 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiscale Switch for Semi-Supervised and Contrastive Learning in Medical Ultrasound Image Segmentation
Mar 19, 2026Medical ultrasound image segmentation faces significant challenges due to limited labeled data and characteristic imaging artifacts including speckle noise and low-contrast boundaries. While semi-supervised learning (SSL) approaches have emerged to address data scarcity, existing methods suffer from suboptimal unlabeled data utilization and lack robust feature representation mechanisms. In this paper, we propose Switch, a novel SSL framework with two key innovations: (1) Multiscale Switch (MSS) strategy that employs hierarchical patch mixing to achieve uniform spatial coverage; (2) Frequency Domain Switch (FDS) with contrastive learning that performs amplitude switching in Fourier space for robust feature representations. Our framework integrates these components within a teacher-student architecture to effectively leverage both labeled and unlabeled data. Comprehensive evaluation across six diverse ultrasound datasets (lymph nodes, breast lesions, thyroid nodules, and prostate) demonstrates consistent superiority over state-of-the-art methods. At 5\% labeling ratio, Switch achieves remarkable improvements: 80.04\% Dice on LN-INT, 85.52\% Dice on DDTI, and 83.48\% Dice on Prostate datasets, with our semi-supervised approach even exceeding fully supervised baselines. The method maintains parameter efficiency (1.8M parameters) while delivering superior performance, validating its effectiveness for resource-constrained medical imaging applications. The source code is publicly available at https://github.com/jinggqu/Switch
Adapting Vision-Language Foundation Model for Next Generation Medical Ultrasound Image Analysis
Jun 11, 2025Medical ultrasonography is an essential imaging technique for examining superficial organs and tissues, including lymph nodes, breast, and thyroid. It employs high-frequency ultrasound waves to generate detailed images of the internal structures of the human body. However, manually contouring regions of interest in these images is a labor-intensive task that demands expertise and often results in inconsistent interpretations among individuals. Vision-language foundation models, which have excelled in various computer vision applications, present new opportunities for enhancing ultrasound image analysis. Yet, their performance is hindered by the significant differences between natural and medical imaging domains. This research seeks to overcome these challenges by developing domain adaptation methods for vision-language foundation models. In this study, we explore the fine-tuning pipeline for vision-language foundation models by utilizing large language model as text refiner with special-designed adaptation strategies and task-driven heads. Our approach has been extensively evaluated on six ultrasound datasets and two tasks: segmentation and classification. The experimental results show that our method can effectively improve the performance of vision-language foundation models for ultrasound image analysis, and outperform the existing state-of-the-art vision-language and pure foundation models. The source code of this study is available at https://github.com/jinggqu/NextGen-UIA.
The Application of Deep Learning for Lymph Node Segmentation: A Systematic Review
May 09, 2025Automatic lymph node segmentation is the cornerstone for advances in computer vision tasks for early detection and staging of cancer. Traditional segmentation methods are constrained by manual delineation and variability in operator proficiency, limiting their ability to achieve high accuracy. The introduction of deep learning technologies offers new possibilities for improving the accuracy of lymph node image analysis. This study evaluates the application of deep learning in lymph node segmentation and discusses the methodologies of various deep learning architectures such as convolutional neural networks, encoder-decoder networks, and transformers in analyzing medical imaging data across different modalities. Despite the advancements, it still confronts challenges like the shape diversity of lymph nodes, the scarcity of accurately labeled datasets, and the inadequate development of methods that are robust and generalizable across different imaging modalities. To the best of our knowledge, this is the first study that provides a comprehensive overview of the application of deep learning techniques in lymph node segmentation task. Furthermore, this study also explores potential future research directions, including multimodal fusion techniques, transfer learning, and the use of large-scale pre-trained models to overcome current limitations while enhancing cancer diagnosis and treatment planning strategies.
AdaSteer: Your Aligned LLM is Inherently an Adaptive Jailbreak Defender
Apr 13, 2025Despite extensive efforts in safety alignment, large language models (LLMs) remain vulnerable to jailbreak attacks. Activation steering offers a training-free defense method but relies on fixed steering coefficients, resulting in suboptimal protection and increased false rejections of benign inputs. To address this, we propose AdaSteer, an adaptive activation steering method that dynamically adjusts model behavior based on input characteristics. We identify two key properties: Rejection Law (R-Law), which shows that stronger steering is needed for jailbreak inputs opposing the rejection direction, and Harmfulness Law (H-Law), which differentiates adversarial and benign inputs. AdaSteer steers input representations along both the Rejection Direction (RD) and Harmfulness Direction (HD), with adaptive coefficients learned via logistic regression, ensuring robust jailbreak defense while preserving benign input handling. Experiments on LLaMA-3.1, Gemma-2, and Qwen2.5 show that AdaSteer outperforms baseline methods across multiple jailbreak attacks with minimal impact on utility. Our results highlight the potential of interpretable model internals for real-time, flexible safety enforcement in LLMs.
