 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet's Think with Images Efficiently! An Interleaved-Modal Chain-of-Thought Reasoning Framework with Dynamic and Precise Visual Thoughts
Mar 23, 2026Recently, Interleaved-modal Chain-of-Thought (ICoT) reasoning has achieved remarkable success by leveraging both multimodal inputs and outputs, attracting increasing attention. While achieving promising performance, current ICoT methods still suffer from two major limitations: (1) Static Visual Thought Positioning, which statically inserts visual information at fixed steps, resulting in inefficient and inflexible reasoning; and (2) Broken Visual Thought Representation, which involves discontinuous and semantically incoherent visual tokens. To address these limitations, we introduce Interleaved-modal Chain-of-Thought reasoning with Dynamic and Precise Visual Thoughts (DaP-ICoT), which incorporates two key components: (1) Dynamic Visual Thought Integration adaptively introduces visual inputs based on reasoning needs, reducing redundancy and improving efficiency. (2) Precise Visual Thought Guidance ensures visual semantically coherent and contextually aligned representations. Experiments across multiple benchmarks and models demonstrate that DaP-ICoT achieves state-of-the-art performance. In addition, DaP-ICoT significantly reduces the number of inserted images, leading to a 72.6% decrease in token consumption, enabling more efficient ICoT reasoning.
ESAinsTOD: A Unified End-to-End Schema-Aware Instruction-Tuning Framework for Task-Oriented Dialog Modeling
Mar 10, 2026Existing end-to-end modeling methods for modular task-oriented dialog systems are typically tailored to specific datasets, making it challenging to adapt to new dialog scenarios. In this work, we propose ESAinsTOD, a unified End-to-end Schema-Aware Instruction-tuning framework for general Task-Oriented Dialog modeling. This framework introduces a structured methodology to go beyond simply fine-tuning Large Language Models (LLMs), enabling flexible adaptation to various dialogue task flows and schemas. Specifically, we leverage full-parameter fine-tuning of LLMs and introduce two alignment mechanisms to make the resulting system both instruction-aware and schema-aware: (i) instruction alignment, which ensures that the system faithfully follows task instructions to complete various task flows from heterogeneous TOD datasets; and (ii) schema alignment, which encourages the system to make predictions adhering to the specified schema. In addition, we employ session-level end-to-end modeling, which allows the system to access the results of previously executed task flows within the dialogue history, to bridge the gap between the instruction-tuning paradigm and the real-world application of TOD systems. Empirical results show that while a fine-tuned LLM serves as a strong baseline, our structured approach provides significant additional benefits. In particular, our findings indicate that: (i) ESAinsTOD outperforms state-of-the-art models by a significant margin on end-to-end task-oriented dialog modeling benchmarks: CamRest676, In-Car and MultiWOZ; (ii) more importantly, it exhibits superior generalization capabilities across various low-resource settings, with the proposed alignment mechanisms significantly enhancing zero-shot performance; and (iii) our instruction-tuning paradigm substantially improves the model's robustness against data noise and cascading errors.
* Published at International Journal of Machine Learning and Cybernetics (IJMLC)
Retrieval-Infused Reasoning Sandbox: A Benchmark for Decoupling Retrieval and Reasoning Capabilities
Jan 29, 2026Despite strong performance on existing benchmarks, it remains unclear whether large language models can reason over genuinely novel scientific information. Most evaluations score end-to-end RAG pipelines, where reasoning is confounded with retrieval and toolchain choices, and the signal is further contaminated by parametric memorization and open-web volatility. We introduce DeR2, a controlled deep-research sandbox that isolates document-grounded reasoning while preserving core difficulties of deep search: multi-step synthesis, denoising, and evidence-based conclusion making. DeR2 decouples evidence access from reasoning via four regimes--Instruction-only, Concepts (gold concepts without documents), Related-only (only relevant documents), and Full-set (relevant documents plus topically related distractors)--yielding interpretable regime gaps that operationalize retrieval loss vs. reasoning loss and enable fine-grained error attribution. To prevent parametric leakage, we apply a two-phase validation that requires parametric failure without evidence while ensuring oracle-concept solvability. To ensure reproducibility, each instance provides a frozen document library (drawn from 2023-2025 theoretical papers) with expert-annotated concepts and validated rationales. Experiments across a diverse set of state-of-the-art foundation models reveal substantial variation and significant headroom: some models exhibit mode-switch fragility, performing worse with the Full-set than with Instruction-only, while others show structural concept misuse, correctly naming concepts but failing to execute them as procedures.
