 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDividable Configuration Performance Learning
Sep 11, 2024
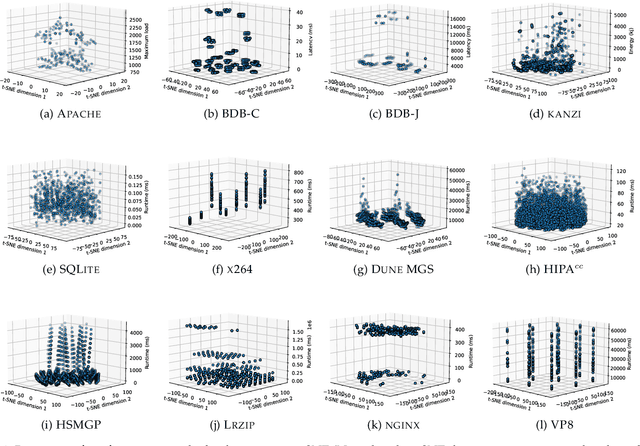
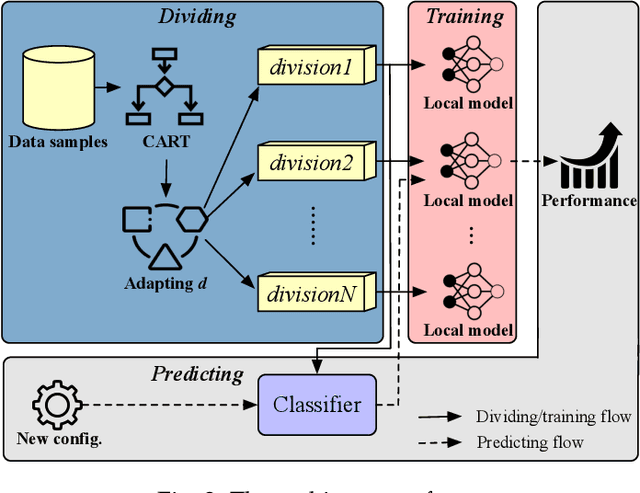

Machine/deep learning models have been widely adopted for predicting the configuration performance of software systems. However, a crucial yet unaddressed challenge is how to cater for the sparsity inherited from the configuration landscape: the influence of configuration options (features) and the distribution of data samples are highly sparse. In this paper, we propose a model-agnostic and sparsity-robust framework for predicting configuration performance, dubbed DaL, based on the new paradigm of dividable learning that builds a model via "divide-and-learn". To handle sample sparsity, the samples from the configuration landscape are divided into distant divisions, for each of which we build a sparse local model, e.g., regularized Hierarchical Interaction Neural Network, to deal with the feature sparsity. A newly given configuration would then be assigned to the right model of division for the final prediction. Further, DaL adaptively determines the optimal number of divisions required for a system and sample size without any extra training or profiling. Experiment results from 12 real-world systems and five sets of training data reveal that, compared with the state-of-the-art approaches, DaL performs no worse than the best counterpart on 44 out of 60 cases with up to 1.61x improvement on accuracy; requires fewer samples to reach the same/better accuracy; and producing acceptable training overhead. In particular, the mechanism that adapted the parameter d can reach the optimal value for 76.43% of the individual runs. The result also confirms that the paradigm of dividable learning is more suitable than other similar paradigms such as ensemble learning for predicting configuration performance. Practically, DaL considerably improves different global models when using them as the underlying local models, which further strengthens its flexibility.
Large Language Models for Explainable Decisions in Dynamic Digital Twins
May 23, 2024


Dynamic data-driven Digital Twins (DDTs) can enable informed decision-making and provide an optimisation platform for the underlying system. By leveraging principles of Dynamic Data-Driven Applications Systems (DDDAS), DDTs can formulate computational modalities for feedback loops, model updates and decision-making, including autonomous ones. However, understanding autonomous decision-making often requires technical and domain-specific knowledge. This paper explores using large language models (LLMs) to provide an explainability platform for DDTs, generating natural language explanations of the system's decision-making by leveraging domain-specific knowledge bases. A case study from smart agriculture is presented.
