 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMADQRL: Distributed Quantum Reinforcement Learning Framework for Multi-Agent Environments
Apr 13, 2026Reinforcement learning (RL) is one of the most practical ways to learn from real-life use-cases. Motivated from the cognitive methods used by humans makes it a widely acceptable strategy in the field of artificial intelligence. Most of the environments used for RL are often high-dimensional, and traditional RL algorithms becomes computationally expensive and challenging to effectively learn from such systems. Recent advancements in practical demonstration of quantum computing (QC) theories, such as compact encoding, enhanced representation and learning algorithms, random sampling, or the inherent stochastic nature of quantum systems, have opened up new directions to tackle these challenges. Quantum reinforcement learning (QRL) is seeking significant traction over the past few years. However, the current state of quantum hardware is not enough to cater for such high-dimensional environments with complex multi-agent setup. To tackle this issue, we propose a distributed framework for QRL where multiple agents learn independently, distributing the load of joint training from individual machines. Our method works well for environments with disjoint sets of action and observation spaces, but can also be extended to other systems with reasonable approximations. We analyze the proposed method on cooperative-pong environment and our results indicate ~10% improvement from other distribution strategies, and ~5% improvement from classical models of policy representation.
DeFRiS: Silo-Cooperative IoT Applications Scheduling via Decentralized Federated Reinforcement Learning
Mar 16, 2026Next-generation IoT applications increasingly span across autonomous administrative entities, necessitating silo-cooperative scheduling to leverage diverse computational resources while preserving data privacy. However, realizing efficient cooperation faces significant challenges arising from infrastructure heterogeneity, Non-IID workload shifts, and the inherent risks of adversarial environments. Existing approaches, relying predominantly on centralized coordination or independent learning, fail to address the incompatibility of state-action spaces across heterogeneous silos and lack robustness against malicious attacks. This paper proposes DeFRiS, a Decentralized Federated Reinforcement Learning framework for robust and scalable Silo-cooperative IoT application scheduling. DeFRiS integrates three synergistic innovations: (i) an action-space-agnostic policy utilizing candidate resource scoring to enable seamless knowledge transfer across heterogeneous silos; (ii) a silo-optimized local learning mechanism combining Generalized Advantage Estimation (GAE) with clipped policy updates to resolve sparse delayed reward challenges; and (iii) a Dual-Track Non-IID robust decentralized aggregation protocol leveraging gradient fingerprints for similarity-aware knowledge transfer and anomaly detection, and gradient tracking for optimization momentum. Extensive experiments on a distributed testbed with 20 heterogeneous silos and realistic IoT workloads demonstrate that DeFRiS significantly outperforms state-of-the-art baselines, reducing average response time by 6.4% and energy consumption by 7.2%, while lowering tail latency risk (CVaR$_{0.95}$) by 10.4% and achieving near-zero deadline violations. Furthermore, DeFRiS achieves over 3 times better performance retention as the system scales and over 8 times better stability in adversarial environments compared to the best-performing baseline.
DistributedEstimator: Distributed Training of Quantum Neural Networks via Circuit Cutting
Feb 18, 2026Circuit cutting decomposes a large quantum circuit into a collection of smaller subcircuits. The outputs of these subcircuits are then classically reconstructed to recover the original expectation values. While prior work characterises cutting overhead largely in terms of subcircuit counts and sampling complexity, its end-to-end impact on iterative, estimator-driven training pipelines remains insufficiently measured from a systems perspective. In this paper, we propose a cut-aware estimator execution pipeline that treats circuit cutting as a staged distributed workload and instruments each estimator query into partitioning, subexperiment generation, parallel execution, and classical reconstruction phases. Using logged runtime traces and learning outcomes on two binary classification workloads (Iris and MNIST), we quantify cutting overheads, scaling limits, and sensitivity to injected stragglers, and we evaluate whether accuracy and robustness are preserved under matched training budgets. Our measurements show that cutting introduces substantial end-to-end overheads that grow with the number of cuts, and that reconstruction constitutes a dominant fraction of per-query time, bounding achievable speed-up under increased parallelism. Despite these systems costs, test accuracy and robustness are preserved in the measured regimes, with configuration-dependent improvements observed in some cut settings. These results indicate that practical scaling of circuit cutting for learning workloads hinges on reducing and overlapping reconstruction and on scheduling policies that account for barrier-dominated critical paths.
