative approximation methods using backpropagation enable the optimization of neural networks, but they remain computationally expensive, especially when used at scale. This paper presents an efficient alternative for optimizing neural networks that reduces the costs of scaling neural networks and provides high-efficiency optimizations for low-resource applications. We will discuss a general result about feed-forward neural networks and then extend this solution to compositional (mult-layer) networks, which are applied to a simplified transformer block containing feed-forward and self-attention layers. These models are used to train highly-specified and complex multi-layer neural architectures that we refer to as self-attentive feed-forward unit (SAFFU) layers, which we use to develop a transformer that appears to generalize well over small, cognitively-feasible, volumes of data. Testing demonstrates explicit solutions outperform models optimized by backpropagation alone. Moreover, further application of backpropagation after explicit solutions leads to better optima from smaller scales of data, training effective models from much less data is enabled by explicit solution warm starts. We then carry out ablation experiments training a roadmap of about 250 transformer models over 1-million tokens to determine ideal settings. We find that multiple different architectural variants produce highly-performant models, and discover from this ablation that some of the best are not the most parameterized. This appears to indicate well-generalized models could be reached using less data by using explicit solutions, and that architectural exploration using explicit solutions pays dividends in guiding the search for efficient variants with fewer parameters, and which could be incorporated into low-resource hardware where AI might be embodied.
EigenNoise: A Contrastive Prior to Warm-Start Representations
May 09, 2022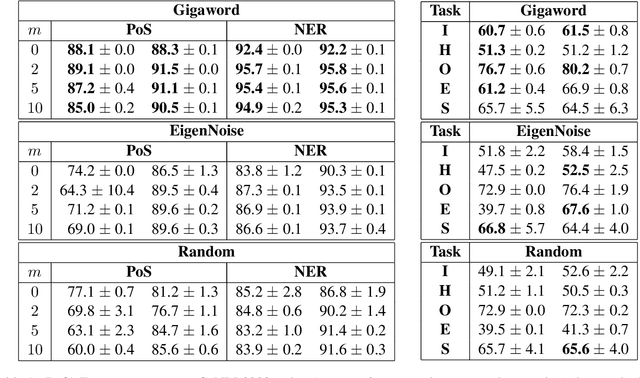
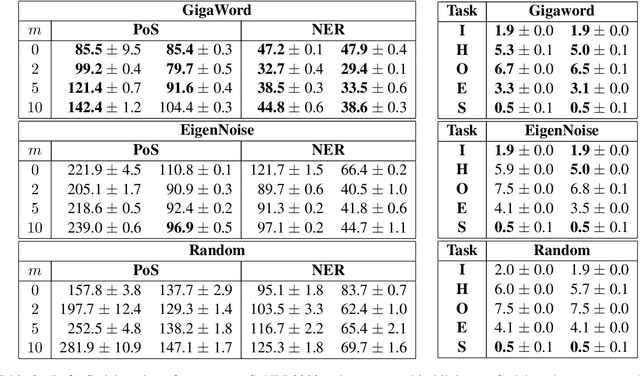
In this work, we present a naive initialization scheme for word vectors based on a dense, independent co-occurrence model and provide preliminary results that suggest it is competitive and warrants further investigation. Specifically, we demonstrate through information-theoretic minimum description length (MDL) probing that our model, EigenNoise, can approach the performance of empirically trained GloVe despite the lack of any pre-training data (in the case of EigenNoise). We present these preliminary results with interest to set the stage for further investigations into how this competitive initialization works without pre-training data, as well as to invite the exploration of more intelligent initialization schemes informed by the theory of harmonic linguistic structure. Our application of this theory likewise contributes a novel (and effective) interpretation of recent discoveries which have elucidated the underlying distributional information that linguistic representations capture from data and contrast distributions.