Dynamic Data-Driven Digital Twins for Blockchain Systems
Dec 07, 2023In recent years, we have seen an increase in the adoption of blockchain-based systems in non-financial applications, looking to benefit from what the technology has to offer. Although many fields have managed to include blockchain in their core functionalities, the adoption of blockchain, in general, is constrained by the so-called trilemma trade-off between decentralization, scalability, and security. In our previous work, we have shown that using a digital twin for dynamically managing blockchain systems during runtime can be effective in managing the trilemma trade-off. Our Digital Twin leverages DDDAS feedback loop, which is responsible for getting the data from the system to the digital twin, conducting optimisation, and updating the physical system. This paper examines how leveraging DDDAS feedback loop can support the optimisation component of the trilemma benefiting from Reinforcement Learning agents and a simulation component to augment the quality of the learned model while reducing the computational overhead required for decision-making.
Explainable Human-in-the-loop Dynamic Data-Driven Digital Twins
Jul 19, 2022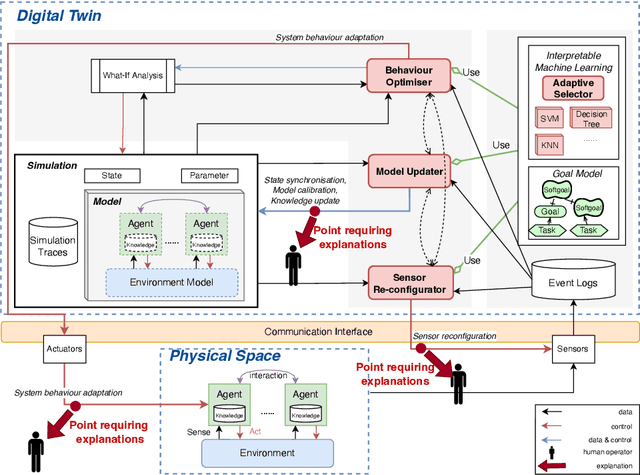
Digital Twins (DT) are essentially Dynamic Data-driven models that serve as real-time symbiotic "virtual replicas" of real-world systems. DT can leverage fundamentals of Dynamic Data-Driven Applications Systems (DDDAS) bidirectional symbiotic sensing feedback loops for its continuous updates. Sensing loops can consequently steer measurement, analysis and reconfiguration aimed at more accurate modelling and analysis in DT. The reconfiguration decisions can be autonomous or interactive, keeping human-in-the-loop. The trustworthiness of these decisions can be hindered by inadequate explainability of the rationale, and utility gained in implementing the decision for the given situation among alternatives. Additionally, different decision-making algorithms and models have varying complexity, quality and can result in different utility gained for the model. The inadequacy of explainability can limit the extent to which humans can evaluate the decisions, often leading to updates which are unfit for the given situation, erroneous, compromising the overall accuracy of the model. The novel contribution of this paper is an approach to harnessing explainability in human-in-the-loop DDDAS and DT systems, leveraging bidirectional symbiotic sensing feedback. The approach utilises interpretable machine learning and goal modelling to explainability, and considers trade-off analysis of utility gained. We use examples from smart warehousing to demonstrate the approach.