Chain of Strategy Optimization Makes Large Language Models Better Emotional Supporter
Mar 07, 2025The growing emotional stress in modern society has increased the demand for Emotional Support Conversations (ESC). While Large Language Models (LLMs) show promise for ESC, they face two key challenges: (1) low strategy selection accuracy, and (2) preference bias, limiting their adaptability to emotional needs of users. Existing supervised fine-tuning (SFT) struggles to address these issues, as it rigidly trains models on single gold-standard responses without modeling nuanced strategy trade-offs. To overcome these limitations, we propose Chain-of-Strategy Optimization (CSO), a novel approach that optimizes strategy selection preferences at each dialogue turn. We first leverage Monte Carlo Tree Search to construct ESC-Pro, a high-quality preference dataset with turn-level strategy-response pairs. Training on ESC-Pro with CSO improves both strategy accuracy and bias mitigation, enabling LLMs to generate more empathetic and contextually appropriate responses. Experiments on LLaMA-3.1-8B, Gemma-2-9B, and Qwen2.5-7B demonstrate that CSO outperforms standard SFT, highlighting the efficacy of fine-grained, turn-level preference modeling in ESC.
Beware of Your Po! Measuring and Mitigating AI Safety Risks in Role-Play Fine-Tuning of LLMs
Feb 28, 2025Role-playing enables large language models (LLMs) to engage users in immersive and personalized interactions, but it also introduces significant safety risks. Existing role-play fine-tuning techniques improve role adaptability but may degrade safety performance, particularly for villainous characters. In this work, we conduct the first comprehensive assessment of role-play fine-tuning risks by training 95 role-specific LLMs using RoleBench. Our experiments reveal that role-play fine-tuning leads to a noticeable decline in safety performance, with safety risks varying based on character traits. To tackle this challenge, we propose Safety-Aware Role-Play Fine-Tuning (SaRFT), a novel method designed to balance role-playing capabilities and safety. Extensive experiments on LLaMA-3-8B-Instruct, Gemma-2-9B-it, and Qwen2.5-7B-Instruct demonstrate that SaRFT consistently outperforms state-of-the-art baselines under both LoRA and full-parameter fine-tuning settings. Our findings highlight the necessity of role-adaptive safety measures and provide insights into mitigating role-specific safety risks in role-playing LLMs.
Calibration of Multiple Asynchronous Microphone Arrays using Hybrid TDOA
Feb 10, 2025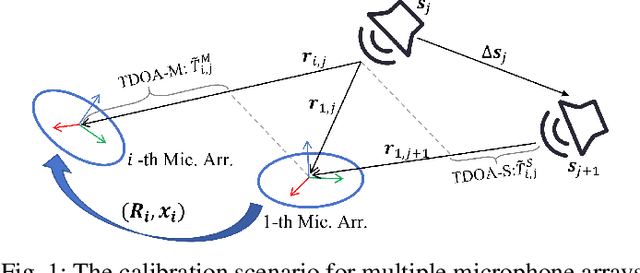
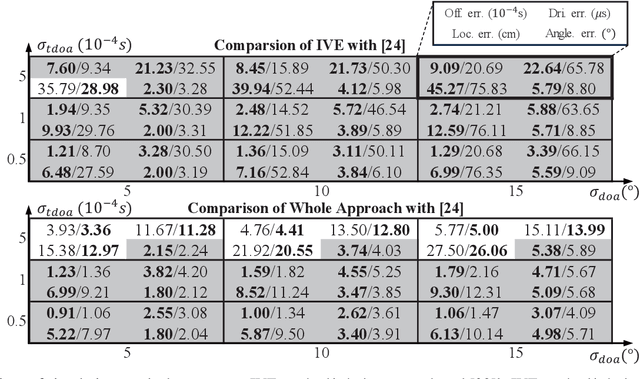


Accurate calibration of acoustic sensing systems made of multiple asynchronous microphone arrays is essential for satisfactory performance in sound source localization and tracking. State-of-the-art calibration methods for this type of system rely on the time difference of arrival and direction of arrival measurements among the microphone arrays (denoted as TDOA-M and DOA, respectively). In this paper, to enhance calibration accuracy, we propose to incorporate the time difference of arrival measurements between adjacent sound events (TDOAS) with respect to the microphone arrays. More specifically, we propose a two-stage calibration approach, including an initial value estimation (IVE) procedure and the final joint optimization step. The IVE stage first initializes all parameters except for microphone array orientations, using hybrid TDOA (i.e., TDOAM and TDOA-S), odometer data from a moving robot carrying a speaker, and DOA. Subsequently, microphone orientations are estimated through the iterative closest point method. The final joint optimization step estimates multiple microphone array locations, orientations, time offsets, clock drift rates, and sound source locations simultaneously. Both simulation and experiment results show that for scenarios with low or moderate TDOA noise levels, our approach outperforms existing methods in terms of accuracy. All code and data are available at https://github.com/AISLABsustech/Hybrid-TDOA-Multi-Calib.