The Molecular Structure of Thought: Mapping the Topology of Long Chain-of-Thought Reasoning
Jan 13, 2026Large language models (LLMs) often fail to learn effective long chain-of-thought (Long CoT) reasoning from human or non-Long-CoT LLMs imitation. To understand this, we propose that effective and learnable Long CoT trajectories feature stable molecular-like structures in unified view, which are formed by three interaction types: Deep-Reasoning (covalent-like), Self-Reflection (hydrogen-bond-like), and Self-Exploration (van der Waals-like). Analysis of distilled trajectories reveals these structures emerge from Long CoT fine-tuning, not keyword imitation. We introduce Effective Semantic Isomers and show that only bonds promoting fast entropy convergence support stable Long CoT learning, while structural competition impairs training. Drawing on these findings, we present Mole-Syn, a distribution-transfer-graph method that guides synthesis of effective Long CoT structures, boosting performance and RL stability across benchmarks.
Can Large Language Models Resolve Semantic Discrepancy in Self-Destructive Subcultures? Evidence from Jirai Kei
Jan 08, 2026Self-destructive behaviors are linked to complex psychological states and can be challenging to diagnose. These behaviors may be even harder to identify within subcultural groups due to their unique expressions. As large language models (LLMs) are applied across various fields, some researchers have begun exploring their application for detecting self-destructive behaviors. Motivated by this, we investigate self-destructive behavior detection within subcultures using current LLM-based methods. However, these methods have two main challenges: (1) Knowledge Lag: Subcultural slang evolves rapidly, faster than LLMs' training cycles; and (2) Semantic Misalignment: it is challenging to grasp the specific and nuanced expressions unique to subcultures. To address these issues, we proposed Subcultural Alignment Solver (SAS), a multi-agent framework that incorporates automatic retrieval and subculture alignment, significantly enhancing the performance of LLMs in detecting self-destructive behavior. Our experimental results show that SAS outperforms the current advanced multi-agent framework OWL. Notably, it competes well with fine-tuned LLMs. We hope that SAS will advance the field of self-destructive behavior detection in subcultural contexts and serve as a valuable resource for future researchers.
The Universal Landscape of Human Reasoning
Oct 24, 2025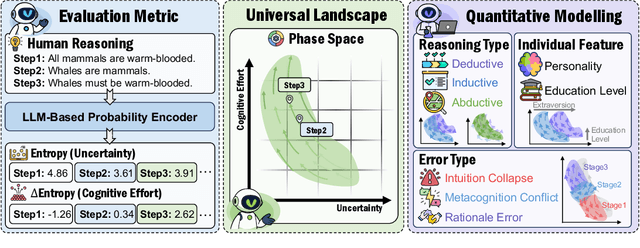
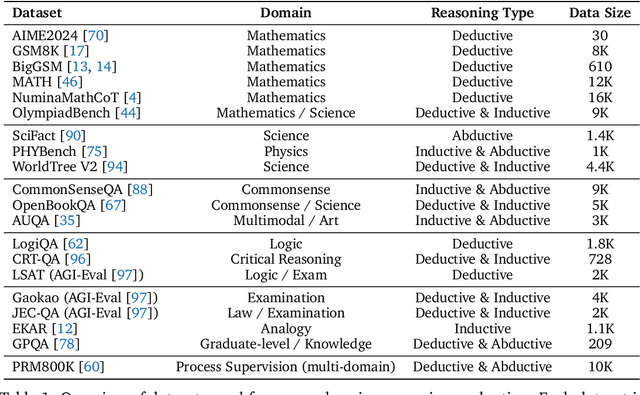
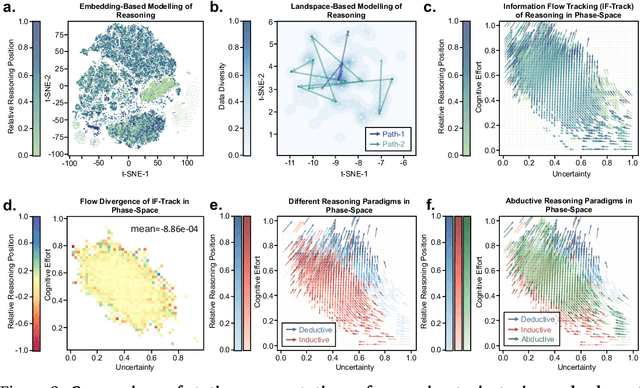
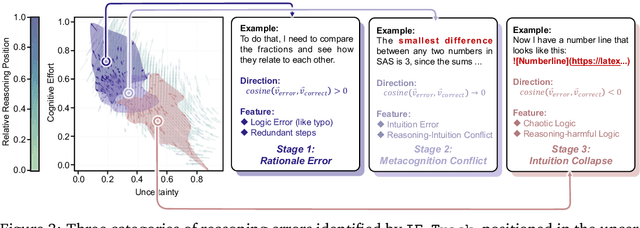
