 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapShot: Adaptive Many-Shot In-Context Learning with Semantic-Aware KV Cache Reuse
May 05, 2026Many-Shot In-Context Learning (ICL) has emerged as a promising paradigm, leveraging extensive examples to unlock the reasoning potential of Large Language Models (LLMs). However, existing methods typically rely on a predetermined, fixed number of shots. This static approach often fails to adapt to the varying difficulty of different queries, leading to either insufficient context or interference from noise. Furthermore, the prohibitive computational and memory costs of long contexts severely limit Many-Shot's feasibility. To address the above limitations, we propose AdapShot, which dynamically optimizes shot counts and leverages KV cache reuse for efficient inference. Specifically, we design a probe-based evaluation mechanism that utilizes output entropy to determine the optimal number of shots. To bypass the redundant prefilling computation during both the probing and inference phases, we incorporate a semantics-aware KV cache reuse strategy. Within this reuse strategy, to address positional encoding incompatibilities, we introduce a decoupling and re-encoding method that enables the flexible reordering of cached key-value pairs. Extensive experiments demonstrate that AdapShot achieves an average performance gain of around 10% and a 4.64x speedup compared to state-of-the-art DBSA.
CAP: Controllable Alignment Prompting for Unlearning in LLMs
Apr 23, 2026Large language models (LLMs) trained on unfiltered corpora inherently risk retaining sensitive information, necessitating selective knowledge unlearning for regulatory compliance and ethical safety. However, existing parameter-modifying methods face fundamental limitations: high computational costs, uncontrollable forgetting boundaries, and strict dependency on model weight access. These constraints render them impractical for closed-source models, yet current non-invasive alternatives remain unsystematic and reliant on empirical experience. To address these challenges, we propose the Controllable Alignment Prompting for Unlearning (CAP) framework, an end-to-end prompt-driven unlearning paradigm. CAP decouples unlearning into a learnable prompt optimization process via reinforcement learning, where a prompt generator collaborates with the LLM to suppress target knowledge while preserving general capabilities selectively. This approach enables reversible knowledge restoration through prompt revocation. Extensive experiments demonstrate that CAP achieves precise, controllable unlearning without updating model parameters, establishing a dynamic alignment mechanism that overcomes the transferability limitations of prior methods.
ALTER: Asymmetric LoRA for Token-Entropy-Guided Unlearning of LLMs
Mar 02, 2026Large language models (LLMs) have advanced to encompass extensive knowledge across diverse domains. Yet controlling what a LLMs should not know is important for ensuring alignment and thus safe use. However, effective unlearning in LLMs is difficult due to the fuzzy boundary between knowledge retention and forgetting. This challenge is exacerbated by entangled parameter spaces from continuous multi-domain training, often resulting in collateral damage, especially under aggressive unlearning strategies. Furthermore, the computational overhead required to optimize State-of-the-Art (SOTA) models with billions of parameters poses an additional barrier. In this work, we present ALTER, a lightweight unlearning framework for LLMs to address both the challenges of knowledge entanglement and unlearning efficiency. ALTER operates through two phases: (I) high entropy tokens are captured and learned via the shared A matrix in LoRA, followed by (II) an asymmetric LoRA architecture that achieves a specified forgetting objective by parameter isolation and unlearning tokens within the target subdomains. Serving as a new research direction for achieving unlearning via token-level isolation in the asymmetric framework. ALTER achieves SOTA performance on TOFU, WMDP, and MUSE benchmarks with over 95% forget quality and shows minimal side effects through preserving foundational tokens. By decoupling unlearning from LLMs' billion-scale parameters, this framework delivers excellent efficiency while preserving over 90% of model utility, exceeding baseline preservation rates of 47.8-83.6%.
Noise-Robustness Through Noise: Asymmetric LoRA Adaption with Poisoning Expert
May 29, 2025



