 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Software Engineering Through Closed-Loop Memory Optimization
Jun 04, 2026Large language models (LLMs) have enabled powerful software engineering (SE) agents capable of navigating complex codebases and resolving real-world issues. However, these agents remain fundamentally episodic: they fail to retain, refine, and reuse experiences across tasks, repeatedly reconstructing context from scratch and reproducing similar mistakes. Even with memory support, they offer no remedy for the absence of a principled, task-agnostic \textit{memory utility}, making them difficult to evaluate rigorously or generalize across agents and settings. To tackle these limitations, we introduce \ours, a closed-loop framework for memory augmentation in SE agents. \ours grounds memory utility in \textit{validated downstream impact}, establishing utility as both a task-agnostic \textbf{evaluation benchmark} and an annotation-free \textbf{optimization signal}. Through complementary evaluation on \textit{single-episode} and \textit{cross-episode} memory augmentation, results demonstrate that \ours consistently improves SE agents across settings, achieving absolute gains of up to $\uparrow5.25\%$ in success rate and $\uparrow4.63\%$ in resolve efficiency, while substantially reducing computational cost by $\geq9.79\%$. Our project page: \href{https://xhguo7.github.io/MemOp/}{https://xhguo7.github.io/MemOp/}.
When to Think, When to Speak: Learning Disclosure Policies for LLM Reasoning
May 05, 2026In single-stream autoregressive interfaces, the same tokens both update the model state and constitute an irreversible public commitment. This coupling creates a \emph{silence tax}: additional deliberation postpones the first \emph{task-relevant} content, while naive early streaming risks premature commitments that bias subsequent generations. We introduce \textbf{\emph{Side-by-Side (SxS)}} Interleaved Reasoning, which makes \emph{disclosure timing} a controllable decision within standard autoregressive generation. SxS interleaves partial disclosures with continued private reasoning in the same context, but releases content only when it is \emph{supported} by the reasoning so far. To learn such pacing without incentivizing filler, we construct entailment-aligned interleaved trajectories by matching answer prefixes to supporting reasoning prefixes, then train with SFT to acquire the dual-action semantics and RL to recover reasoning performance under the new format. Across two Qwen3 architectures/scales (MoE \textbf{Qwen3-30B-A3B}, dense \textbf{Qwen3-4B}) and both in-domain (AIME25) and out-of-domain (GPQA-Diamond) benchmarks, SxS improves accuracy--\emph{content-latency} Pareto trade-offs under token-level proxies (e.g., inter-update waiting).
FinRule-Bench: A Benchmark for Joint Reasoning over Financial Tables and Principles
Mar 11, 2026Large language models (LLMs) are increasingly applied to financial analysis, yet their ability to audit structured financial statements under explicit accounting principles remains poorly explored. Existing benchmarks primarily evaluate question answering, numerical reasoning, or anomaly detection on synthetically corrupted data, making it unclear whether models can reliably verify or localize rule compliance on correct financial statements. We introduce FinRule-Bench, a benchmark for evaluating diagnostic completeness in rule-based financial reasoning over real-world financial tables. FinRule-Bench pairs ground-truth financial statements with explicit, human-curated accounting principles and spans four canonical statement types: Balance Sheets, Cash Flow Statements, Income Statements, and Statements of Equity. The benchmark defines three auditing tasks that require progressively stronger reasoning capabilities: (i) rule verification, which tests compliance with a single principle; (ii) rule identification, which requires selecting the violated principle from a provided rule set; and (iii) joint rule diagnosis, which requires detecting and localizing multiple simultaneous violations at the record level. We evaluate LLMs under zero-shot and few-shot prompting, and introduce a causal-counterfactual reasoning protocol that enforces consistency between decisions, explanations, and counterfactual judgments. Across tasks and statement types, we find that while models perform well on isolated rule verification, performance degrades sharply for rule discrimination and multi-violation diagnosis. FinRule-Bench provides a principled and reproducible testbed for studying rule-governed reasoning, diagnostic coverage, and failure modes of LLMs in high-stakes financial analysis.
