 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoundary-based MWE segmentation with text partitioning
Paper and Code
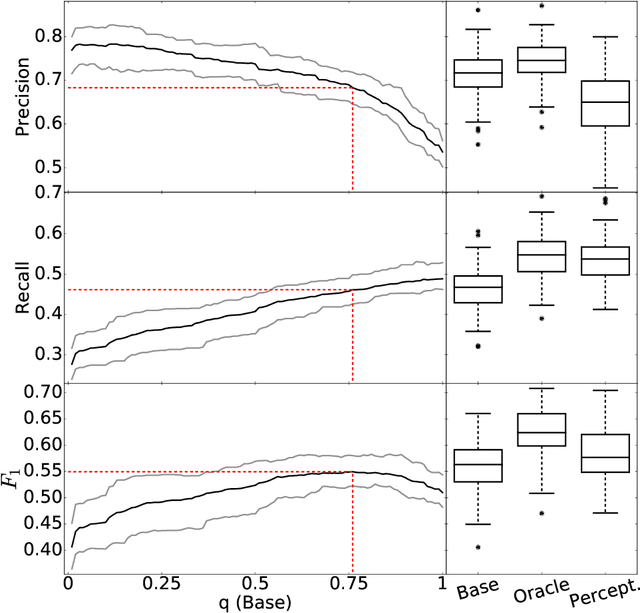
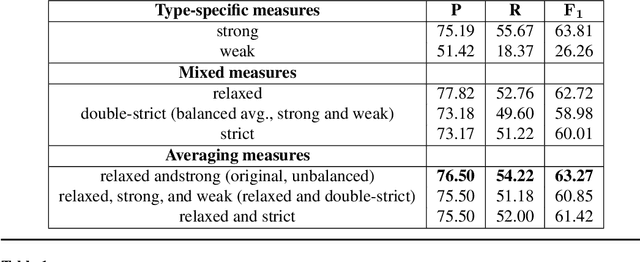
This work presents a fine-grained, text-chunking algorithm designed for the task of multiword expressions (MWEs) segmentation. As a lexical class, MWEs include a wide variety of idioms, whose automatic identification are a necessity for the handling of colloquial language. This algorithm's core novelty is its use of non-word tokens, i.e., boundaries, in a bottom-up strategy. Leveraging boundaries refines token-level information, forging high-level performance from relatively basic data. The generality of this model's feature space allows for its application across languages and domains. Experiments spanning 19 different languages exhibit a broadly-applicable, state-of-the-art model. Evaluation against recent shared-task data places text partitioning as the overall, best performing MWE segmentation algorithm, covering all MWE classes and multiple English domains (including user-generated text). This performance, coupled with a non-combinatorial, fast-running design, produces an ideal combination for implementations at scale, which are facilitated through the release of open-source software.