Fedcompass: Federated Clustered and Periodic Aggregation Framework for Hybrid Classical-Quantum Models
Feb 03, 2026Federated learning enables collaborative model training across decentralized clients under privacy constraints. Quantum computing offers potential for alleviating computational and communication burdens in federated learning, yet hybrid classical-quantum federated learning remains susceptible to performance degradation under non-IID data. To address this,we propose FEDCOMPASS, a layered aggregation framework for hybrid classical-quantum federated learning. FEDCOMPASS employs spectral clustering to group clients by class distribution similarity and performs cluster-wise aggregation for classical feature extractors. For quantum parameters, it uses circular mean aggregation combined with adaptive optimization to ensure stable global updates. Experiments on three benchmark datasets show that FEDCOMPASS improves test accuracy by up to 10.22% and enhances convergence stability under non-IID settings, outperforming six strong federated learning baselines.
Agentic Artificial Intelligence (AI): Architectures, Taxonomies, and Evaluation of Large Language Model Agents
Jan 18, 2026Artificial Intelligence is moving from models that only generate text to Agentic AI, where systems behave as autonomous entities that can perceive, reason, plan, and act. Large Language Models (LLMs) are no longer used only as passive knowledge engines but as cognitive controllers that combine memory, tool use, and feedback from their environment to pursue extended goals. This shift already supports the automation of complex workflows in software engineering, scientific discovery, and web navigation, yet the variety of emerging designs, from simple single loop agents to hierarchical multi agent systems, makes the landscape hard to navigate. In this paper, we investigate architectures and propose a unified taxonomy that breaks agents into Perception, Brain, Planning, Action, Tool Use, and Collaboration. We use this lens to describe the move from linear reasoning procedures to native inference time reasoning models, and the transition from fixed API calls to open standards like the Model Context Protocol (MCP) and Native Computer Use. We also group the environments in which these agents operate, including digital operating systems, embodied robotics, and other specialized domains, and we review current evaluation practices. Finally, we highlight open challenges, such as hallucination in action, infinite loops, and prompt injection, and outline future research directions toward more robust and reliable autonomous systems.
Evidential Trust-Aware Model Personalization in Decentralized Federated Learning for Wearable IoT
Dec 22, 2025Decentralized federated learning (DFL) enables collaborative model training across edge devices without centralized coordination, offering resilience against single points of failure. However, statistical heterogeneity arising from non-identically distributed local data creates a fundamental challenge: nodes must learn personalized models adapted to their local distributions while selectively collaborating with compatible peers. Existing approaches either enforce a single global model that fits no one well, or rely on heuristic peer selection mechanisms that cannot distinguish between peers with genuinely incompatible data distributions and those with valuable complementary knowledge. We present Murmura, a framework that leverages evidential deep learning to enable trust-aware model personalization in DFL. Our key insight is that epistemic uncertainty from Dirichlet-based evidential models directly indicates peer compatibility: high epistemic uncertainty when a peer's model evaluates local data reveals distributional mismatch, enabling nodes to exclude incompatible influence while maintaining personalized models through selective collaboration. Murmura introduces a trust-aware aggregation mechanism that computes peer compatibility scores through cross-evaluation on local validation samples and personalizes model aggregation based on evidential trust with adaptive thresholds. Evaluation on three wearable IoT datasets (UCI HAR, PAMAP2, PPG-DaLiA) demonstrates that Murmura reduces performance degradation from IID to non-IID conditions compared to baseline (0.9% vs. 19.3%), achieves 7.4$\times$ faster convergence, and maintains stable accuracy across hyperparameter choices. These results establish evidential uncertainty as a principled foundation for compatibility-aware personalization in decentralized heterogeneous environments.