SciDER: Scientific Data-centric End-to-end Researcher
Mar 02, 2026Automated scientific discovery with large language models is transforming the research lifecycle from ideation to experimentation, yet existing agents struggle to autonomously process raw data collected from scientific experiments. We introduce SciDER, a data-centric end-to-end system that automates the research lifecycle. Unlike traditional frameworks, our specialized agents collaboratively parse and analyze raw scientific data, generate hypotheses and experimental designs grounded in specific data characteristics, and write and execute corresponding code. Evaluation on three benchmarks shows SciDER excels in specialized data-driven scientific discovery and outperforms general-purpose agents and state-of-the-art models through its self-evolving memory and critic-led feedback loop. Distributed as a modular Python package, we also provide easy-to-use PyPI packages with a lightweight web interface to accelerate autonomous, data-driven research and aim to be accessible to all researchers and developers.
Anagent For Enhancing Scientific Table & Figure Analysis
Feb 12, 2026In scientific research, analysis requires accurately interpreting complex multimodal knowledge, integrating evidence from different sources, and drawing inferences grounded in domain-specific knowledge. However, current artificial intelligence (AI) systems struggle to consistently demonstrate such capabilities. The complexity and variability of scientific tables and figures, combined with heterogeneous structures and long-context requirements, pose fundamental obstacles to scientific table \& figure analysis. To quantify these challenges, we introduce AnaBench, a large-scale benchmark featuring $63,178$ instances from nine scientific domains, systematically categorized along seven complexity dimensions. To tackle these challenges, we propose Anagent, a multi-agent framework for enhanced scientific table \& figure analysis through four specialized agents: Planner decomposes tasks into actionable subtasks, Expert retrieves task-specific information through targeted tool execution, Solver synthesizes information to generate coherent analysis, and Critic performs iterative refinement through five-dimensional quality assessment. We further develop modular training strategies that leverage supervised finetuning and specialized reinforcement learning to optimize individual capabilities while maintaining effective collaboration. Comprehensive evaluation across 9 broad domains with 170 subdomains demonstrates that Anagent achieves substantial improvements, up to $\uparrow 13.43\%$ in training-free settings and $\uparrow 42.12\%$ with finetuning, while revealing that task-oriented reasoning and context-aware problem-solving are essential for high-quality scientific table \& figure analysis. Our project page: https://xhguo7.github.io/Anagent/.
oMeBench: Towards Robust Benchmarking of LLMs in Organic Mechanism Elucidation and Reasoning
Oct 09, 2025Organic reaction mechanisms are the stepwise elementary reactions by which reactants form intermediates and products, and are fundamental to understanding chemical reactivity and designing new molecules and reactions. Although large language models (LLMs) have shown promise in understanding chemical tasks such as synthesis design, it is unclear to what extent this reflects genuine chemical reasoning capabilities, i.e., the ability to generate valid intermediates, maintain chemical consistency, and follow logically coherent multi-step pathways. We address this by introducing oMeBench, the first large-scale, expert-curated benchmark for organic mechanism reasoning in organic chemistry. It comprises over 10,000 annotated mechanistic steps with intermediates, type labels, and difficulty ratings. Furthermore, to evaluate LLM capability more precisely and enable fine-grained scoring, we propose oMeS, a dynamic evaluation framework that combines step-level logic and chemical similarity. We analyze the performance of state-of-the-art LLMs, and our results show that although current models display promising chemical intuition, they struggle with correct and consistent multi-step reasoning. Notably, we find that using prompting strategy and fine-tuning a specialist model on our proposed dataset increases performance by 50% over the leading closed-source model. We hope that oMeBench will serve as a rigorous foundation for advancing AI systems toward genuine chemical reasoning.
