 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkillMOO: Multi-Objective Optimization of Agent Skills for Software Engineering
Apr 10, 2026Agent skills provide modular, task-specific guidance for LLM- based coding agents, but manually tuning skill bundles to balance success rate, cost, and runtime is expensive and fragile. We present SkillMOO, a multi-objective optimization framework that automatically evolves skill bundles using LLM-proposed edits and NSGA-II survivor selection: a solver agent evaluates candidate skill bundles on coding tasks and an optimizer agent proposes bundle edits based on failure analysis. On three SkillsBench software engineering tasks, SkillMOO improves pass rate by up to 131% while reducing cost up to 32% relative to the best baseline per task at low optimization overhead. Pattern analysis reveals pruning and substitution as primary drivers of improvement, suggesting effective bundles favor minimal, focused content over accumulated instructions.
Not All Code Is Equal: A Data-Centric Study of Code Complexity and LLM Reasoning
Jan 29, 2026Large Language Models (LLMs) increasingly exhibit strong reasoning abilities, often attributed to their capacity to generate chain-of-thought-style intermediate reasoning. Recent work suggests that exposure to code can further enhance these skills, but existing studies largely treat code as a generic training signal, leaving open the question of which properties of code actually contribute to improved reasoning. To address this gap, we study the structural complexity of code, which captures control flow and compositional structure that may shape how models internalise multi-step reasoning during fine-tuning. We examine two complementary settings: solution-driven complexity, where complexity varies across multiple solutions to the same problem, and problem-driven complexity, where complexity reflects variation in the underlying tasks. Using cyclomatic complexity and logical lines of code to construct controlled fine-tuning datasets, we evaluate a range of open-weight LLMs on diverse reasoning benchmarks. Our findings show that although code can improve reasoning, structural properties strongly determine its usefulness. In 83% of experiments, restricting fine-tuning data to a specific structural complexity range outperforms training on structurally diverse code, pointing to a data-centric path for improving reasoning beyond scaling.
Analyzing Message-Code Inconsistency in AI Coding Agent-Authored Pull Requests
Jan 08, 2026Pull request (PR) descriptions generated by AI coding agents are the primary channel for communicating code changes to human reviewers. However, the alignment between these messages and the actual changes remains unexplored, raising concerns about the trustworthiness of AI agents. To fill this gap, we analyzed 23,247 agentic PRs across five agents using PR message-code inconsistency (PR-MCI). We contributed 974 manually annotated PRs, found 406 PRs (1.7%) exhibited high PR-MCI, and identified eight PR-MCI types, revealing that descriptions claiming unimplemented changes was the most common issue (45.4%). Statistical tests confirmed that high-MCI PRs had 51.7% lower acceptance rates (28.3% vs. 80.0%) and took 3.5x longer to merge (55.8 vs. 16.0 hours). Our findings suggest that unreliable PR descriptions undermine trust in AI agents, highlighting the need for PR-MCI verification mechanisms and improved PR generation to enable trustworthy human-AI collaboration.
Evolving Excellence: Automated Optimization of LLM-based Agents
Dec 09, 2025Agentic AI systems built on large language models (LLMs) offer significant potential for automating complex workflows, from software development to customer support. However, LLM agents often underperform due to suboptimal configurations; poorly tuned prompts, tool descriptions, and parameters that typically require weeks of manual refinement. Existing optimization methods either are too complex for general use or treat components in isolation, missing critical interdependencies. We present ARTEMIS, a no-code evolutionary optimization platform that jointly optimizes agent configurations through semantically-aware genetic operators. Given only a benchmark script and natural language goals, ARTEMIS automatically discovers configurable components, extracts performance signals from execution logs, and evolves configurations without requiring architectural modifications. We evaluate ARTEMIS on four representative agent systems: the \emph{ALE Agent} for competitive programming on AtCoder Heuristic Contest, achieving a \textbf{$13.6\%$ improvement} in acceptance rate; the \emph{Mini-SWE Agent} for code optimization on SWE-Perf, with a statistically significant \textbf{10.1\% performance gain}; and the \emph{CrewAI Agent} for cost and mathematical reasoning on Math Odyssey, achieving a statistically significant \textbf{$36.9\%$ reduction} in the number of tokens required for evaluation. We also evaluate the \emph{MathTales-Teacher Agent} powered by a smaller open-source model (Qwen2.5-7B) on GSM8K primary-level mathematics problems, achieving a \textbf{22\% accuracy improvement} and demonstrating that ARTEMIS can optimize agents based on both commercial and local models.