To Know by the Company Words Keep and What Else Lies in the Vicinity
Apr 30, 2022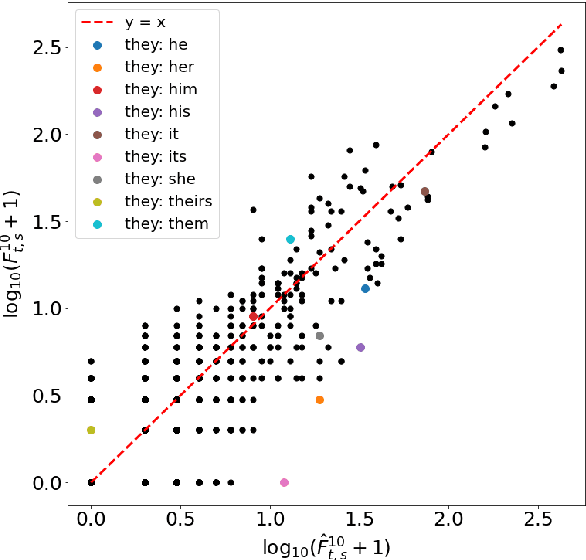
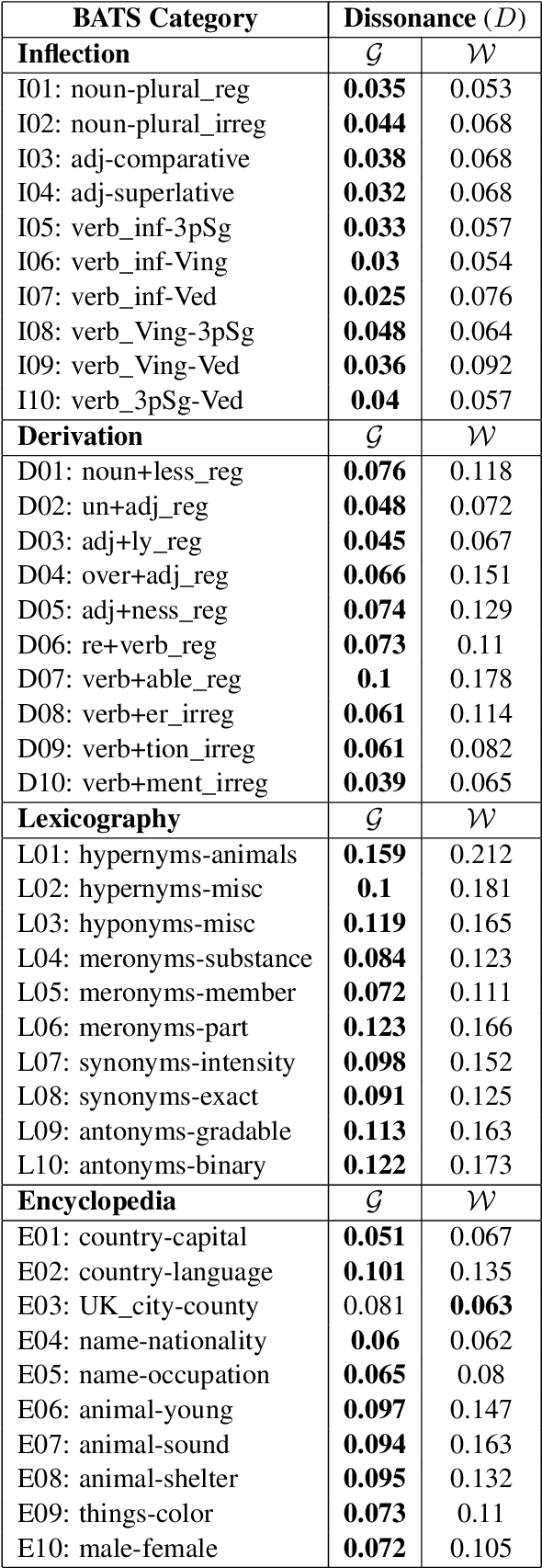
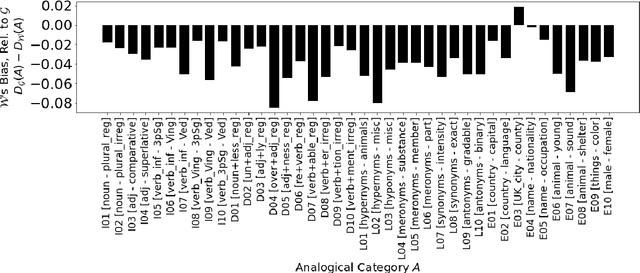
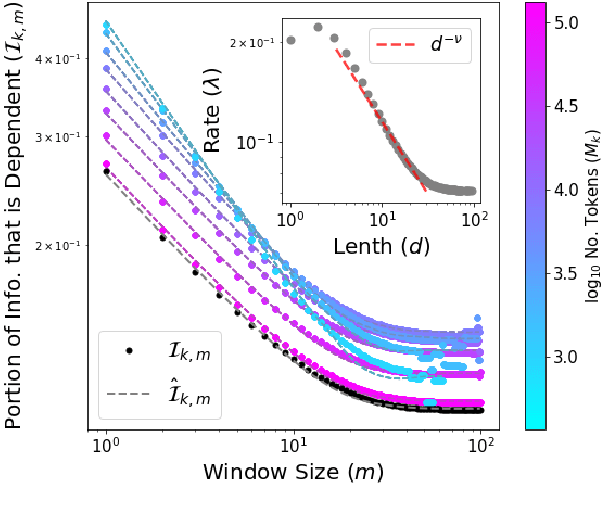
The development of state-of-the-art (SOTA) Natural Language Processing (NLP) systems has steadily been establishing new techniques to absorb the statistics of linguistic data. These techniques often trace well-known constructs from traditional theories, and we study these connections to close gaps around key NLP methods as a means to orient future work. For this, we introduce an analytic model of the statistics learned by seminal algorithms (including GloVe and Word2Vec), and derive insights for systems that use these algorithms and the statistics of co-occurrence, in general. In this work, we derive -- to the best of our knowledge -- the first known solution to Word2Vec's softmax-optimized, skip-gram algorithm. This result presents exciting potential for future development as a direct solution to a deep learning (DL) language model's (LM's) matrix factorization. However, we use the solution to demonstrate a seemingly-universal existence of a property that word vectors exhibit and which allows for the prophylactic discernment of biases in data -- prior to their absorption by DL models. To qualify our work, we conduct an analysis of independence, i.e., on the density of statistical dependencies in co-occurrence models, which in turn renders insights on the distributional hypothesis' partial fulfillment by co-occurrence statistics.