Current parameter-efficient fine-tuning methods for adapting pre-trained language models to downstream tasks are susceptible to interference from noisy data. Conventional noise-handling approaches either rely on laborious data pre-processing or employ model architecture modifications prone to error accumulation. In contrast to existing noise-process paradigms, we propose a noise-robust adaptation method via asymmetric LoRA poisoning experts (LoPE), a novel framework that enhances model robustness to noise only with generated noisy data. Drawing inspiration from the mixture-of-experts architecture, LoPE strategically integrates a dedicated poisoning expert in an asymmetric LoRA configuration. Through a two-stage paradigm, LoPE performs noise injection on the poisoning expert during fine-tuning to enhance its noise discrimination and processing ability. During inference, we selectively mask the dedicated poisoning expert to leverage purified knowledge acquired by normal experts for noise-robust output. Extensive experiments demonstrate that LoPE achieves strong performance and robustness purely through the low-cost noise injection, which completely eliminates the requirement of data cleaning.
HASH-RAG: Bridging Deep Hashing with Retriever for Efficient, Fine Retrieval and Augmented Generation
May 22, 2025Retrieval-Augmented Generation (RAG) encounters efficiency challenges when scaling to massive knowledge bases while preserving contextual relevance. We propose Hash-RAG, a framework that integrates deep hashing techniques with systematic optimizations to address these limitations. Our queries directly learn binary hash codes from knowledgebase code, eliminating intermediate feature extraction steps, and significantly reducing storage and computational overhead. Building upon this hash-based efficient retrieval framework, we establish the foundation for fine-grained chunking. Consequently, we design a Prompt-Guided Chunk-to-Context (PGCC) module that leverages retrieved hash-indexed propositions and their original document segments through prompt engineering to enhance the LLM's contextual awareness. Experimental evaluations on NQ, TriviaQA, and HotpotQA datasets demonstrate that our approach achieves a 90% reduction in retrieval time compared to conventional methods while maintaining considerate recall performance. Additionally, The proposed system outperforms retrieval/non-retrieval baselines by 1.4-4.3% in EM scores.
Accelerating Adaptive Retrieval Augmented Generation via Instruction-Driven Representation Reduction of Retrieval Overlaps
May 19, 2025



Retrieval-augmented generation (RAG) has emerged as a pivotal method for expanding the knowledge of large language models. To handle complex queries more effectively, researchers developed Adaptive-RAG (A-RAG) to enhance the generated quality through multiple interactions with external knowledge bases. Despite its effectiveness, A-RAG exacerbates the pre-existing efficiency challenges inherent in RAG, which are attributable to its reliance on multiple iterations of generation. Existing A-RAG approaches process all retrieved contents from scratch. However, they ignore the situation where there is a significant overlap in the content of the retrieval results across rounds. The overlapping content is redundantly represented, which leads to a large proportion of repeated computations, thus affecting the overall efficiency. To address this issue, this paper introduces a model-agnostic approach that can be generally applied to A-RAG methods, which is dedicated to reducing the redundant representation process caused by the overlapping of retrieval results. Specifically, we use cache access and parallel generation to speed up the prefilling and decoding stages respectively. Additionally, we also propose an instruction-driven module to further guide the model to more effectively attend to each part of the content in a more suitable way for LLMs. Experiments show that our approach achieves 2.79 and 2.33 times significant acceleration on average for prefilling and decoding respectively while maintaining equal generation quality.
Lossless Acceleration of Large Language Model via Adaptive N-gram Parallel Decoding
Apr 10, 2024



While Large Language Models (LLMs) have shown remarkable abilities, they are hindered by significant resource consumption and considerable latency due to autoregressive processing. In this study, we introduce Adaptive N-gram Parallel Decoding (ANPD), an innovative and lossless approach that accelerates inference by allowing the simultaneous generation of multiple tokens. ANPD incorporates a two-stage approach: it begins with a rapid drafting phase that employs an N-gram module, which adapts based on the current interactive context, followed by a verification phase, during which the original LLM assesses and confirms the proposed tokens. Consequently, ANPD preserves the integrity of the LLM's original output while enhancing processing speed. We further leverage a multi-level architecture for the N-gram module to enhance the precision of the initial draft, consequently reducing inference latency. ANPD eliminates the need for retraining or extra GPU memory, making it an efficient and plug-and-play enhancement. In our experiments, models such as LLaMA and its fine-tuned variants have shown speed improvements up to 3.67x, validating the effectiveness of our proposed ANPD.
PMFSNet: Polarized Multi-scale Feature Self-attention Network For Lightweight Medical Image Segmentation
Jan 15, 2024



