 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexible Cylindrical Array-Aided Secure Wireless Communications
Apr 10, 2026Flexible-geometry arrays based on movable antennas have shown considerable potential for improving wireless communication performance. In this letter, we investigate a multiuser multiple-input single-output (MU-MISO) downlink secure communication system aided by a flexible cylindrical array (FCLA) and artificial noise (AN), where each antenna element rotates along circular tracks while the circular slices move along a vertical axis. To guarantee transmission security, we aim to maximize the achievable sum rate at multiple legitimate information receivers by jointly optimizing transmit beamforming, AN covariance matrix, and antenna placement under secrecy constraints for an eavesdropper. While the resulting problem is intractable to solve, we develop a block coordinate descent (BCD)-based framework that combines the Lagrangian dual transform, tight semidefinite relaxation (SDR), and Nesterov-accelerated projected gradient descent (PGD). Numerical results show that the proposed algorithm converges rapidly and achieves significant sum-rate gains over benchmark schemes by exploiting the geometry flexibility of the array.
PM-Nav: Priori-Map Guided Embodied Navigation in Functional Buildings
Mar 10, 2026Existing language-driven embodied navigation paradigms face challenges in functional buildings (FBs) with highly similar features, as they lack the ability to effectively utilize priori spatial knowledge. To tackle this issue, we propose a Priori-Map Guided Embodied Navigation (PM-Nav), wherein environmental maps are transformed into navigation-friendly semantic priori-maps, a hierarchical chain-of-thought prompt template with an annotation priori-map is designed to enable precise path planning, and a multi-model collaborative action output mechanism is built to accomplish positioning decisions and execution control for navigation planning. Comprehensive tests using a home-made FB dataset show that the PM-Nav obtains average improvements of 511\% and 1175\%, and 650\% and 400\% over the SG-Nav and the InstructNav in simulation and real-world, respectively. These tremendous boosts elucidate the great potential of using the PM-Nav as a backbone navigation framework for FBs.
CMMR-VLN: Vision-and-Language Navigation via Continual Multimodal Memory Retrieval
Mar 09, 2026Although large language models (LLMs) are introduced into vision-and-language navigation (VLN) to improve instruction comprehension and generalization, existing LLM- based VLN lacks the ability to selectively recall and use relevant priori experiences to help navigation tasks, limiting their performance in long-horizon and unfamiliar scenarios. In this work, we propose CMMR-VLN (Continual Multimodal Memory Retrieval based VLN), a VLN framework that endows LLM agents with structured memory and reflection capabilities. Specifically, the CMMR-VLN constructs a multimodal experi- ence memory indexed by panoramic visual images and salient landmarks to retrieve relevant experiences during navigation, introduces a retrieved-augmented generation pipeline to mimick how experienced human navigators leverage priori knowledge, and incorporates a reflection-based memory update strategy that selectively stores complete successful paths and the key initial mistake in failure cases. Comprehensive tests illustrate average success rate improvements of 52.9%, 20.9% and 20.9%, and 200%, 50% and 50% over the NavGPT, the MapGPT, and the DiscussNav in simulation and real tests, respectively eluci- dating the great potential of the CMMR-VLN as a backbone VLN framework.
ViSA-Enhanced Aerial VLN: A Visual-Spatial Reasoning Enhanced Framework for Aerial Vision-Language Navigation
Mar 09, 2026Existing aerial Vision-Language Navigation (VLN) methods predominantly adopt a detection-and-planning pipeline, which converts open-vocabulary detections into discrete textual scene graphs. These approaches are plagued by inadequate spatial reasoning capabilities and inherent linguistic ambiguities. To address these bottlenecks, we propose a Visual-Spatial Reasoning (ViSA) enhanced framework for aerial VLN. Specifically, a triple-phase collaborative architecture is designed to leverage structured visual prompting, enabling Vision-Language Models (VLMs) to perform direct reasoning on image planes without the need for additional training or complex intermediate representations. Comprehensive evaluations on the CityNav benchmark demonstrate that the ViSA-enhanced VLN achieves a 70.3\% improvement in success rate compared to the fully trained state-of-the-art (SOTA) method, elucidating its great potential as a backbone for aerial VLN systems.