A general solution to the preferential selection model
Aug 06, 2020
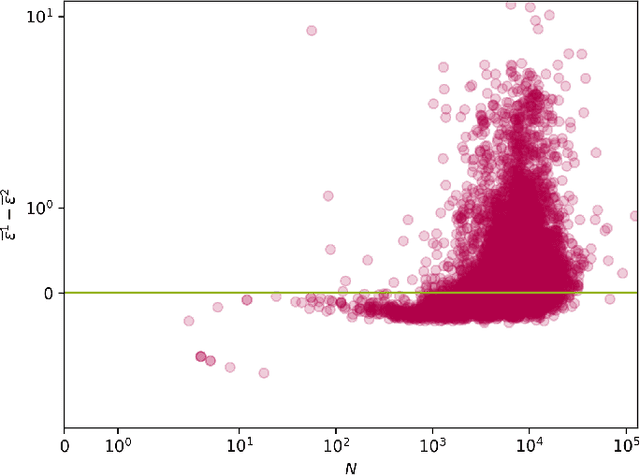
We provide a general analytic solution to Herbert Simon's 1955 model for time-evolving novelty functions. This has far-reaching consequences: Simon's is a pre-cursor model for Barabasi's 1999 preferential attachment model for growing social networks, and our general abstraction of it more considers attachment to be a form of link selection. We show that any system which can be modeled as instances of types---i.e., occurrence data (frequencies)---can be generatively modeled (and simulated) from a distributional perspective with an exceptionally high-degree of accuracy.
A Computational Framework for Multi-Modal Social Action Identification
Oct 24, 2017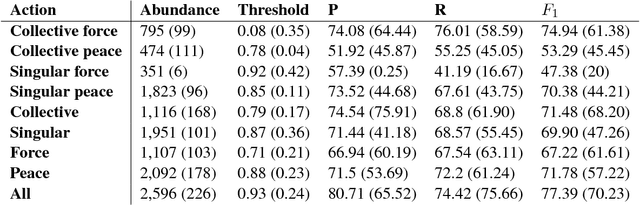
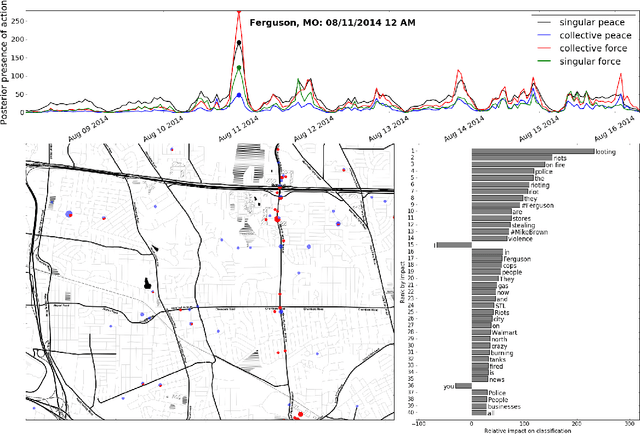
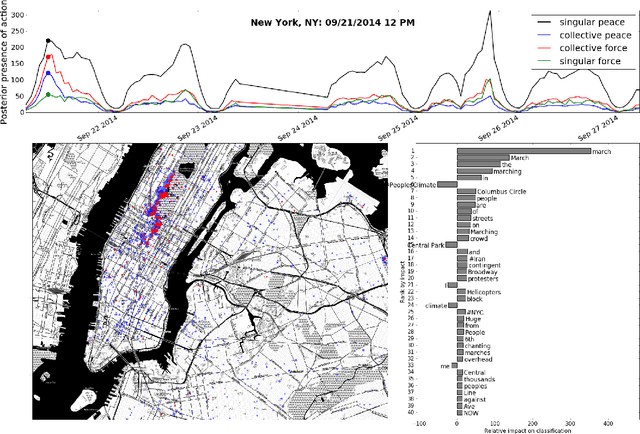
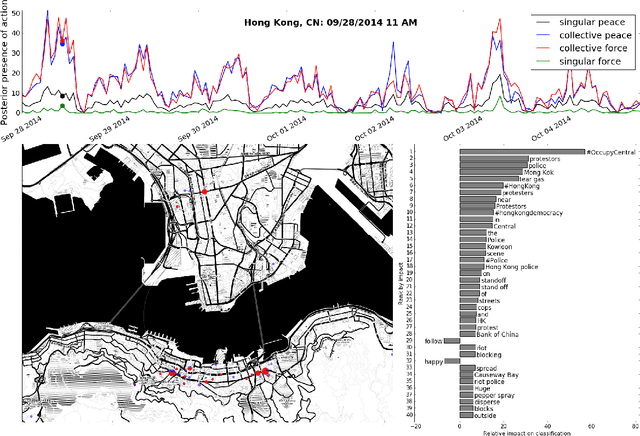
We create a computational framework for understanding social action and demonstrate how this framework can be used to build an open-source event detection tool with scalable statistical machine learning algorithms and a subsampled database of over 600 million geo-tagged Tweets from around the world. These Tweets were collected between April 1st, 2014 and April 