Understanding how information is dynamically accumulated and transformed in human reasoning has long challenged cognitive psychology, philosophy, and artificial intelligence. Existing accounts, from classical logic to probabilistic models, illuminate aspects of output or individual modelling, but do not offer a unified, quantitative description of general human reasoning dynamics. To solve this, we introduce Information Flow Tracking (IF-Track), that uses large language models (LLMs) as probabilistic encoder to quantify information entropy and gain at each reasoning step. Through fine-grained analyses across diverse tasks, our method is the first successfully models the universal landscape of human reasoning behaviors within a single metric space. We show that IF-Track captures essential reasoning features, identifies systematic error patterns, and characterizes individual differences. Applied to discussion of advanced psychological theory, we first reconcile single- versus dual-process theories in IF-Track and discover the alignment of artificial and human cognition and how LLMs reshaping human reasoning process. This approach establishes a quantitative bridge between theory and measurement, offering mechanistic insights into the architecture of reasoning.
Beyond Surface Reasoning: Unveiling the True Long Chain-of-Thought Capacity of Diffusion Large Language Models
Oct 10, 2025Recently, Diffusion Large Language Models (DLLMs) have offered high throughput and effective sequential reasoning, making them a competitive alternative to autoregressive LLMs (ALLMs). However, parallel decoding, which enables simultaneous token updates, conflicts with the causal order often required for rigorous reasoning. We first identify this conflict as the core Parallel-Sequential Contradiction (PSC). Behavioral analyses in both simple and complex reasoning tasks show that DLLMs exhibit genuine parallelism only for directly decidable outputs. As task difficulty increases, they revert to autoregressive-like behavior, a limitation exacerbated by autoregressive prompting, which nearly doubles the number of decoding steps with remasking without improving quality. Moreover, PSC restricts DLLMs' self-reflection, reasoning depth, and exploratory breadth. To further characterize PSC, we introduce three scaling dimensions for DLLMs: parallel, diffusion, and sequential. Empirically, while parallel scaling yields consistent improvements, diffusion and sequential scaling are constrained by PSC. Based on these findings, we propose several practical mitigations, parallel-oriented prompting, diffusion early stopping, and parallel scaling, to reduce PSC-induced ineffectiveness and inefficiencies.
AutoPR: Let's Automate Your Academic Promotion!