Digital Twins for Dynamic Management of Blockchain Systems
Apr 26, 2022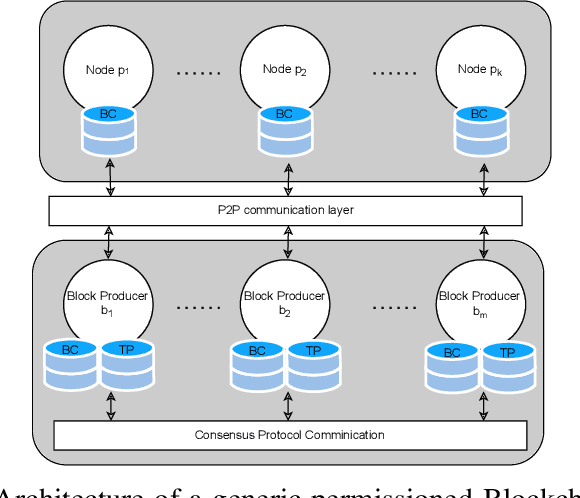
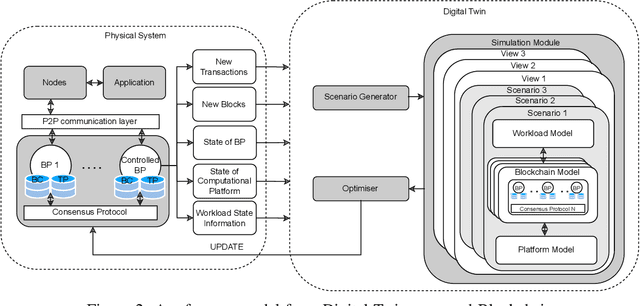
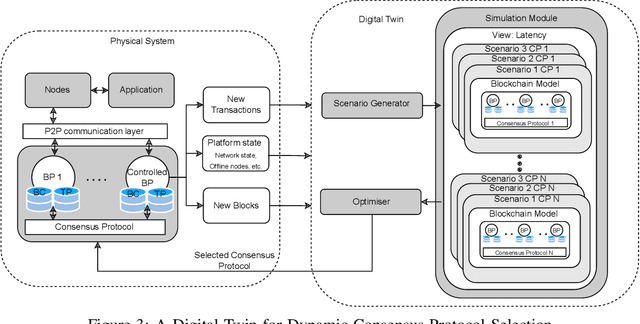
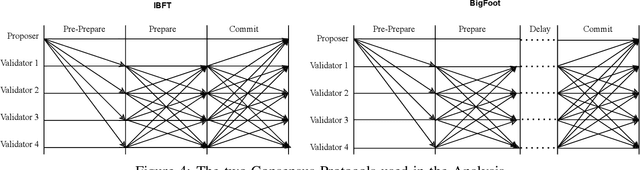
Blockchain systems are challenged by the so-called Trilemma tradeoff: decentralization, scalability and security. Infrastructure and node configuration, choice of the Consensus Protocol and complexity of the application transactions are cited amongst the factors that affect the tradeoffs balance. Given that Blockchains are complex, dynamic dynamic systems, a dynamic approach to their management and reconfiguration at runtime is deemed necessary to reflect the changes in the state of the infrastructure and application. This paper introduces the utilisation of Digital Twins for this purpose. The novel contribution of the paper is design of a framework and conceptual architecture of a Digital Twin that can assist in maintaining the Trilemma tradeoffs of time critical systems. The proposed Digital Twin is illustrated via an innovative approach to dynamic selection of Consensus Protocols. Simulations results show that the proposed framework can effectively support the dynamic adaptation and management of the Blockchain
Knowledge Equivalence in Digital Twins of Intelligent Systems
Apr 15, 2022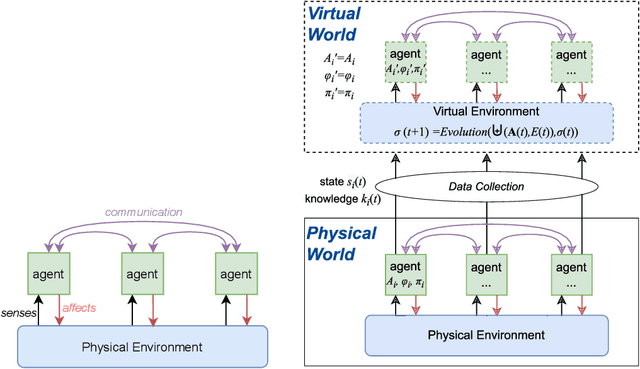
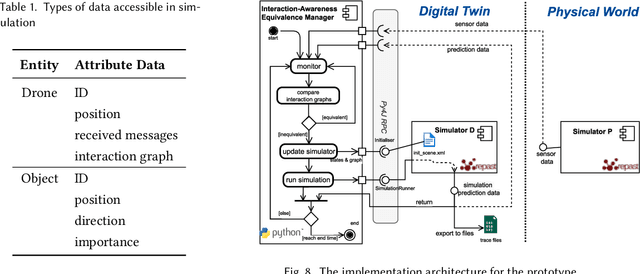
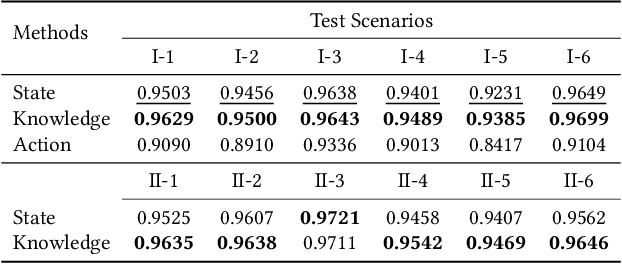
