 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushing the Boundary: Specialising Deep Configuration Performance Learning
Paper and Code
Jul 02, 2024
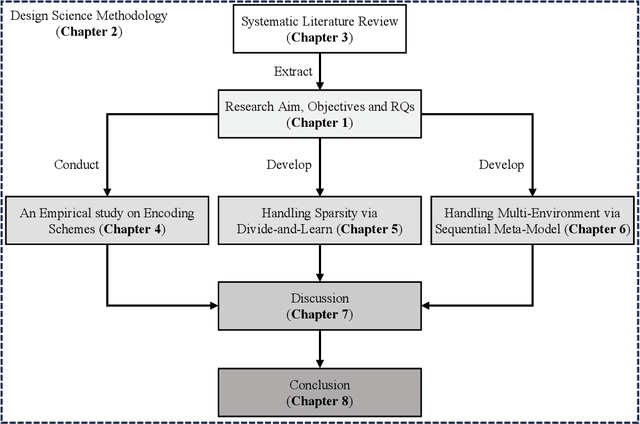

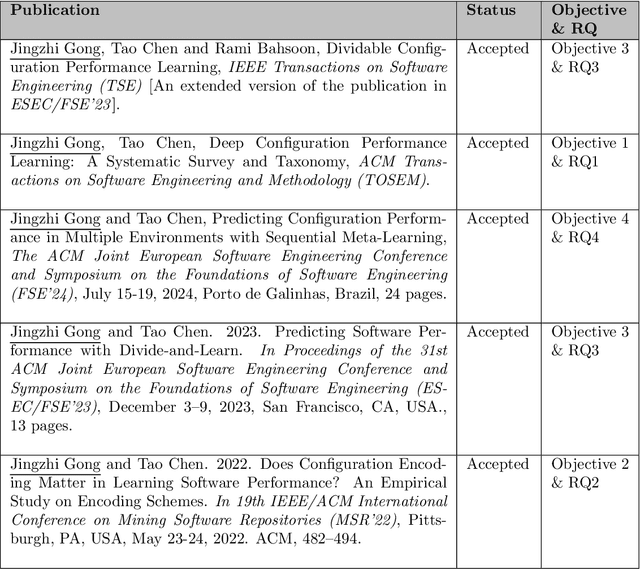
Software systems often have numerous configuration options that can be adjusted to meet different performance requirements. However, understanding the combined impact of these options on performance is often challenging, especially with limited real-world data. To tackle this issue, deep learning techniques have gained popularity due to their ability to capture complex relationships even with limited samples. This thesis begins with a systematic literature review of deep learning techniques in configuration performance modeling, analyzing 85 primary papers out of 948 searched papers. It identifies knowledge gaps and sets three objectives for the thesis. The first knowledge gap is the lack of understanding about which encoding scheme is better and in what circumstances. To address this, the thesis conducts an empirical study comparing three popular encoding schemes. Actionable suggestions are provided to support more reliable decisions. Another knowledge gap is the sparsity inherited from the configuration landscape. To handle this, the thesis proposes a model-agnostic and sparsity-robust framework called DaL, which uses a "divide-and-learn" approach. DaL outperforms state-of-the-art approaches in accuracy improvement across various real-world systems. The thesis also addresses the limitation of predicting under static environments by proposing a sequential meta-learning framework called SeMPL. Unlike traditional meta-learning frameworks, SeMPL trains meta-environments in a specialized order, resulting in significantly improved prediction accuracy in multi-environment scenarios. Overall, the thesis identifies and addresses critical knowledge gaps in deep performance learning, significantly advancing the accuracy of performance prediction.