 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePM-Nav: Priori-Map Guided Embodied Navigation in Functional Buildings
Mar 10, 2026Existing language-driven embodied navigation paradigms face challenges in functional buildings (FBs) with highly similar features, as they lack the ability to effectively utilize priori spatial knowledge. To tackle this issue, we propose a Priori-Map Guided Embodied Navigation (PM-Nav), wherein environmental maps are transformed into navigation-friendly semantic priori-maps, a hierarchical chain-of-thought prompt template with an annotation priori-map is designed to enable precise path planning, and a multi-model collaborative action output mechanism is built to accomplish positioning decisions and execution control for navigation planning. Comprehensive tests using a home-made FB dataset show that the PM-Nav obtains average improvements of 511\% and 1175\%, and 650\% and 400\% over the SG-Nav and the InstructNav in simulation and real-world, respectively. These tremendous boosts elucidate the great potential of using the PM-Nav as a backbone navigation framework for FBs.
ViSA-Enhanced Aerial VLN: A Visual-Spatial Reasoning Enhanced Framework for Aerial Vision-Language Navigation
Mar 09, 2026Existing aerial Vision-Language Navigation (VLN) methods predominantly adopt a detection-and-planning pipeline, which converts open-vocabulary detections into discrete textual scene graphs. These approaches are plagued by inadequate spatial reasoning capabilities and inherent linguistic ambiguities. To address these bottlenecks, we propose a Visual-Spatial Reasoning (ViSA) enhanced framework for aerial VLN. Specifically, a triple-phase collaborative architecture is designed to leverage structured visual prompting, enabling Vision-Language Models (VLMs) to perform direct reasoning on image planes without the need for additional training or complex intermediate representations. Comprehensive evaluations on the CityNav benchmark demonstrate that the ViSA-enhanced VLN achieves a 70.3\% improvement in success rate compared to the fully trained state-of-the-art (SOTA) method, elucidating its great potential as a backbone for aerial VLN systems.
When Is Rank-1 Enough? Geometry-Guided Initialization for Parameter-Efficient Fine-Tuning
Feb 02, 2026Parameter-efficient fine-tuning (PEFT) is a standard way to adapt multimodal large language models, yet extremely low-rank settings -- especially rank-1 LoRA -- are often unstable. We show that this instability is not solely due to limited capacity: in the rank-1 regime, optimization is highly sensitive to the update direction. Concretely, pretrained vision and text features form mismatched anisotropic regions, yielding a dominant "gap" direction that acts like a translation component and disproportionately steers early gradients under rank-1 constraints. Analyzing pretrained representations, we identify a modality-gap axis that dominates early gradient flow, while a random rank-1 initialization is unlikely to align with it, leading to weak gradients and training collapse. We propose Gap-Init, a geometry-aware initialization that aligns the rank-1 LoRA direction with an estimated modality-gap vector from a small calibration set, while keeping the initial LoRA update zero. Across multiple vision-language tasks and backbones, Gap-Init consistently stabilizes rank-1 training and can match or outperform strong rank-8 baselines. Our results suggest that at the extreme low-rank limit, initial alignment can matter as much as rank itself.
SAGE: Semantic-Aware Shared Sampling for Efficient Diffusion
Sep 19, 2025Diffusion models manifest evident benefits across diverse domains, yet their high sampling cost, requiring dozens of sequential model evaluations, remains a major limitation. Prior efforts mainly accelerate sampling via optimized solvers or distillation, which treat each query independently. In contrast, we reduce total number of steps by sharing early-stage sampling across semantically similar queries. To enable such efficiency gains without sacrificing quality, we propose SAGE, a semantic-aware shared sampling framework that integrates a shared sampling scheme for efficiency and a tailored training strategy for quality preservation. Extensive experiments show that SAGE reduces sampling cost by 25.5%, while improving generation quality with 5.0% lower FID, 5.4% higher CLIP, and 160% higher diversity over baselines.
A.S.E: A Repository-Level Benchmark for Evaluating Security in AI-Generated Code
Aug 25, 2025The increasing adoption of large language models (LLMs) in software engineering necessitates rigorous security evaluation of their generated code. However, existing benchmarks are inadequate, as they focus on isolated code snippets, employ unstable evaluation methods that lack reproducibility, and fail to connect the quality of input context with the security of the output. To address these gaps, we introduce A.S.E (AI Code Generation Security Evaluation), a benchmark for repository-level secure code generation. A.S.E constructs tasks from real-world repositories with documented CVEs, preserving full repository context like build systems and cross-file dependencies. Its reproducible, containerized evaluation framework uses expert-defined rules to provide stable, auditable assessments of security, build quality, and generation stability. Our evaluation of leading LLMs on A.S.E reveals three key findings: (1) Claude-3.7-Sonnet achieves the best overall performance. (2) The security gap between proprietary and open-source models is narrow; Qwen3-235B-A22B-Instruct attains the top security score. (3) Concise, ``fast-thinking'' decoding strategies consistently outperform complex, ``slow-thinking'' reasoning for security patching.
SE-VLN: A Self-Evolving Vision-Language Navigation Framework Based on Multimodal Large Language Models
Jul 17, 2025Recent advances in vision-language navigation (VLN) were mainly attributed to emerging large language models (LLMs). These methods exhibited excellent generalization capabilities in instruction understanding and task reasoning. However, they were constrained by the fixed knowledge bases and reasoning abilities of LLMs, preventing fully incorporating experiential knowledge and thus resulting in a lack of efficient evolutionary capacity. To address this, we drew inspiration from the evolution capabilities of natural agents, and proposed a self-evolving VLN framework (SE-VLN) to endow VLN agents with the ability to continuously evolve during testing. To the best of our knowledge, it was the first time that an multimodal LLM-powered self-evolving VLN framework was proposed. Specifically, SE-VLN comprised three core modules, i.e., a hierarchical memory module to transfer successful and failure cases into reusable knowledge, a retrieval-augmented thought-based reasoning module to retrieve experience and enable multi-step decision-making, and a reflection module to realize continual evolution. Comprehensive tests illustrated that the SE-VLN achieved navigation success rates of 57% and 35.2% in unseen environments, representing absolute performance improvements of 23.9% and 15.0% over current state-of-the-art methods on R2R and REVERSE datasets, respectively. Moreover, the SE-VLN showed performance improvement with increasing experience repository, elucidating its great potential as a self-evolving agent framework for VLN.
Comparing human and LLM politeness strategies in free production
Jun 11, 2025