Accuracy Can Lie: On the Impact of Surrogate Model in Configuration Tuning
Jan 03, 2025



To ease the expensive measurements during configuration tuning, it is natural to build a surrogate model as the replacement of the system, and thereby the configuration performance can be cheaply evaluated. Yet, a stereotype therein is that the higher the model accuracy, the better the tuning result would be. This "accuracy is all" belief drives our research community to build more and more accurate models and criticize a tuner for the inaccuracy of the model used. However, this practice raises some previously unaddressed questions, e.g., Do those somewhat small accuracy improvements reported in existing work really matter much to the tuners? What role does model accuracy play in the impact of tuning quality? To answer those related questions, we conduct one of the largest-scale empirical studies to date-running over the period of 13 months 24*7-that covers 10 models, 17 tuners, and 29 systems from the existing works while under four different commonly used metrics, leading to 13,612 cases of investigation. Surprisingly, our key findings reveal that the accuracy can lie: there are a considerable number of cases where higher accuracy actually leads to no improvement in the tuning outcomes (up to 58% cases under certain setting), or even worse, it can degrade the tuning quality (up to 24% cases under certain setting). We also discover that the chosen models in most proposed tuners are sub-optimal and that the required % of accuracy change to significantly improve tuning quality varies according to the range of model accuracy. Deriving from the fitness landscape analysis, we provide in-depth discussions of the rationale behind, offering several lessons learned as well as insights for future opportunities. Most importantly, this work poses a clear message to the community: we should take one step back from the natural "accuracy is all" belief for model-based configuration tuning.
Dividable Configuration Performance Learning
Sep 11, 2024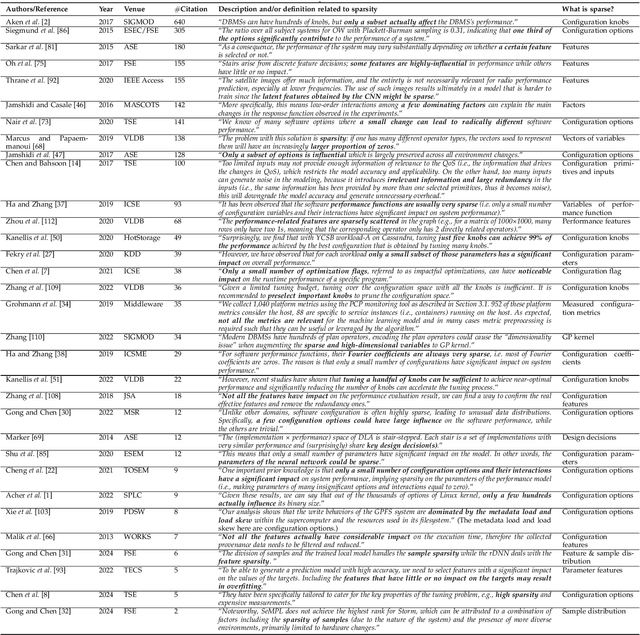
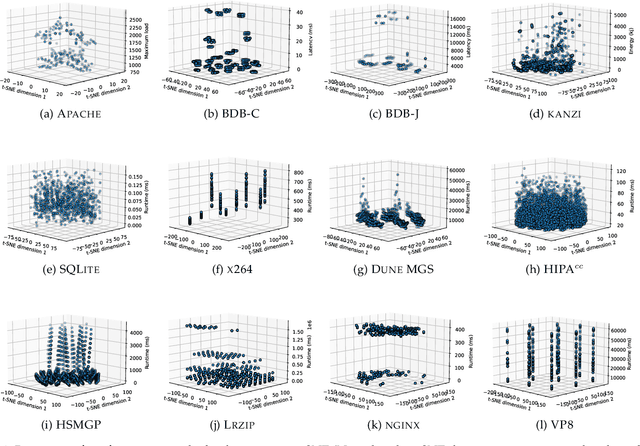
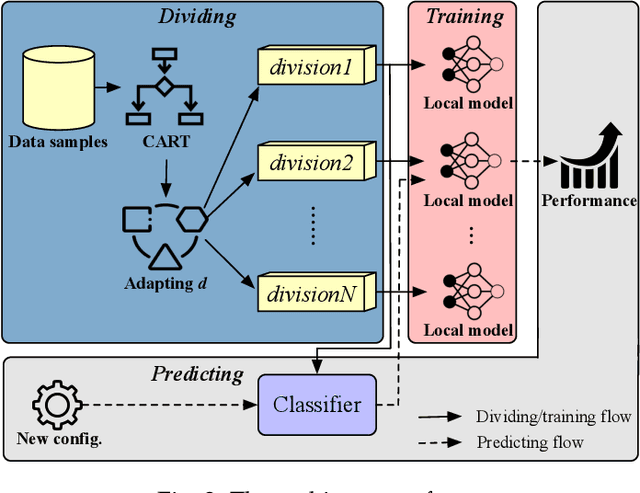

