 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGUNet: A Graph Convolutional Network United Diffusion Model for Stable and Diversity Pose Generation
Sep 18, 2024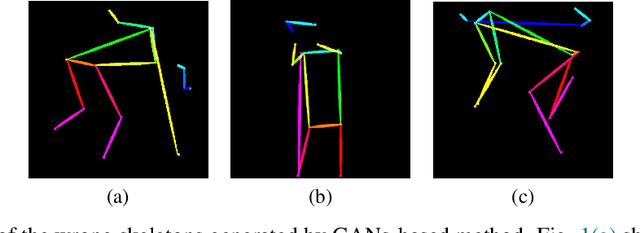



Pose skeleton images are an important reference in pose-controllable image generation. In order to enrich the source of skeleton images, recent works have investigated the generation of pose skeletons based on natural language. These methods are based on GANs. However, it remains challenging to perform diverse, structurally correct and aesthetically pleasing human pose skeleton generation with various textual inputs. To address this problem, we propose a framework with GUNet as the main model, PoseDiffusion. It is the first generative framework based on a diffusion model and also contains a series of variants fine-tuned based on a stable diffusion model. PoseDiffusion demonstrates several desired properties that outperform existing methods. 1) Correct Skeletons. GUNet, a denoising model of PoseDiffusion, is designed to incorporate graphical convolutional neural networks. It is able to learn the spatial relationships of the human skeleton by introducing skeletal information during the training process. 2) Diversity. We decouple the key points of the skeleton and characterise them separately, and use cross-attention to introduce textual conditions. Experimental results show that PoseDiffusion outperforms existing SoTA algorithms in terms of stability and diversity of text-driven pose skeleton generation. Qualitative analyses further demonstrate its superiority for controllable generation in Stable Diffusion.
GreenStableYolo: Optimizing Inference Time and Image Quality of Text-to-Image Generation
Jul 20, 2024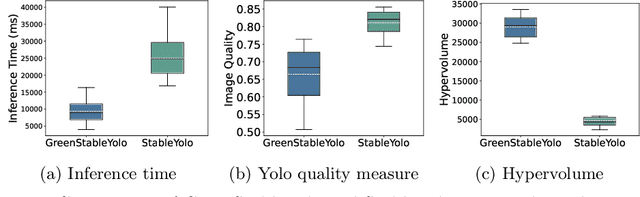
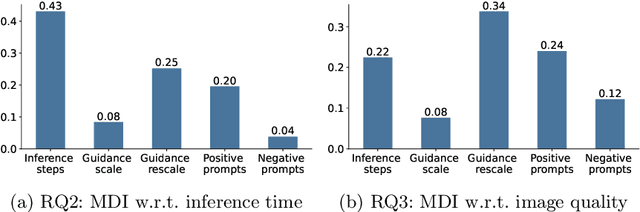
Tuning the parameters and prompts for improving AI-based text-to-image generation has remained a substantial yet unaddressed challenge. Hence we introduce GreenStableYolo, which improves the parameters and prompts for Stable Diffusion to both reduce GPU inference time and increase image generation quality using NSGA-II and Yolo. Our experiments show that despite a relatively slight trade-off (18%) in image quality compared to StableYolo (which only considers image quality), GreenStableYolo achieves a substantial reduction in inference time (266% less) and a 526% higher hypervolume, thereby advancing the state-of-the-art for text-to-image generation.
Decision making in dynamic and interactive environments based on cognitive hierarchy theory, Bayesian inference, and predictive control
Sep 14, 2019