SE-VLN: A Self-Evolving Vision-Language Navigation Framework Based on Multimodal Large Language Models
Jul 17, 2025Recent advances in vision-language navigation (VLN) were mainly attributed to emerging large language models (LLMs). These methods exhibited excellent generalization capabilities in instruction understanding and task reasoning. However, they were constrained by the fixed knowledge bases and reasoning abilities of LLMs, preventing fully incorporating experiential knowledge and thus resulting in a lack of efficient evolutionary capacity. To address this, we drew inspiration from the evolution capabilities of natural agents, and proposed a self-evolving VLN framework (SE-VLN) to endow VLN agents with the ability to continuously evolve during testing. To the best of our knowledge, it was the first time that an multimodal LLM-powered self-evolving VLN framework was proposed. Specifically, SE-VLN comprised three core modules, i.e., a hierarchical memory module to transfer successful and failure cases into reusable knowledge, a retrieval-augmented thought-based reasoning module to retrieve experience and enable multi-step decision-making, and a reflection module to realize continual evolution. Comprehensive tests illustrated that the SE-VLN achieved navigation success rates of 57% and 35.2% in unseen environments, representing absolute performance improvements of 23.9% and 15.0% over current state-of-the-art methods on R2R and REVERSE datasets, respectively. Moreover, the SE-VLN showed performance improvement with increasing experience repository, elucidating its great potential as a self-evolving agent framework for VLN.
Chi-Square Wavelet Graph Neural Networks for Heterogeneous Graph Anomaly Detection
May 25, 2025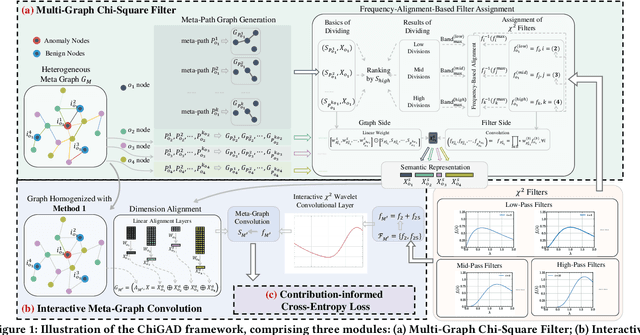
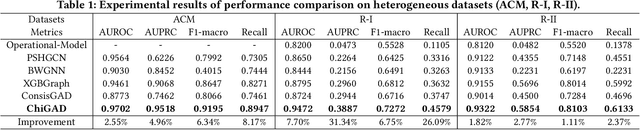
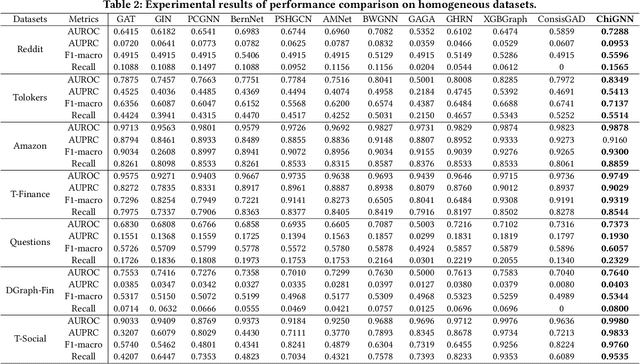
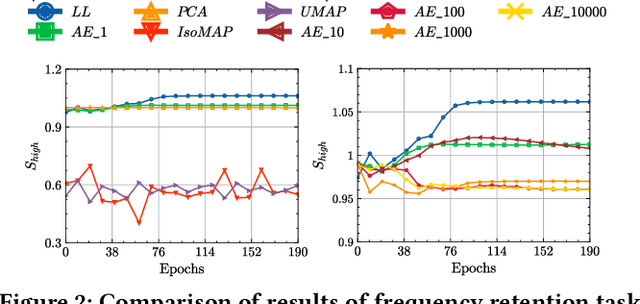
Graph Anomaly Detection (GAD) in heterogeneous networks presents unique challenges due to node and edge heterogeneity. Existing Graph Neural Network (GNN) methods primarily focus on homogeneous GAD and thus fail to address three key issues: (C1) Capturing abnormal signal and rich semantics across diverse meta-paths; (C2) Retaining high-frequency content in HIN dimension alignment; and (C3) Learning effectively from difficult anomaly samples with class imbalance. To overcome these, we propose ChiGAD, a spectral GNN framework based on a novel Chi-Square filter, inspired by the wavelet effectiveness in diverse domains. Specifically, ChiGAD consists of: (1) Multi-Graph Chi-Square Filter, which captures anomalous information via applying dedicated Chi-Square filters to each meta-path graph; (2) Interactive Meta-Graph Convolution, which aligns features while preserving high-frequency information and incorporates heterogeneous messages by a unified Chi-Square Filter; and (3) Contribution-Informed Cross-Entropy Loss, which prioritizes difficult anomalies to address class imbalance. Extensive experiments on public and industrial datasets show that ChiGAD outperforms state-of-the-art models on multiple metrics. Additionally, its homogeneous variant, ChiGNN, excels on seven GAD datasets, validating the effectiveness of Chi-Square filters. Our code is available at https://github.com/HsipingLi/ChiGAD.
