 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTEA-Bench: A Systematic Benchmarking of Tool-enhanced Emotional Support Dialogue Agent
Jan 26, 2026Emotional Support Conversation requires not only affective expression but also grounded instrumental support to provide trustworthy guidance. However, existing ESC systems and benchmarks largely focus on affective support in text-only settings, overlooking how external tools can enable factual grounding and reduce hallucination in multi-turn emotional support. We introduce TEA-Bench, the first interactive benchmark for evaluating tool-augmented agents in ESC, featuring realistic emotional scenarios, an MCP-style tool environment, and process-level metrics that jointly assess the quality and factual grounding of emotional support. Experiments on nine LLMs show that tool augmentation generally improves emotional support quality and reduces hallucination, but the gains are strongly capacity-dependent: stronger models use tools more selectively and effectively, while weaker models benefit only marginally. We further release TEA-Dialog, a dataset of tool-enhanced ESC dialogues, and find that supervised fine-tuning improves in-distribution support but generalizes poorly. Our results underscore the importance of tool use in building reliable emotional support agents.
When Personalization Legitimizes Risks: Uncovering Safety Vulnerabilities in Personalized Dialogue Agents
Jan 25, 2026Long-term memory enables large language model (LLM) agents to support personalized and sustained interactions. However, most work on personalized agents prioritizes utility and user experience, treating memory as a neutral component and largely overlooking its safety implications. In this paper, we reveal intent legitimation, a previously underexplored safety failure in personalized agents, where benign personal memories bias intent inference and cause models to legitimize inherently harmful queries. To study this phenomenon, we introduce PS-Bench, a benchmark designed to identify and quantify intent legitimation in personalized interactions. Across multiple memory-augmented agent frameworks and base LLMs, personalization increases attack success rates by 15.8%-243.7% relative to stateless baselines. We further provide mechanistic evidence for intent legitimation from internal representations space, and propose a lightweight detection-reflection method that effectively reduces safety degradation. Overall, our work provides the first systematic exploration and evaluation of intent legitimation as a safety failure mode that naturally arises from benign, real-world personalization, highlighting the importance of assessing safety under long-term personal context. WARNING: This paper may contain harmful content.
OP-Bench: Benchmarking Over-Personalization for Memory-Augmented Personalized Conversational Agents
Jan 20, 2026Memory-augmented conversational agents enable personalized interactions using long-term user memory and have gained substantial traction. However, existing benchmarks primarily focus on whether agents can recall and apply user information, while overlooking whether such personalization is used appropriately. In fact, agents may overuse personal information, producing responses that feel forced, intrusive, or socially inappropriate to users. We refer to this issue as \emph{over-personalization}. In this work, we formalize over-personalization into three types: Irrelevance, Repetition, and Sycophancy, and introduce \textbf{OP-Bench} a benchmark of 1,700 verified instances constructed from long-horizon dialogue histories. Using \textbf{OP-Bench}, we evaluate multiple large language models and memory-augmentation methods, and find that over-personalization is widespread when memory is introduced. Further analysis reveals that agents tend to retrieve and over-attend to user memories even when unnecessary. To address this issue, we propose \textbf{Self-ReCheck}, a lightweight, model-agnostic memory filtering mechanism that mitigates over-personalization while preserving personalization performance. Our work takes an initial step toward more controllable and appropriate personalization in memory-augmented dialogue systems.
Streaming 4D Visual Geometry Transformer
Jul 15, 2025

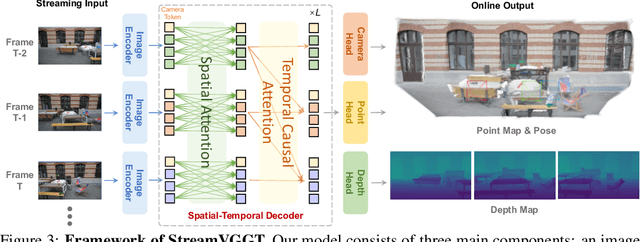

Perceiving and reconstructing 4D spatial-temporal geometry from videos is a fundamental yet challenging computer vision task. To facilitate interactive and real-time applications, we propose a streaming 4D visual geometry transformer that shares a similar philosophy with autoregressive large language models. We explore a simple and efficient design and employ a causal transformer architecture to process the input sequence in an online manner. We use temporal causal attention and cache the historical keys and values as implicit memory to enable efficient streaming long-term 4D reconstruction. This design can handle real-time 4D reconstruction by incrementally integrating historical information while maintaining high-quality spatial consistency. For efficient training, we propose to distill knowledge from the dense bidirectional visual geometry grounded transformer (VGGT) to our causal model. For inference, our model supports the migration of optimized efficient attention operator (e.g., FlashAttention) from the field of large language models. Extensive experiments on various 4D geometry perception benchmarks demonstrate that our model increases the inference speed in online scenarios while maintaining competitive performance, paving the way for scalable and interactive 4D vision systems. Code is available at: https://github.com/wzzheng/StreamVGGT.