Current state-of-the-art medical image segmentation methods prioritize accuracy but often at the expense of increased computational demands and larger model sizes. Applying these large-scale models to the relatively limited scale of medical image datasets tends to induce redundant computation, complicating the process without the necessary benefits. This approach not only adds complexity but also presents challenges for the integration and deployment of lightweight models on edge devices. For instance, recent transformer-based models have excelled in 2D and 3D medical image segmentation due to their extensive receptive fields and high parameter count. However, their effectiveness comes with a risk of overfitting when applied to small datasets and often neglects the vital inductive biases of Convolutional Neural Networks (CNNs), essential for local feature representation. In this work, we propose PMFSNet, a novel medical imaging segmentation model that effectively balances global and local feature processing while avoiding the computational redundancy typical in larger models. PMFSNet streamlines the UNet-based hierarchical structure and simplifies the self-attention mechanism's computational complexity, making it suitable for lightweight applications. It incorporates a plug-and-play PMFS block, a multi-scale feature enhancement module based on attention mechanisms, to capture long-term dependencies. Extensive comprehensive results demonstrate that even with a model (less than 1 million parameters), our method achieves superior performance in various segmentation tasks across different data scales. It achieves (IoU) metrics of 84.68%, 82.02%, and 78.82% on public datasets of teeth CT (CBCT), ovarian tumors ultrasound(MMOTU), and skin lesions dermoscopy images (ISIC 2018), respectively. The source code is available at https://github.com/yykzjh/PMFSNet.
Multi Loss-based Feature Fusion and Top Two Voting Ensemble Decision Strategy for Facial Expression Recognition in the Wild
Nov 06, 2023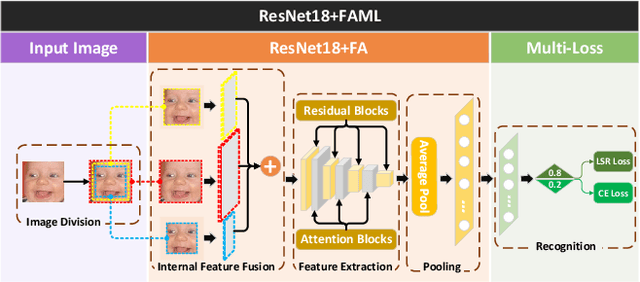
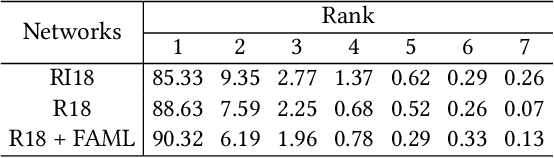
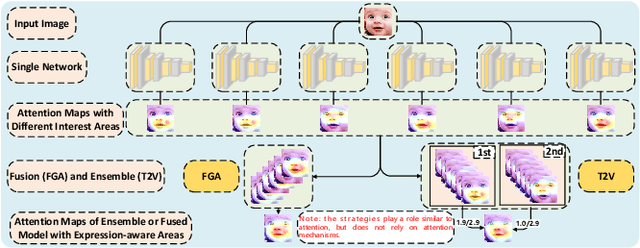
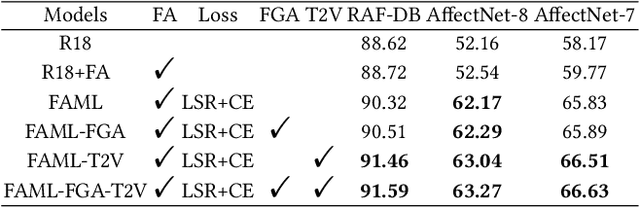
Facial expression recognition (FER) in the wild is a challenging task affected by the image quality and has attracted broad interest in computer vision. There is no research using feature fusion and ensemble strategy for FER simultaneously. Different from previous studies, this paper applies both internal feature fusion for a single model and feature fusion among multiple networks, as well as the ensemble strategy. This paper proposes one novel single model named R18+FAML, as well as one ensemble model named R18+FAML-FGA-T2V to improve the performance of the FER in the wild. Based on the structure of ResNet18 (R18), R18+FAML combines internal Feature fusion and three Attention blocks using Multiple Loss functions (FAML) to improve the diversity of the feature extraction. To improve the performance of R18+FAML, we propose a Feature fusion among networks based on the Genetic Algorithm (FGA), which can fuse the convolution kernels for feature extraction of multiple networks. On the basis of R18+FAML and FGA, we propose one ensemble strategy, i.e., the Top Two Voting (T2V) to support the classification of FER, which can consider more classification information comprehensively. Combining the above strategies, R18+FAML-FGA-T2V can focus on the main expression-aware areas. Extensive experiments demonstrate that our single model R18+FAML and the ensemble model R18+FAML-FGA-T2V achieve the accuracies of $\left( 90.32, 62.17, 65.83 \right)\%$ and $\left( 91.59, 63.27, 66.63 \right)\%$ on three challenging unbalanced FER datasets RAF-DB, AffectNet-8 and AffectNet-7 respectively, both outperforming the state-of-the-art results.
Uncover Common Facial Expressions in Terracotta Warriors: A Deep Learning Approach
May 11, 2021


Can advanced deep learning technologies be applied to analyze some ancient humanistic arts? Can deep learning technologies be directly applied to special scenes such as facial expression analysis of Terracotta Warriors? The big challenging is that the facial features of the Terracotta Warriors are very different from today's people. We found that it is very poor to directly use the models that have been trained on other classic facial expression datasets to analyze the facial expressions of the Terracotta Warriors. At the same time, the lack of public high-quality facial expression data of the Terracotta Warriors also limits the use of deep learning technologies. Therefore, we firstly use Generative Adversarial Networks (GANs) to generate enough high-quality facial expression data for subsequent training and recognition. We also verify the effectiveness of this approach. For the first time, this paper uses deep learning technologies to find common facial expressions of general and postured Terracotta Warriors. These results will provide an updated technical means for the research of art of the Terracotta Warriors and shine lights on the research of other ancient arts.