30th, 2015, most notably when the Black Lives Matter movement began. We demonstrate how these methods can be used diagnostically-by researchers, government officials and the public-to understand peaceful and violent collective action at very fine-grained levels of time and geography.
Is space a word, too?
Oct 20, 2017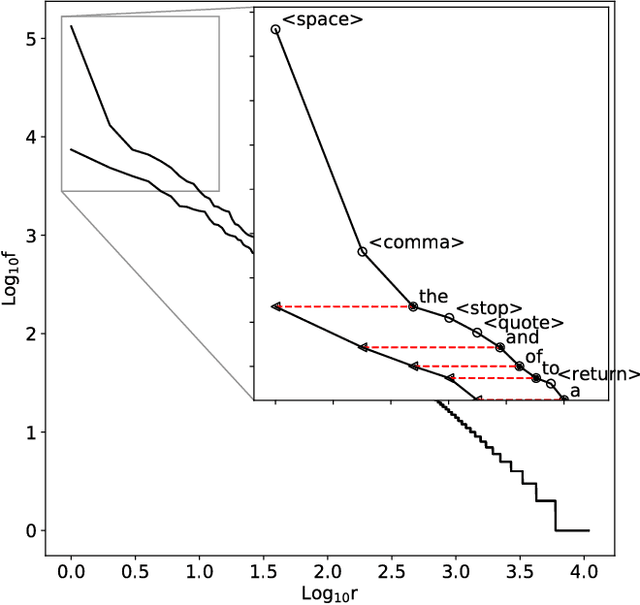
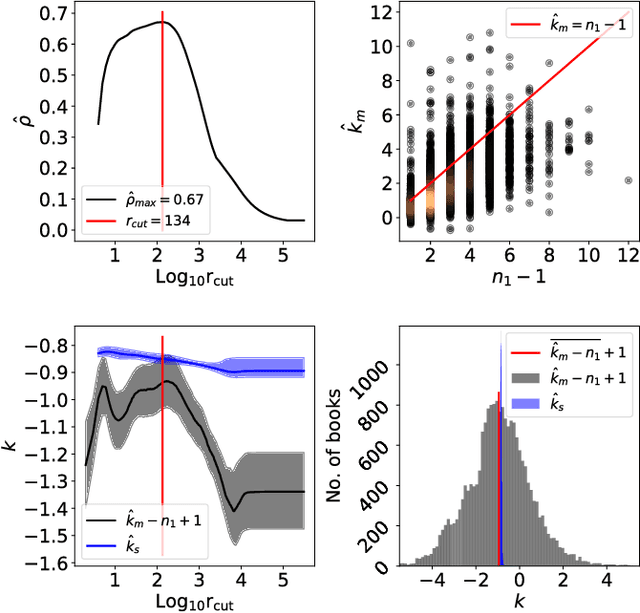
For words, rank-frequency distributions have long been heralded for adherence to a potentially-universal phenomenon known as Zipf's law. The hypothetical form of this empirical phenomenon was refined by Ben\^{i}ot Mandelbrot to that which is presently referred to as the Zipf-Mandelbrot law. Parallel to this, Herbet Simon proposed a selection model potentially explaining Zipf's law. However, a significant dispute between Simon and Mandelbrot, notable empirical exceptions, and the lack of a strong empirical connection between Simon's model and the Zipf-Mandelbrot law have left the questions of universality and mechanistic generation open. We offer a resolution to these issues by exhibiting how the dark matter of word segmentation, i.e., space, punctuation, etc., connect the Zipf-Mandelbrot law to Simon's mechanistic process. This explains Mandelbrot's refinement as no more than a fudge factor, accommodating the effects of the exclusion of the rank-frequency dark matter. Thus, integrating these non-word objects resolves a more-generalized