n this paper, we describe an integrated framework for autonomous decision making in a dynamic and interactive environment. We model the interactions between the ego agent and its operating environment as a two-player dynamic game, and integrate cognitive behavioral models, Bayesian inference, and receding-horizon optimal control to define a dynamically-evolving decision strategy for the ego agent. Simulation examples representing autonomous vehicle control in three traffic scenarios where the autonomous ego vehicle interacts with a human-driven vehicle are reported.
Adaptive Game-Theoretic Decision Making for Autonomous Vehicle Control at Roundabouts
Oct 01, 2018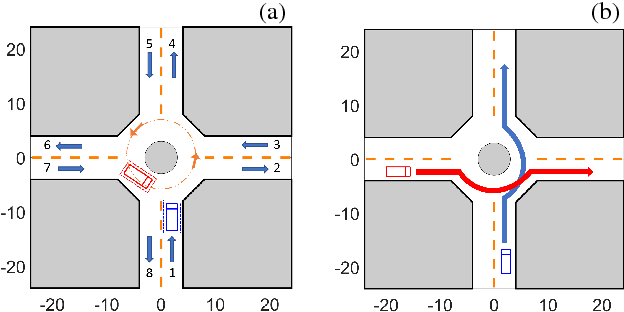
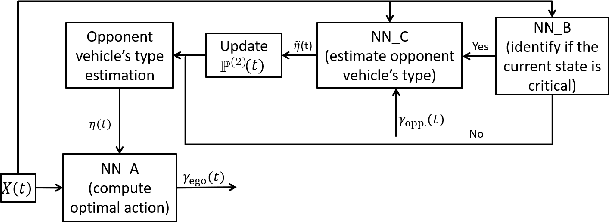
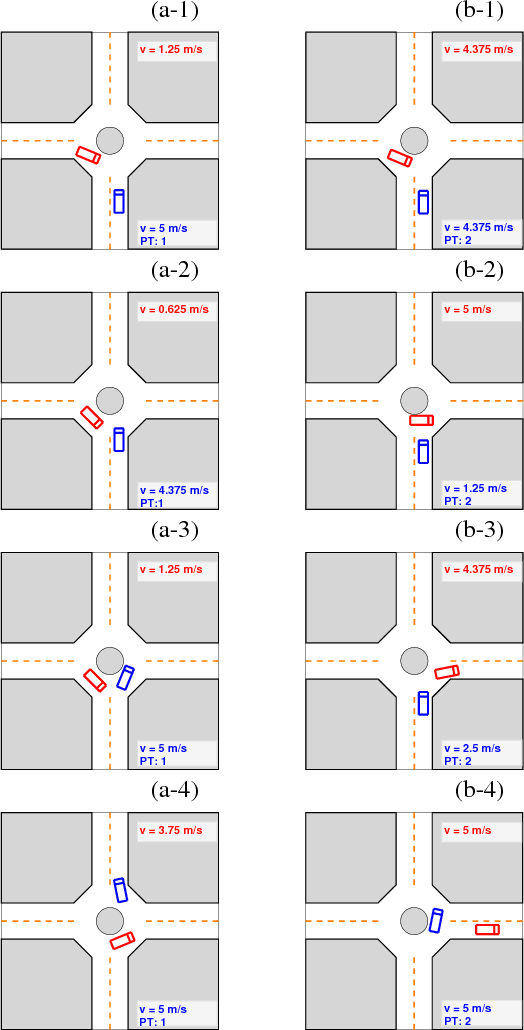
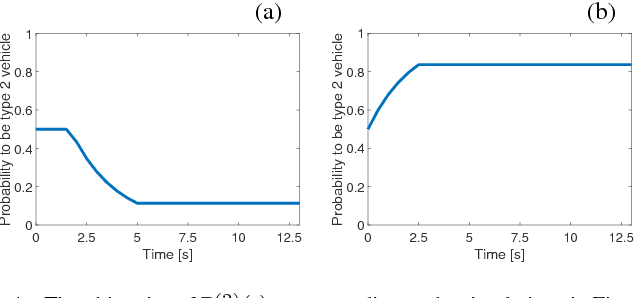
In this paper, we propose a decision making algorithm for autonomous vehicle control at a roundabout intersection. The algorithm is based on a game-theoretic model representing the interactions between the ego vehicle and an opponent vehicle, and adapts to an online estimated driver type of the opponent vehicle. Simulation results are reported.
Cluster Naturalistic Driving Encounters Using Deep Unsupervised Learning
Jun 06, 2018



Learning knowledge from driving encounters could help self-driving cars make appropriate decisions when driving in complex settings with nearby vehicles engaged. This paper develops an unsupervised classifier to group naturalistic driving encounters into distinguishable clusters by combining an auto-encoder with k-means clustering (AE-kMC). The effectiveness of AE-kMC was validated using the data of 10,000 naturalistic driving encounters which were collected by the University of Michigan, Ann Arbor in the past five years. We compare our developed method with the $k$-means clustering methods and experimental results demonstrate that the AE-kMC method outperforms the original k-means clustering method.
Extraction of V2V Encountering Scenarios from Naturalistic Driving Database
May 23, 2018



It is necessary to thoroughly evaluate the effectiveness and safety of Connected Vehicles (CVs) algorithm before their release and deployment. Current evaluation approach mainly relies on simulation platform with the single-vehicle driving model. The main drawback of it is the lack of network realism. To overcome this problem, we extract naturalistic V2V encounters data from the database, and then separate the primary vehicle encounter category by clustering. A fast mining algorithm is proposed that can be applied to parallel query for further process acceleration. 4,500 encounters are mined from a 275 GB database collected in the Safety Pilot Model Program in Ann Arbor Michigan, USA. K-means and Dynamic Time Warping (DTW) are used in clustering. Results show this method can quickly mine and cluster primary driving scenarios from a large database. Our results separate the car-following, intersection and by-passing, which are the primary category of the vehicle encounter. We anticipate the work in the essay can become a general method to effectively extract vehicle encounters from any existing database that contains vehicular GPS information. What's more, the naturalistic data of different vehicle encounters can be applied in Connected Vehicles evaluation.