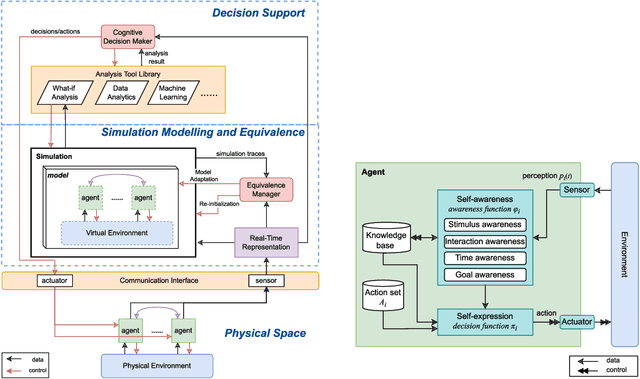
A digital twin contains up-to-date data-driven models of the physical world being studied and can use simulation to optimise the physical world. However, the analysis made by the digital twin is valid and reliable only when the model is equivalent to the physical world. Maintaining such an equivalent model is challenging, especially when the physical systems being modelled are intelligent and autonomous. The paper focuses in particular on digital twin models of intelligent systems where the systems are knowledge-aware but with limited capability. The digital twin improves the acting of the physical system at a meta-level by accumulating more knowledge in the simulated environment. The modelling of such an intelligent physical system requires replicating the knowledge-awareness capability in the virtual space. Novel equivalence maintaining techniques are needed, especially in synchronising the knowledge between the model and the physical system. This paper proposes the notion of knowledge equivalence and an equivalence maintaining approach by knowledge comparison and updates. A quantitative analysis of the proposed approach confirms that compared to state equivalence, knowledge equivalence maintenance can tolerate deviation thus reducing unnecessary updates and achieve more Pareto efficient solutions for the trade-off between update overhead and simulation reliability.