rank-frequency law. Since this relies upon the integration of space, etc., we find support for the hypothesis that $all$ are generated by common processes, indicating from a physical perspective that space is a word, too.
Boundary-based MWE segmentation with text partitioning
Jun 09, 2017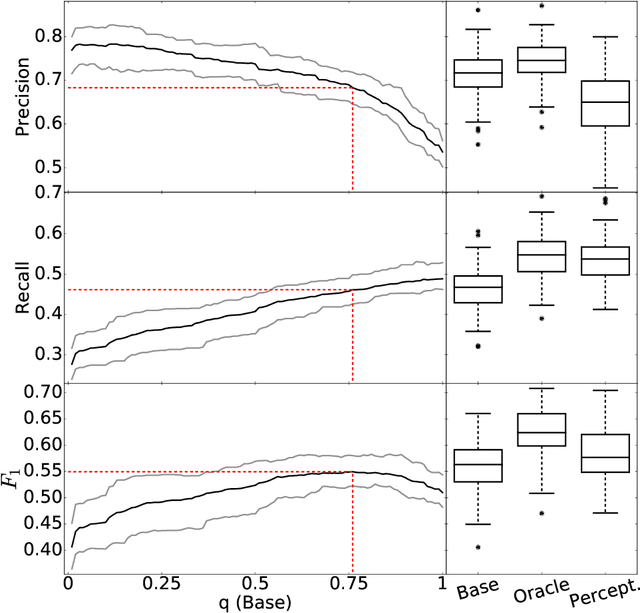
This work presents a fine-grained, text-chunking algorithm designed for the task of multiword expressions (MWEs) segmentation. As a lexical class, MWEs include a wide variety of idioms, whose automatic identification are a necessity for the handling of colloquial language. This algorithm's core novelty is its use of non-word tokens, i.e., boundaries, in a bottom-up strategy. Leveraging boundaries refines token-level information, forging high-level performance from relatively basic data. The generality of this model's feature space allows for its application across languages and domains. Experiments spanning 19 different languages exhibit a broadly-applicable, state-of-the-art model. Evaluation against recent shared-task data places text partitioning as the overall, best performing MWE segmentation algorithm, covering all MWE classes and multiple English domains (including user-generated text). This performance, coupled with a non-combinatorial, fast-running design, produces an ideal combination for implementations at scale, which are facilitated through the release of open-source software.