Exploring and Exploiting the Inherent Efficiency within Large Reasoning Models for Self-Guided Efficiency Enhancement
Jun 18, 2025Recent advancements in large reasoning models (LRMs) have significantly enhanced language models' capabilities in complex problem-solving by emulating human-like deliberative thinking. However, these models often exhibit overthinking (i.e., the generation of unnecessarily verbose and redundant content), which hinders efficiency and inflates inference cost. In this work, we explore the representational and behavioral origins of this inefficiency, revealing that LRMs inherently possess the capacity for more concise reasoning. Empirical analyses show that correct reasoning paths vary significantly in length, and the shortest correct responses often suffice, indicating untapped efficiency potential. Exploiting these findings, we propose two lightweight methods to enhance LRM efficiency. First, we introduce Efficiency Steering, a training-free activation steering technique that modulates reasoning behavior via a single direction in the model's representation space. Second, we develop Self-Rewarded Efficiency RL, a reinforcement learning framework that dynamically balances task accuracy and brevity by rewarding concise correct solutions. Extensive experiments on seven LRM backbones across multiple mathematical reasoning benchmarks demonstrate that our methods significantly reduce reasoning length while preserving or improving task performance. Our results highlight that reasoning efficiency can be improved by leveraging and guiding the intrinsic capabilities of existing models in a self-guided manner.
MPO: Multilingual Safety Alignment via Reward Gap Optimization
May 22, 2025Large language models (LLMs) have become increasingly central to AI applications worldwide, necessitating robust multilingual safety alignment to ensure secure deployment across diverse linguistic contexts. Existing preference learning methods for safety alignment, such as RLHF and DPO, are primarily monolingual and struggle with noisy multilingual data. To address these limitations, we introduce Multilingual reward gaP Optimization (MPO), a novel approach that leverages the well-aligned safety capabilities of the dominant language (English) to improve safety alignment across multiple languages. MPO directly minimizes the reward gap difference between the dominant language and target languages, effectively transferring safety capabilities while preserving the original strengths of the dominant language. Extensive experiments on three LLMs, LLaMA-3.1, Gemma-2 and Qwen2.5, validate MPO's efficacy in multilingual safety alignment without degrading general multilingual utility.
When Less Language is More: Language-Reasoning Disentanglement Makes LLMs Better Multilingual Reasoners
May 21, 2025Multilingual reasoning remains a significant challenge for large language models (LLMs), with performance disproportionately favoring high-resource languages. Drawing inspiration from cognitive neuroscience, which suggests that human reasoning functions largely independently of language processing, we hypothesize that LLMs similarly encode reasoning and language as separable components that can be disentangled to enhance multilingual reasoning. To evaluate this, we perform a causal intervention by ablating language-specific representations at inference time. Experiments on 10 open-source LLMs spanning 11 typologically diverse languages show that this language-specific ablation consistently boosts multilingual reasoning performance. Layer-wise analyses further confirm that language and reasoning representations can be effectively decoupled throughout the model, yielding improved multilingual reasoning capabilities, while preserving top-layer language features remains essential for maintaining linguistic fidelity. Compared to post-training such as supervised fine-tuning or reinforcement learning, our training-free ablation achieves comparable or superior results with minimal computational overhead. These findings shed light on the internal mechanisms underlying multilingual reasoning in LLMs and suggest a lightweight and interpretable strategy for improving cross-lingual generalization.