SpaceGNN: Multi-Space Graph Neural Network for Node Anomaly Detection with Extremely Limited Labels
Feb 05, 2025



Node Anomaly Detection (NAD) has gained significant attention in the deep learning community due to its diverse applications in real-world scenarios. Existing NAD methods primarily embed graphs within a single Euclidean space, while overlooking the potential of non-Euclidean spaces. Besides, to address the prevalent issue of limited supervision in real NAD tasks, previous methods tend to leverage synthetic data to collect auxiliary information, which is not an effective solution as shown in our experiments. To overcome these challenges, we introduce a novel SpaceGNN model designed for NAD tasks with extremely limited labels. Specifically, we provide deeper insights into a task-relevant framework by empirically analyzing the benefits of different spaces for node representations, based on which, we design a Learnable Space Projection function that effectively encodes nodes into suitable spaces. Besides, we introduce the concept of weighted homogeneity, which we empirically and theoretically validate as an effective coefficient during information propagation. This concept inspires the design of the Distance Aware Propagation module. Furthermore, we propose the Multiple Space Ensemble module, which extracts comprehensive information for NAD under conditions of extremely limited supervision. Our findings indicate that this module is more beneficial than data augmentation techniques for NAD. Extensive experiments conducted on 9 real datasets confirm the superiority of SpaceGNN, which outperforms the best rival by an average of 8.55% in AUC and 4.31% in F1 scores. Our code is available at https://github.com/xydong127/SpaceGNN.
Flexible Cylindrical Arrays with Movable Antennas for MISO System: Beamforming and Position Optimization
Jan 25, 2025



As wireless communication advances toward the 6G era, the demand for ultra-reliable, high-speed, and ubiquitous connectivity is driving the exploration of new degrees-of-freedom (DoFs) in communication systems. Among the key enabling technologies, Movable Antennas (MAs) integrated into Flexible Cylindrical Arrays (FCLA) have shown great potential in optimizing wireless communication by providing spatial flexibility. This paper proposes an innovative optimization framework that leverages the dynamic mobility of FCLAs to improve communication rates and overall system performance. By employing Fractional Programming (FP) for alternating optimization of beamforming and antenna positions, the system enhances throughput and resource utilization. Additionally, a novel Constrained Grid Search-Based Adaptive Moment Estimation Algorithm (CGS-Adam) is introduced to optimize antenna positions while adhering to antenna spacing constraints. Extensive simulations validate that the proposed system, utilizing movable antennas, significantly outperforms traditional fixed antenna optimization, achieving up to a 31\% performance gain in general scenarios. The integration of FCLAs in wireless networks represents a promising solution for future 6G systems, offering improved coverage, energy efficiency, and flexibility.