Quantum Machine Learning for Cybersecurity: A Taxonomy and Future Directions
Dec 17, 2025The increasing number of cyber threats and rapidly evolving tactics, as well as the high volume of data in recent years, have caused classical machine learning, rules, and signature-based defence strategies to fail, rendering them unable to keep up. An alternative, Quantum Machine Learning (QML), has recently emerged, making use of computations based on quantum mechanics. It offers better encoding and processing of high-dimensional structures for certain problems. This survey provides a comprehensive overview of QML techniques relevant to the domain of security, such as Quantum Neural Networks (QNNs), Quantum Support Vector Machines (QSVMs), Variational Quantum Circuits (VQCs), and Quantum Generative Adversarial Networks (QGANs), and discusses the contributions of this paper in relation to existing research in the field and how it improves over them. It also maps these methods across supervised, unsupervised, and generative learning paradigms, and to core cybersecurity tasks, including intrusion and anomaly detection, malware and botnet classification, and encrypted-traffic analytics. It also discusses their application in the domain of cloud computing security, where QML can enhance secure and scalable operations. Many limitations of QML in the domain of cybersecurity have also been discussed, along with the directions for addressing them.
Quantum Artificial Intelligence (QAI): Foundations, Architectural Elements, and Future Directions
Nov 13, 2025Mission critical (MC) applications such as defense operations, energy management, cybersecurity, and aerospace control require reliable, deterministic, and low-latency decision making under uncertainty. Although the classical Machine Learning (ML) approaches are effective, they often struggle to meet the stringent constraints of robustness, timing, explainability, and safety in the MC domains. Quantum Artificial Intelligence (QAI), the fusion of machine learning and quantum computing (QC), can provide transformative solutions to the challenges faced by classical ML models. In this paper, we provide a comprehensive exploration of QAI for MC systems. We begin with a conceptual background to quantum computing, MC systems, and quantum machine learning (QAI). We then examine the core mechanisms and algorithmic principles of QAI in MC systems, including quantum-enhanced learning pipelines, quantum uncertainty quantification, and quantum explainability frameworks. Subsequently, we discuss key application areas like aerospace, defense, cybersecurity, smart grids, and disaster management, focusing on the role of QA in enhancing fault tolerance, real-time intelligence, and adaptability. We provide an exploration of the positioning of QAI for MC systems in the industry in terms of deployment. We also propose a model for management of quantum resources and scheduling of applications driven by timeliness constraints. We discuss multiple challenges, including trainability limits, data access, and loading bottlenecks, verification of quantum components, and adversarial QAI. Finally, we outline future research directions toward achieving interpretable, scalable, and hardware-feasible QAI models for MC application deployment.
AirFed: Federated Graph-Enhanced Multi-Agent Reinforcement Learning for Multi-UAV Cooperative Mobile Edge Computing
Oct 27, 2025Multiple Unmanned Aerial Vehicles (UAVs) cooperative Mobile Edge Computing (MEC) systems face critical challenges in coordinating trajectory planning, task offloading, and resource allocation while ensuring Quality of Service (QoS) under dynamic and uncertain environments. Existing approaches suffer from limited scalability, slow convergence, and inefficient knowledge sharing among UAVs, particularly when handling large-scale IoT device deployments with stringent deadline constraints. This paper proposes AirFed, a novel federated graph-enhanced multi-agent reinforcement learning framework that addresses these challenges through three key innovations. First, we design dual-layer dynamic Graph Attention Networks (GATs) that explicitly model spatial-temporal dependencies among UAVs and IoT devices, capturing both service relationships and collaborative interactions within the network topology. Second, we develop a dual-Actor single-Critic architecture that jointly optimizes continuous trajectory control and discrete task offloading decisions. Third, we propose a reputation-based decentralized federated learning mechanism with gradient-sensitive adaptive quantization, enabling efficient and robust knowledge sharing across heterogeneous UAVs. Extensive experiments demonstrate that AirFed achieves 42.9% reduction in weighted cost compared to state-of-the-art baselines, attains over 99% deadline satisfaction and 94.2% IoT device coverage rate, and reduces communication overhead by 54.5%. Scalability analysis confirms robust performance across varying UAV numbers, IoT device densities, and system scales, validating AirFed's practical applicability for large-scale UAV-MEC deployments.