Polite speech poses a fundamental alignment challenge for large language models (LLMs). Humans deploy a rich repertoire of linguistic strategies to balance informational and social goals -- from positive approaches that build rapport (compliments, expressions of interest) to negative strategies that minimize imposition (hedging, indirectness). We investigate whether LLMs employ a similarly context-sensitive repertoire by comparing human and LLM responses in both constrained and open-ended production tasks. We find that larger models ($\ge$70B parameters) successfully replicate key preferences from the computational pragmatics literature, and human evaluators surprisingly prefer LLM-generated responses in open-ended contexts. However, further linguistic analyses reveal that models disproportionately rely on negative politeness strategies even in positive contexts, potentially leading to misinterpretations. While modern LLMs demonstrate an impressive handle on politeness strategies, these subtle differences raise important questions about pragmatic alignment in AI systems.
Let LLMs Break Free from Overthinking via Self-Braking Tuning
May 21, 2025Large reasoning models (LRMs), such as OpenAI o1 and DeepSeek-R1, have significantly enhanced their reasoning capabilities by generating longer chains of thought, demonstrating outstanding performance across a variety of tasks. However, this performance gain comes at the cost of a substantial increase in redundant reasoning during the generation process, leading to high computational overhead and exacerbating the issue of overthinking. Although numerous existing approaches aim to address the problem of overthinking, they often rely on external interventions. In this paper, we propose a novel framework, Self-Braking Tuning (SBT), which tackles overthinking from the perspective of allowing the model to regulate its own reasoning process, thus eliminating the reliance on external control mechanisms. We construct a set of overthinking identification metrics based on standard answers and design a systematic method to detect redundant reasoning. This method accurately identifies unnecessary steps within the reasoning trajectory and generates training signals for learning self-regulation behaviors. Building on this foundation, we develop a complete strategy for constructing data with adaptive reasoning lengths and introduce an innovative braking prompt mechanism that enables the model to naturally learn when to terminate reasoning at an appropriate point. Experiments across mathematical benchmarks (AIME, AMC, MATH500, GSM8K) demonstrate that our method reduces token consumption by up to 60% while maintaining comparable accuracy to unconstrained models.
Building Machine Learning Challenges for Anomaly Detection in Science
Mar 03, 2025



Scientific discoveries are often made by finding a pattern or object that was not predicted by the known rules of science. Oftentimes, these anomalous events or objects that do not conform to the norms are an indication that the rules of science governing the data are incomplete, and something new needs to be present to explain these unexpected outliers. The challenge of finding anomalies can be confounding since it requires codifying a complete knowledge of the known scientific behaviors and then projecting these known behaviors on the data to look for deviations. When utilizing machine learning, this presents a particular challenge since we require that the model not only understands scientific data perfectly but also recognizes when the data is inconsistent and out of the scope of its trained behavior. In this paper, we present three datasets aimed at developing machine learning-based anomaly detection for disparate scientific domains covering astrophysics, genomics, and polar science. We present the different datasets along with a scheme to make machine learning challenges around the three datasets findable, accessible, interoperable, and reusable (FAIR). Furthermore, we present an approach that generalizes to future machine learning challenges, enabling the possibility of large, more compute-intensive challenges that can ultimately lead to scientific discovery.
Non-literal Understanding of Number Words by Language Models
Feb 10, 2025
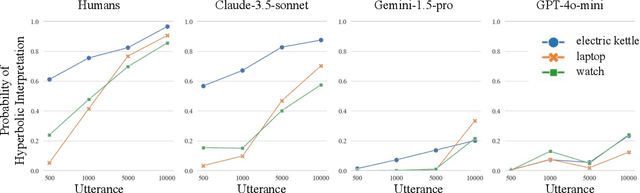

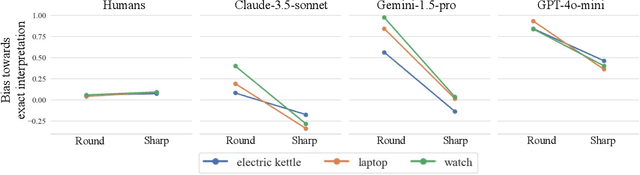
Humans naturally interpret numbers non-literally, effortlessly combining context, world knowledge, and speaker intent. We investigate whether large language models (LLMs) interpret numbers similarly, focusing on hyperbole and pragmatic halo effects. Through systematic comparison with human data and computational models of pragmatic reasoning, we find that LLMs diverge from human interpretation in striking ways. By decomposing pragmatic reasoning into testable components, grounded in the Rational Speech Act framework, we pinpoint where LLM processing diverges from human cognition -- not in prior knowledge, but in reasoning with it. This insight leads us to develop a targeted solution -- chain-of-thought prompting inspired by an RSA model makes LLMs' interpretations more human-like. Our work demonstrates how computational cognitive models can both diagnose AI-human differences and guide development of more human-like language understanding capabilities.