SmoothGNN: Smoothing-based GNN for Unsupervised Node Anomaly Detection
May 27, 2024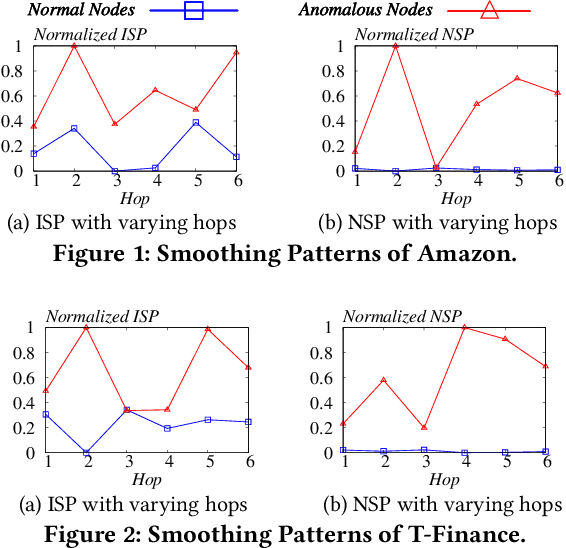
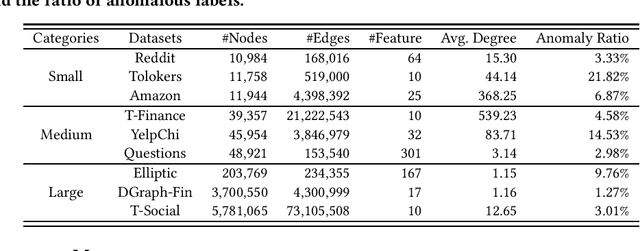
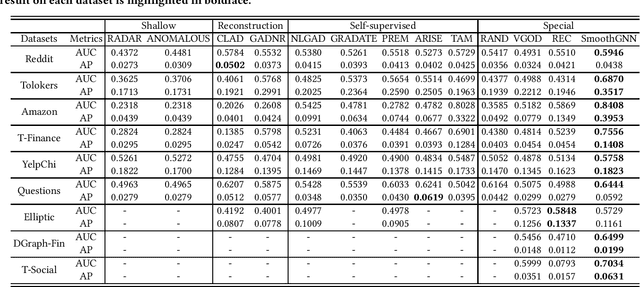
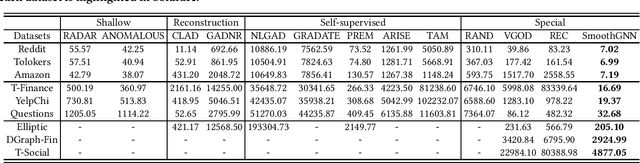
The smoothing issue leads to indistinguishable node representations, which poses a significant challenge in the field of graph learning. However, this issue also presents an opportunity to reveal underlying properties behind different types of nodes, which have been overlooked in previous studies. Through empirical and theoretical analysis of real-world node anomaly detection (NAD) datasets, we observe that anomalous and normal nodes show different patterns in the smoothing process, which can be leveraged to enhance NAD tasks. Motivated by these findings, in this paper, we propose a novel unsupervised NAD framework. Specifically, according to our theoretical analysis, we design a Smoothing Learning Component. Subsequently, we introduce a Smoothing-aware Spectral Graph Neural Network, which establishes the connection between the spectral space of graphs and the smoothing process. Additionally, we demonstrate that the Dirichlet Energy, which reflects the smoothness of a graph, can serve as coefficients for node representations across different dimensions of the spectral space. Building upon these observations and analyses, we devise a novel anomaly measure for the NAD task. Extensive experiments on 9 real-world datasets show that SmoothGNN outperforms the best rival by an average of 14.66% in AUC and 7.28% in Precision, with 75x running time speed-up, which validates the effectiveness and efficiency of our framework.
KPG: Key Propagation Graph Generator for Rumor Detection based on Reinforcement Learning
May 21, 2024The proliferation of rumors on social media platforms during significant events, such as the US elections and the COVID-19 pandemic, has a profound impact on social stability and public health. Existing approaches for rumor detection primarily rely on propagation graphs to enhance model effectiveness. However, the presence of noisy and irrelevant structures during the propagation process limits the efficacy of these approaches. To tackle this issue, techniques such as weight adjustment and data augmentation have been proposed. However, these techniques heavily depend on rich original propagation structures, thus hindering performance when dealing with rumors that lack sufficient propagation information in the early propagation stages. In this paper, we propose Key Propagation Graph Generator (KPG), a novel reinforcement learning-based rumor detection framework that generates contextually coherent and informative propagation patterns for events with insufficient topology information, while also identifies indicative substructures for events with redundant and noisy propagation structures. KPG consists of two key components: the Candidate Response Generator (CRG) and the Ending Node Selector (ENS). CRG learns the latent distribution from refined propagation patterns, filtering out noise and generating new candidates for ENS. Simultaneously, ENS identifies the most influential substructures within propagation graphs and generates training data for CRG. Moreover, we introduce an end-to-end framework that utilizes rewards to guide the entire training process via a pre-trained graph neural network. Extensive experiments conducted on four datasets demonstrate the superiority of our KPG compared to the state-of-the-art approaches.