HUNTER: AI based Holistic Resource Management for Sustainable Cloud Computing
Oct 28, 2021
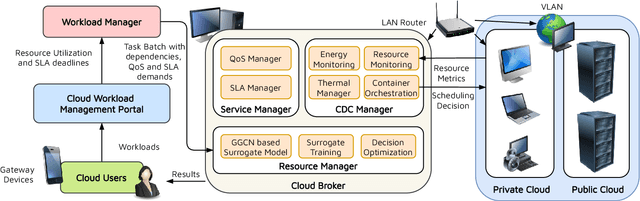
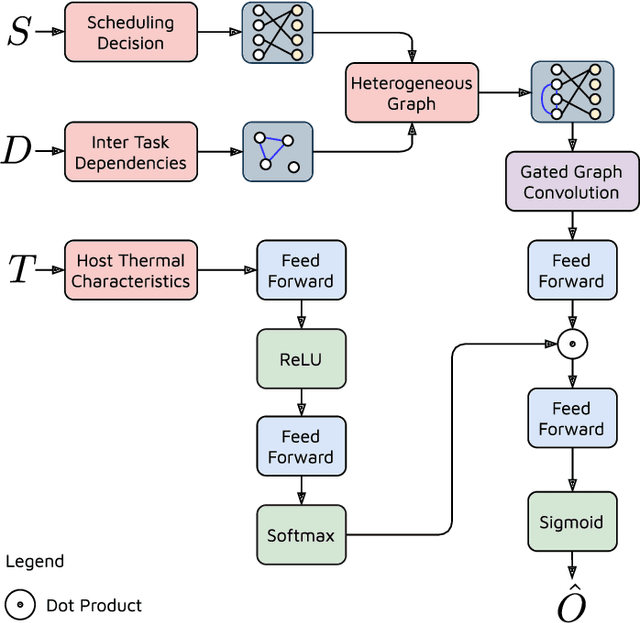
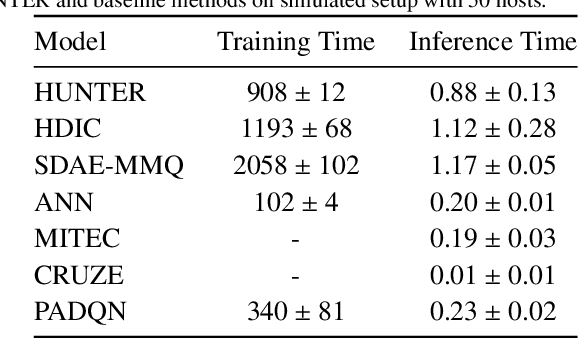
The worldwide adoption of cloud data centers (CDCs) has given rise to the ubiquitous demand for hosting application services on the cloud. Further, contemporary data-intensive industries have seen a sharp upsurge in the resource requirements of modern applications. This has led to the provisioning of an increased number of cloud servers, giving rise to higher energy consumption and, consequently, sustainability concerns. Traditional heuristics and reinforcement learning based algorithms for energy-efficient cloud resource management address the scalability and adaptability related challenges to a limited extent. Existing work often fails to capture dependencies across thermal characteristics of hosts, resource consumption of tasks and the corresponding scheduling decisions. This leads to poor scalability and an increase in the compute resource requirements, particularly in environments with non-stationary resource demands. To address these limitations, we propose an artificial intelligence (AI) based holistic resource management technique for sustainable cloud computing called HUNTER. The proposed model formulates the goal of optimizing energy efficiency in data centers as a multi-objective scheduling problem, considering three important models: energy, thermal and cooling. HUNTER utilizes a Gated Graph Convolution Network as a surrogate model for approximating the Quality of Service (QoS) for a system state and generating optimal scheduling decisions. Experiments on simulated and physical cloud environments using the CloudSim toolkit and the COSCO framework show that HUNTER outperforms state-of-the-art baselines in terms of energy consumption, SLA violation, scheduling time, cost and temperature by up to 12, 35, 43, 54 and 3 percent respectively.
Selecting Miners within Blockchain-based Systems Using Evolutionary Algorithms for Energy Optimisation
Jun 06, 2021
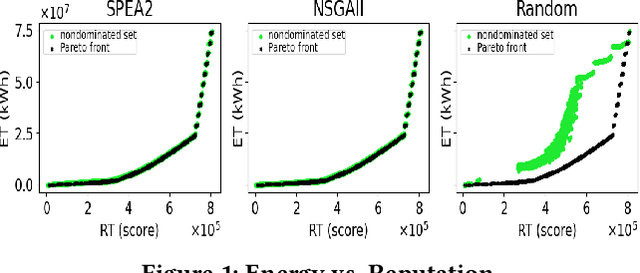
In this paper, we represent the problem of selecting miners within a blockchain-based system as a subset selection problem. We formulate the problem of minimising blockchain energy consumption as an optimisation problem with two conflicting objectives: energy consumption and trust. The proposed model is compared across different algorithms to demonstrate its performance.