Optimal Sensor Placement for TDOA-Based Source Localization with Sensor Location Errors
Oct 28, 2024


The accuracy of time difference of arrival (TDOA)-based source localization is influenced by sensor location deployment. Many studies focus on optimal sensor placement (OSP) for TDOA-based localization without sensor location noises (OSP-WSLN). In practice, there are sensor location errors due to installation deviations, etc, which implies the necessity of studying OSP under sensor location noises (OSP-SLN). There are two fundamental problems: What is the OSP-SLN strategy? To what extent do sensor location errors affect the performance of OSP-SLN? For the first one, under the assumption of the near-field and full set of TDOA, minimizing the trace of the Cramer-Rao bound is used as optimization criteria. Based on this, a concise equality, namely Eq. (18), is proven to show that OSP-SLN is equivalent to OSP-WSLN. Extensive simulations validate both equality and equivalence and respond to the second problem: not large sensor position errors give an ignorable negative impact on the performance of OSP-SLN quantified by the trace of CRB. Also, simulations show source localization accuracy with OSP-SLN outperforms that with random placement. These simulations validate our derived OSP-SLN and its effectiveness. We have open-sourced the code for community use.
The More You See in 2D, the More You Perceive in 3D
Apr 04, 2024



Humans can infer 3D structure from 2D images of an object based on past experience and improve their 3D understanding as they see more images. Inspired by this behavior, we introduce SAP3D, a system for 3D reconstruction and novel view synthesis from an arbitrary number of unposed images. Given a few unposed images of an object, we adapt a pre-trained view-conditioned diffusion model together with the camera poses of the images via test-time fine-tuning. The adapted diffusion model and the obtained camera poses are then utilized as instance-specific priors for 3D reconstruction and novel view synthesis. We show that as the number of input images increases, the performance of our approach improves, bridging the gap between optimization-based prior-less 3D reconstruction methods and single-image-to-3D diffusion-based methods. We demonstrate our system on real images as well as standard synthetic benchmarks. Our ablation studies confirm that this adaption behavior is key for more accurate 3D understanding.
Unsupervised Universal Image Segmentation
Dec 28, 2023



Several unsupervised image segmentation approaches have been proposed which eliminate the need for dense manually-annotated segmentation masks; current models separately handle either semantic segmentation (e.g., STEGO) or class-agnostic instance segmentation (e.g., CutLER), but not both (i.e., panoptic segmentation). We propose an Unsupervised Universal Segmentation model (U2Seg) adept at performing various image segmentation tasks -- instance, semantic and panoptic -- using a novel unified framework. U2Seg generates pseudo semantic labels for these segmentation tasks via leveraging self-supervised models followed by clustering; each cluster represents different semantic and/or instance membership of pixels. We then self-train the model on these pseudo semantic labels, yielding substantial performance gains over specialized methods tailored to each task: a +2.6 AP$^{\text{box}}$ boost vs. CutLER in unsupervised instance segmentation on COCO and a +7.0 PixelAcc increase (vs. STEGO) in unsupervised semantic segmentation on COCOStuff. Moreover, our method sets up a new baseline for unsupervised panoptic segmentation, which has not been previously explored. U2Seg is also a strong pretrained model for few-shot segmentation, surpassing CutLER by +5.0 AP$^{\text{mask}}$ when trained on a low-data regime, e.g., only 1% COCO labels. We hope our simple yet effective method can inspire more research on unsupervised universal image segmentation.