Machine/deep learning models have been widely adopted for predicting the configuration performance of software systems. However, a crucial yet unaddressed challenge is how to cater for the sparsity inherited from the configuration landscape: the influence of configuration options (features) and the distribution of data samples are highly sparse. In this paper, we propose a model-agnostic and sparsity-robust framework for predicting configuration performance, dubbed DaL, based on the new paradigm of dividable learning that builds a model via "divide-and-learn". To handle sample sparsity, the samples from the configuration landscape are divided into distant divisions, for each of which we build a sparse local model, e.g., regularized Hierarchical Interaction Neural Network, to deal with the feature sparsity. A newly given configuration would then be assigned to the right model of division for the final prediction. Further, DaL adaptively determines the optimal number of divisions required for a system and sample size without any extra training or profiling. Experiment results from 12 real-world systems and five sets of training data reveal that, compared with the state-of-the-art approaches, DaL performs no worse than the best counterpart on 44 out of 60 cases with up to 1.61x improvement on accuracy; requires fewer samples to reach the same/better accuracy; and producing acceptable training overhead. In particular, the mechanism that adapted the parameter d can reach the optimal value for 76.43% of the individual runs. The result also confirms that the paradigm of dividable learning is more suitable than other similar paradigms such as ensemble learning for predicting configuration performance. Practically, DaL considerably improves different global models when using them as the underlying local models, which further strengthens its flexibility.
GreenStableYolo: Optimizing Inference Time and Image Quality of Text-to-Image Generation
Jul 20, 2024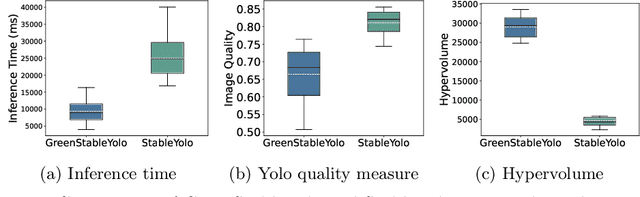
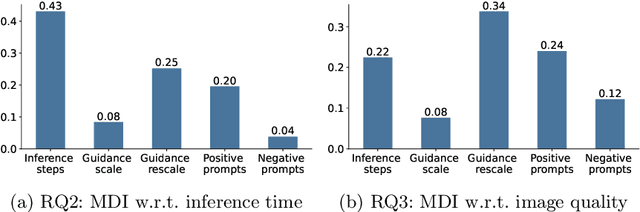
Tuning the parameters and prompts for improving AI-based text-to-image generation has remained a substantial yet unaddressed challenge. Hence we introduce GreenStableYolo, which improves the parameters and prompts for Stable Diffusion to both reduce GPU inference time and increase image generation quality using NSGA-II and Yolo. Our experiments show that despite a relatively slight trade-off (18%) in image quality compared to StableYolo (which only considers image quality), GreenStableYolo achieves a substantial reduction in inference time (266% less) and a 526% higher hypervolume, thereby advancing the state-of-the-art for text-to-image generation.