Oct 10, 2025As the volume of peer-reviewed research surges, scholars increasingly rely on social platforms for discovery, while authors invest considerable effort in promoting their work to ensure visibility and citations. To streamline this process and reduce the reliance on human effort, we introduce Automatic Promotion (AutoPR), a novel task that transforms research papers into accurate, engaging, and timely public content. To enable rigorous evaluation, we release PRBench, a multimodal benchmark that links 512 peer-reviewed articles to high-quality promotional posts, assessing systems along three axes: Fidelity (accuracy and tone), Engagement (audience targeting and appeal), and Alignment (timing and channel optimization). We also introduce PRAgent, a multi-agent framework that automates AutoPR in three stages: content extraction with multimodal preparation, collaborative synthesis for polished outputs, and platform-specific adaptation to optimize norms, tone, and tagging for maximum reach. When compared to direct LLM pipelines on PRBench, PRAgent demonstrates substantial improvements, including a 604% increase in total watch time, a 438% rise in likes, and at least a 2.9x boost in overall engagement. Ablation studies show that platform modeling and targeted promotion contribute the most to these gains. Our results position AutoPR as a tractable, measurable research problem and provide a roadmap for scalable, impactful automated scholarly communication.
Can LLMs Refuse Questions They Do Not Know? Measuring Knowledge-Aware Refusal in Factual Tasks
Oct 02, 2025Large Language Models (LLMs) should refuse to answer questions beyond their knowledge. This capability, which we term knowledge-aware refusal, is crucial for factual reliability. However, existing metrics fail to faithfully measure this ability. On the one hand, simple refusal-based metrics are biased by refusal rates and yield inconsistent scores when models exhibit different refusal tendencies. On the other hand, existing calibration metrics are proxy-based, capturing the performance of auxiliary calibration processes rather than the model's actual refusal behavior. In this work, we propose the Refusal Index (RI), a principled metric that measures how accurately LLMs refuse questions they do not know. We define RI as Spearman's rank correlation between refusal probability and error probability. To make RI practically measurable, we design a lightweight two-pass evaluation method that efficiently estimates RI from observed refusal rates across two standard evaluation runs. Extensive experiments across 16 models and 5 datasets demonstrate that RI accurately quantifies a model's intrinsic knowledge-aware refusal capability in factual tasks. Notably, RI remains stable across different refusal rates and provides consistent model rankings independent of a model's overall accuracy and refusal rates. More importantly, RI provides insight into an important but previously overlooked aspect of LLM factuality: while LLMs achieve high accuracy on factual tasks, their refusal behavior can be unreliable and fragile. This finding highlights the need to complement traditional accuracy metrics with the Refusal Index for comprehensive factuality evaluation.
AI4Research: A Survey of Artificial Intelligence for Scientific Research
Jul 02, 2025Recent advancements in artificial intelligence (AI), particularly in large language models (LLMs) such as OpenAI-o1 and DeepSeek-R1, have demonstrated remarkable capabilities in complex domains such as logical reasoning and experimental coding. Motivated by these advancements, numerous studies have explored the application of AI in the innovation process, particularly in the context of scientific research. These AI technologies primarily aim to develop systems that can autonomously conduct research processes across a wide range of scientific disciplines. Despite these significant strides, a comprehensive survey on AI for Research (AI4Research) remains absent, which hampers our understanding and impedes further development in this field. To address this gap, we present a comprehensive survey and offer a unified perspective on AI4Research. Specifically, the main contributions of our work are as follows: (1) Systematic taxonomy: We first introduce a systematic taxonomy to classify five mainstream tasks in AI4Research. (2) New frontiers: Then, we identify key research gaps and highlight promising future directions, focusing on the rigor and scalability of automated experiments, as well as the societal impact. (3) Abundant applications and resources: Finally, we compile a wealth of resources, including relevant multidisciplinary applications, data corpora, and tools. We hope our work will provide the research community with quick access to these resources and stimulate innovative breakthroughs in AI4Research.