Teaching Language Models to Evolve with Users: Dynamic Profile Modeling for Personalized Alignment
May 21, 2025
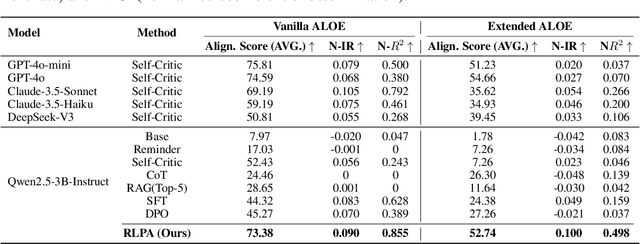
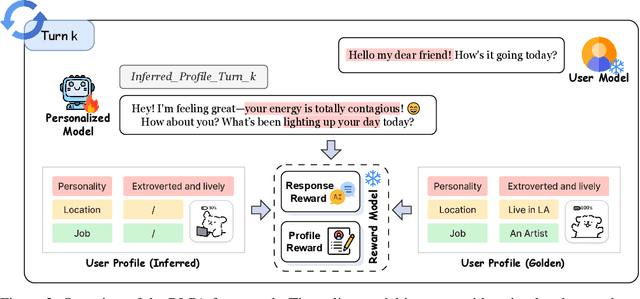

Personalized alignment is essential for enabling large language models (LLMs) to engage effectively in user-centric dialogue. While recent prompt-based and offline optimization methods offer preliminary solutions, they fall short in cold-start scenarios and long-term personalization due to their inherently static and shallow designs. In this work, we introduce the Reinforcement Learning for Personalized Alignment (RLPA) framework, in which an LLM interacts with a simulated user model to iteratively infer and refine user profiles through dialogue. The training process is guided by a dual-level reward structure: the Profile Reward encourages accurate construction of user representations, while the Response Reward incentivizes generation of responses consistent with the inferred profile. We instantiate RLPA by fine-tuning Qwen-2.5-3B-Instruct, resulting in Qwen-RLPA, which achieves state-of-the-art performance in personalized dialogue. Empirical evaluations demonstrate that Qwen-RLPA consistently outperforms prompting and offline fine-tuning baselines, and even surpasses advanced commercial models such as Claude-3.5 and GPT-4o. Further analysis highlights Qwen-RLPA's robustness in reconciling conflicting user preferences, sustaining long-term personalization and delivering more efficient inference compared to recent reasoning-focused LLMs. These results emphasize the potential of dynamic profile inference as a more effective paradigm for building personalized dialogue systems.
AdaSteer: Your Aligned LLM is Inherently an Adaptive Jailbreak Defender
Apr 13, 2025Despite extensive efforts in safety alignment, large language models (LLMs) remain vulnerable to jailbreak attacks. Activation steering offers a training-free defense method but relies on fixed steering coefficients, resulting in suboptimal protection and increased false rejections of benign inputs. To address this, we propose AdaSteer, an adaptive activation steering method that dynamically adjusts model behavior based on input characteristics. We identify two key properties: Rejection Law (R-Law), which shows that stronger steering is needed for jailbreak inputs opposing the rejection direction, and Harmfulness Law (H-Law), which differentiates adversarial and benign inputs. AdaSteer steers input representations along both the Rejection Direction (RD) and Harmfulness Direction (HD), with adaptive coefficients learned via logistic regression, ensuring robust jailbreak defense while preserving benign input handling. Experiments on LLaMA-3.1, Gemma-2, and Qwen2.5 show that AdaSteer outperforms baseline methods across multiple jailbreak attacks with minimal impact on utility. Our results highlight the potential of interpretable model internals for real-time, flexible safety enforcement in LLMs.
Modeling and Optimization for Flexible Cylindrical Arrays-Enabled Wireless Communications
Mar 14, 2025Flexible-geometry arrays have garnered much attention in wireless communications, which dynamically adjust wireless channels to improve the system performance. In this paper, we propose a novel flexible-geometry array for a $360^\circ$ coverage, named flxible cylindrical array (FCLA), comprised of multiple flexible circular arrays (FCAs). The elements in each FCA can revolve around the circle track to change their horizontal positions, and the FCAs can move along the vertical axis to change the elements' heights. Considering that horizontal revolving can change the antenna orientation, we adopt both the omni-directional and the directional antenna patterns. Based on the regularized zero-forcing (RZF) precoding scheme, we formulate a particular compressive sensing (CS) problem incorporating joint precoding and antenna position optimization, and propose two effective methods, namely FCLA-J and FCLA-A, to solve it. Specifically, the first method involves jointly optimizing the element's revolving angle, height, and precoding coefficient within a single CS framework. The second method decouples the CS problem into two subproblems by utilizing an alternative sparse optimization approach for the revolving angle and height, thereby reducing time complexity. Simulation results reveal that, when utilizing directional radiation patterns, FCLA-J and FCLA-A achieve substantial performance improvements of 43.32\% and 25.42\%, respectively, compared to uniform cylindrical arrays (UCLAs) with RZF precoding.