 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDividable Configuration Performance Learning
Paper and Code
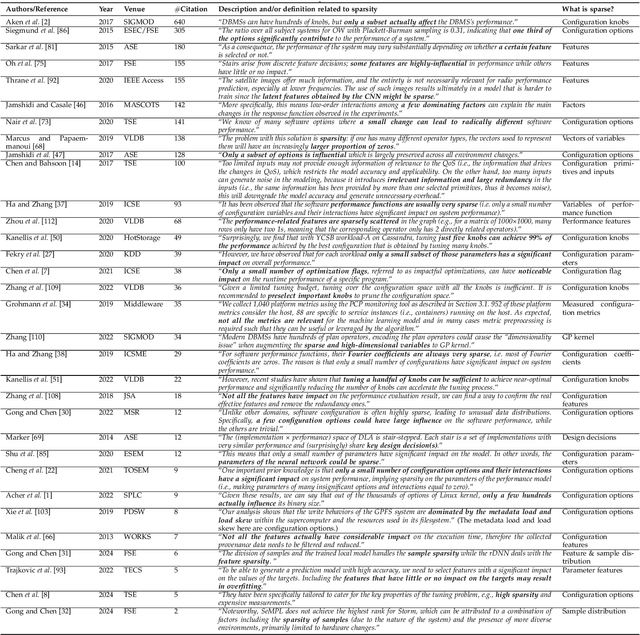
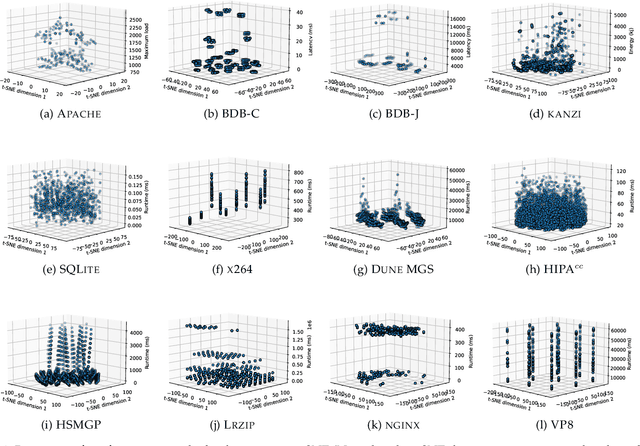
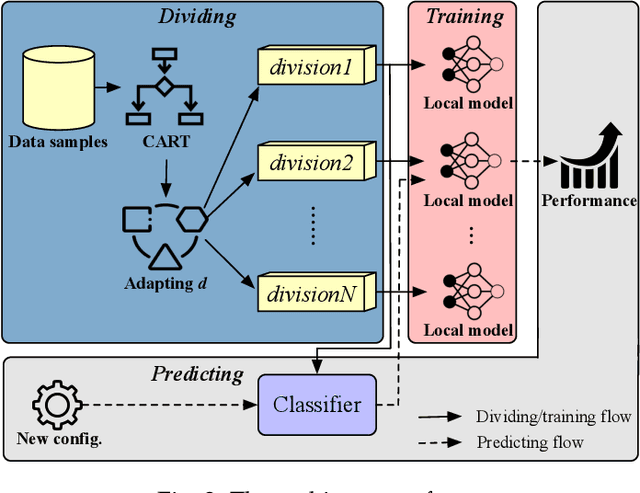

Machine/deep learning models have been widely adopted for predicting the configuration performance of software systems. However, a crucial yet unaddressed challenge is how to cater for the sparsity inherited from the configuration landscape: the influence of configuration options (features) and the distribution of data samples are highly sparse. In this paper, we propose a model-agnostic and sparsity-robust framework for predicting configuration performance, dubbed DaL, based on the new paradigm of dividable learning that builds a model via "divide-and-learn". To handle sample sparsity, the samples from the configuration landscape are divided into distant divisions, for each of which we build a sparse local model, e.g., regularized Hierarchical Interaction Neural Network, to deal with the feature sparsity. A newly given configuration would then be assigned to the right model of division for the final prediction. Further, DaL adaptively determines the optimal number of divisions required for a system and sample size without any extra training or profiling. Experiment results from 12 real-world systems and five sets of training data reveal that, compared with the state-of-the-art approaches, DaL performs no worse than the best counterpart on 44 out of 60 cases with up to 1.61x improvement on accuracy; requires fewer samples to reach the same/better accuracy; and producing acceptable training overhead. In particular, the mechanism that adapted the parameter d can reach the optimal value for 76.43% of the individual runs. The result also confirms that the paradigm of dividable learning is more suitable than other similar paradigms such as ensemble learning for predicting configuration performance. Practically, DaL considerably improves different global models when using them as the underlying local models, which further strengthens its flexibility.