Benchmarking sentiment analysis methods for large-scale texts: A case for using continuum-scored words and word shift graphs
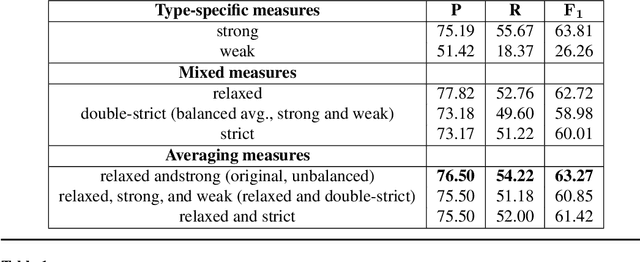
Sep 07, 2016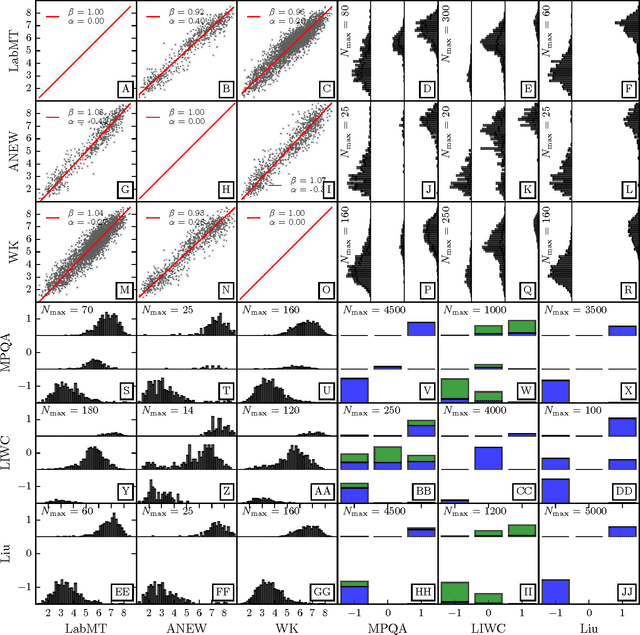
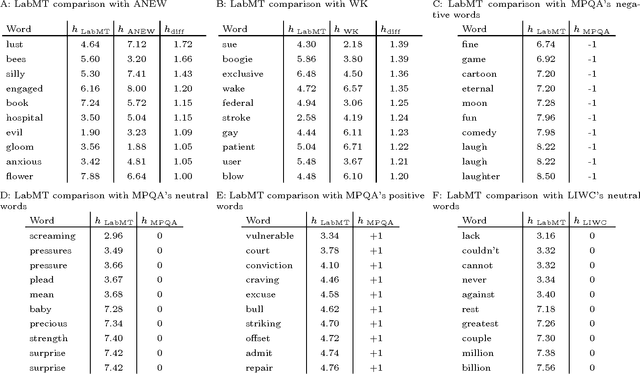
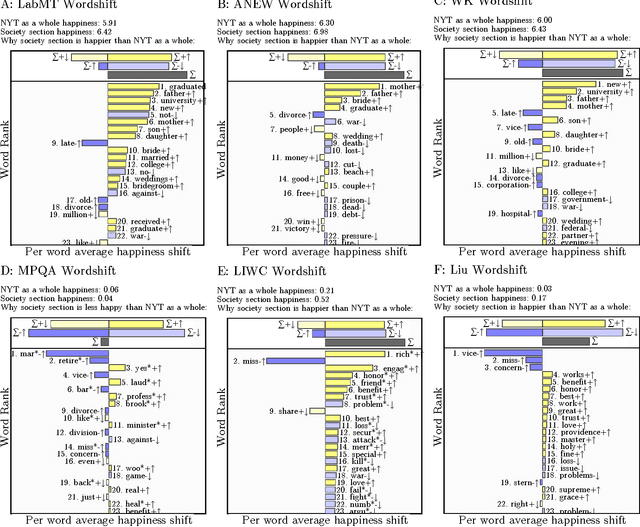
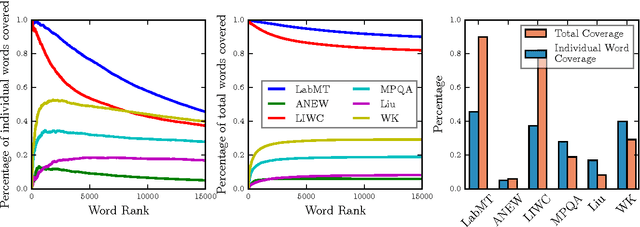
The emergence and global adoption of social media has rendered possible the real-time estimation of population-scale sentiment, bearing profound implications for our understanding of human behavior. Given the growing assortment of sentiment measuring instruments, comparisons between them are evidently required. Here, we perform detailed tests of 6 dictionary-based methods applied to 4 different corpora, and briefly examine a further 20 methods. We show that a dictionary-based method will only perform both reliably and meaningfully if (1) the dictionary covers a sufficiently large enough portion of a given text's lexicon when weighted by word usage frequency; and (2) words are scored on a continuous scale.