Pushing the Boundary: Specialising Deep Configuration Performance Learning
Jul 02, 2024
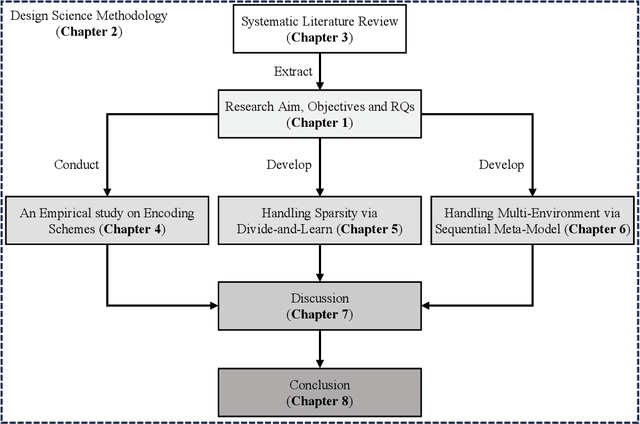

Software systems often have numerous configuration options that can be adjusted to meet different performance requirements. However, understanding the combined impact of these options on performance is often challenging, especially with limited real-world data. To tackle this issue, deep learning techniques have gained popularity due to their ability to capture complex relationships even with limited samples. This thesis begins with a systematic literature review of deep learning techniques in configuration performance modeling, analyzing 85 primary papers out of 948 searched papers. It identifies knowledge gaps and sets three objectives for the thesis. The first knowledge gap is the lack of understanding about which encoding scheme is better and in what circumstances. To address this, the thesis conducts an empirical study comparing three popular encoding schemes. Actionable suggestions are provided to support more reliable decisions. Another knowledge gap is the sparsity inherited from the configuration landscape. To handle this, the thesis proposes a model-agnostic and sparsity-robust framework called DaL, which uses a "divide-and-learn" approach. DaL outperforms state-of-the-art approaches in accuracy improvement across various real-world systems. The thesis also addresses the limitation of predicting under static environments by proposing a sequential meta-learning framework called SeMPL. Unlike traditional meta-learning frameworks, SeMPL trains meta-environments in a specialized order, resulting in significantly improved prediction accuracy in multi-environment scenarios. Overall, the thesis identifies and addresses critical knowledge gaps in deep performance learning, significantly advancing the accuracy of performance prediction.
Deep Configuration Performance Learning: A Systematic Survey and Taxonomy
Mar 05, 2024Performance is arguably the most crucial attribute that reflects the behavior of a configurable software system. However, given the increasing scale and complexity of modern software, modeling and predicting how various configurations can impact performance becomes one of the major challenges in software maintenance. As such, performance is often modeled without having a thorough knowledge of the software system, but relying mainly on data, which fits precisely with the purpose of deep learning. In this paper, we conduct a comprehensive review exclusively on the topic of deep learning for performance learning of configurable software, covering 948 searched papers spanning six indexing services, based on which 85 primary papers were extracted and analyzed. Our results summarize the key topics and statistics on how the configuration data is prepared; how the deep configuration performance learning model is built; how the model is evaluated and how they are exploited in different tasks related to software configuration. We also identify the good practice and the potentially problematic phenomena from the studies surveyed, together with insights on future opportunities for the field. To promote open science, all the raw results of this survey can be accessed at our repository: https://github.com/ideas-labo/DCPL-SLR.
Predicting Configuration Performance in Multiple Environments with Sequential Meta-learning
Feb 05, 2024Learning and predicting the performance of given software configurations are of high importance to many software engineering activities. While configurable software systems will almost certainly face diverse running environments (e.g., version, hardware, and workload), current work often either builds performance models under a single environment or fails to properly handle data from diverse settings, hence restricting their accuracy for new environments. In this paper, we target configuration performance learning under multiple environments. We do so by designing SeMPL - a meta-learning framework that learns the common understanding from configurations measured in distinct (meta) environments and generalizes them to the unforeseen, target environment. What makes it unique is that unlike common meta-learning frameworks (e.g., MAML and MetaSGD) that train the meta environments in parallel, we train them sequentially, one at a time. The order of training naturally allows discriminating the contributions among meta environments in the meta-model built, which fits better with the characteristic of configuration data that is known to dramatically differ between different environments. Through comparing with 15 state-of-the-art models under nine systems, our extensive experimental results demonstrate that SeMPL performs considerably better on 89% of the systems with up to 99% accuracy improvement, while being data-efficient, leading to a maximum of 3.86x speedup. All code and data can be found at our repository: https://github.com/ideas-labo/SeMPL.