Incentive-Based Federated Learning
Oct 16, 2025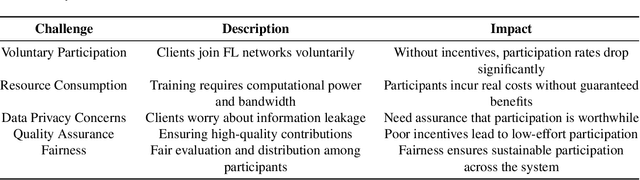
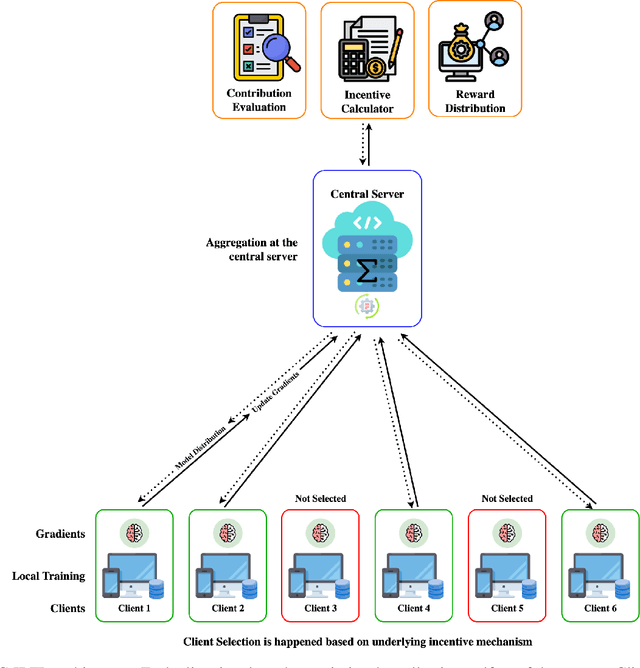
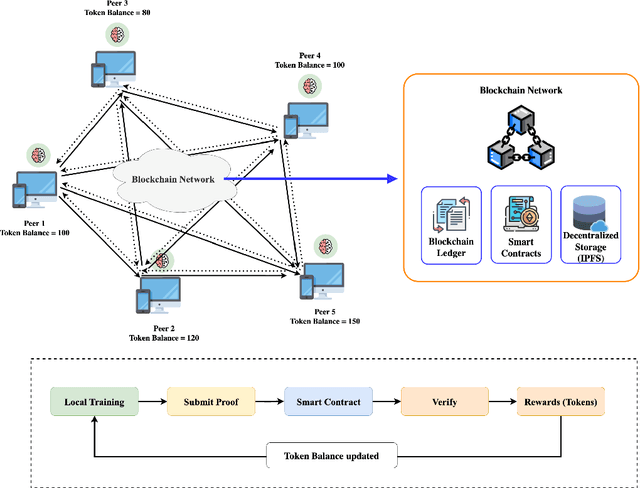

Federated learning promises to revolutionize machine learning by enabling collaborative model training without compromising data privacy. However, practical adaptability can be limited by critical factors, such as the participation dilemma. Participating entities are often unwilling to contribute to a learning system unless they receive some benefits, or they may pretend to participate and free-ride on others. This chapter identifies the fundamental challenges in designing incentive mechanisms for federated learning systems. It examines how foundational concepts from economics and game theory can be applied to federated learning, alongside technology-driven solutions such as blockchain and deep reinforcement learning. This work presents a comprehensive taxonomy that thoroughly covers both centralized and decentralized architectures based on the aforementioned theoretical concepts. Furthermore, the concepts described are presented from an application perspective, covering emerging industrial applications, including healthcare, smart infrastructure, vehicular networks, and blockchain-based decentralized systems. Through this exploration, this chapter demonstrates that well-designed incentive mechanisms are not merely optional features but essential components for the practical success of federated learning. This analysis reveals both the promising solutions that have emerged and the significant challenges that remain in building truly sustainable, fair, and robust federated learning ecosystems.