Synergizing Domain Expertise with Self-Awareness in Software Systems: A Patternized Architecture Guideline
Jan 20, 2020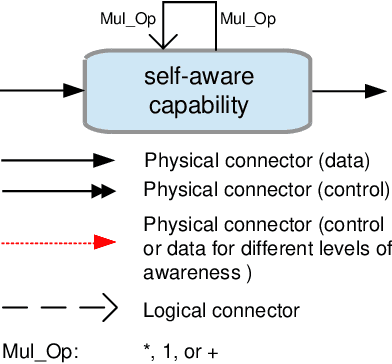
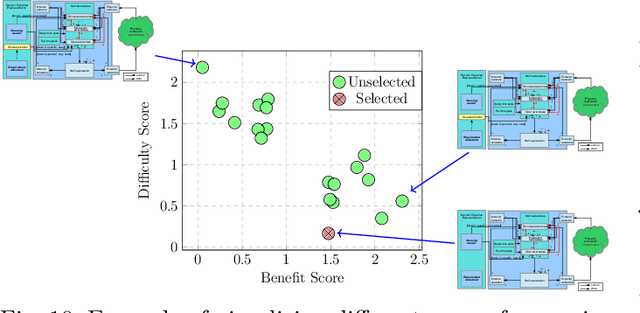
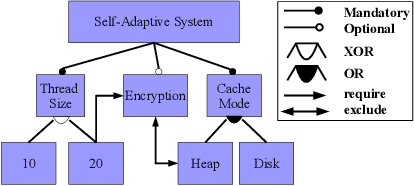
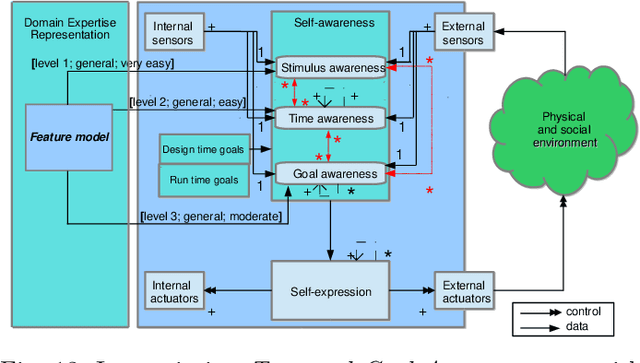
Architectural patterns provide a reusable architectural solution for commonly recurring problems that can assist in designing software systems. In this regard, self-awareness architectural patterns are specialized patterns that leverage good engineering practices and experiences to help in designing self-awareness and self-adaptation of a software system. However, domain knowledge and engineers' expertise that is built over time are not explicitly linked to these patterns and the self-aware process. This linkage is important, as it can enrich the design patterns of these systems, which consequently leads to more effective and efficient self-aware and self-adaptive behaviours. This paper is an introductory work that highlights the importance of synergizing domain expertise into the self-awareness in software systems, relying on well-defined underlying approaches. In particular, we present a holistic framework that classifies widely known representations used to obtain and maintain the domain expertise, documenting their nature and specifics rules that permits different levels of synergies with self-awareness. Drawing on such, we describe mechanisms that can enrich existing patterns with engineers' expertise and knowledge of the domain. This, together with the framework, allow us to codify an intuitive step-by-step methodology that guides engineer in making design decisions when synergizing domain expertise into self-awareness and reveal their importances, in an attempt to keep 'engineers-in-the-loop'. Through three case studies, we demonstrate how the enriched patterns, the proposed framework and methodology can be applied in different domains, within which we quantitatively compare the actual benefits of incorporating engineers' expertise into self-awareness, at alternative levels of synergies.