Affine Modulation-based Audiogram Fusion Network for Joint Noise Reduction and Hearing Loss Compensation
Sep 09, 2025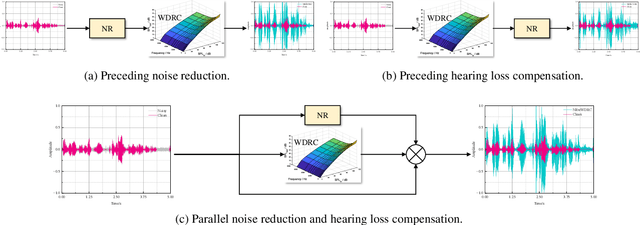
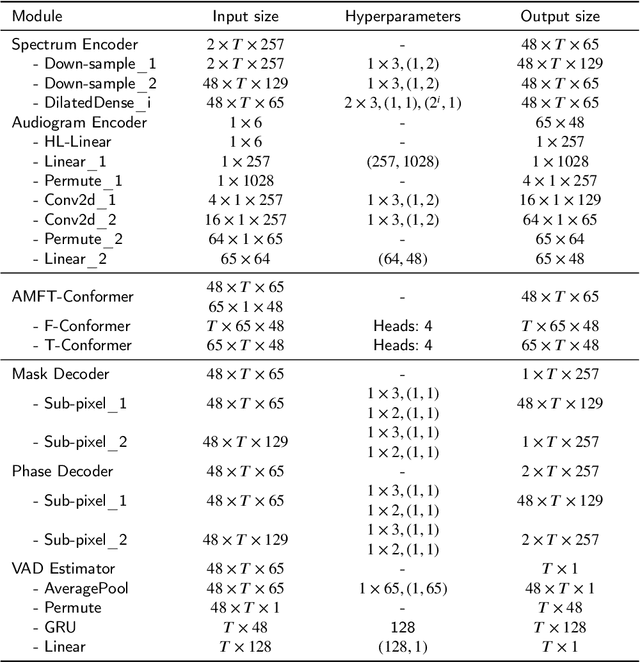
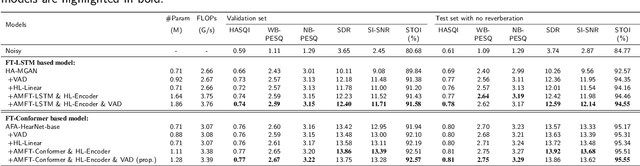
Hearing aids (HAs) are widely used to provide personalized speech enhancement (PSE) services, improving the quality of life for individuals with hearing loss. However, HA performance significantly declines in noisy environments as it treats noise reduction (NR) and hearing loss compensation (HLC) as separate tasks. This separation leads to a lack of systematic optimization, overlooking the interactions between these two critical tasks, and increases the system complexity. To address these challenges, we propose a novel audiogram fusion network, named AFN-HearNet, which simultaneously tackles the NR and HLC tasks by fusing cross-domain audiogram and spectrum features. We propose an audiogram-specific encoder that transforms the sparse audiogram profile into a deep representation, addressing the alignment problem of cross-domain features prior to fusion. To incorporate the interactions between NR and HLC tasks, we propose the affine modulation-based audiogram fusion frequency-temporal Conformer that adaptively fuses these two features into a unified deep representation for speech reconstruction. Furthermore, we introduce a voice activity detection auxiliary training task to embed speech and non-speech patterns into the unified deep representation implicitly. We conduct comprehensive experiments across multiple datasets to validate the effectiveness of each proposed module. The results indicate that the AFN-HearNet significantly outperforms state-of-the-art in-context fusion joint models regarding key metrics such as HASQI and PESQ, achieving a considerable trade-off between performance and efficiency. The source code and data will be released at https://github.com/deepnetni/AFN-HearNet.
Atomic Reasoning for Scientific Table Claim Verification
Jun 08, 2025Scientific texts often convey authority due to their technical language and complex data. However, this complexity can sometimes lead to the spread of misinformation. Non-experts are particularly susceptible to misleading claims based on scientific tables due to their high information density and perceived credibility. Existing table claim verification models, including state-of-the-art large language models (LLMs), often struggle with precise fine-grained reasoning, resulting in errors and a lack of precision in verifying scientific claims. Inspired by Cognitive Load Theory, we propose that enhancing a model's ability to interpret table-based claims involves reducing cognitive load by developing modular, reusable reasoning components (i.e., atomic skills). We introduce a skill-chaining schema that dynamically composes these skills to facilitate more accurate and generalizable reasoning with a reduced cognitive load. To evaluate this, we create SciAtomicBench, a cross-domain benchmark with fine-grained reasoning annotations. With only 350 fine-tuning examples, our model trained by atomic reasoning outperforms GPT-4o's chain-of-thought method, achieving state-of-the-art results with far less training data.
Explain Less, Understand More: Jargon Detection via Personalized Parameter-Efficient Fine-tuning
May 22, 2025
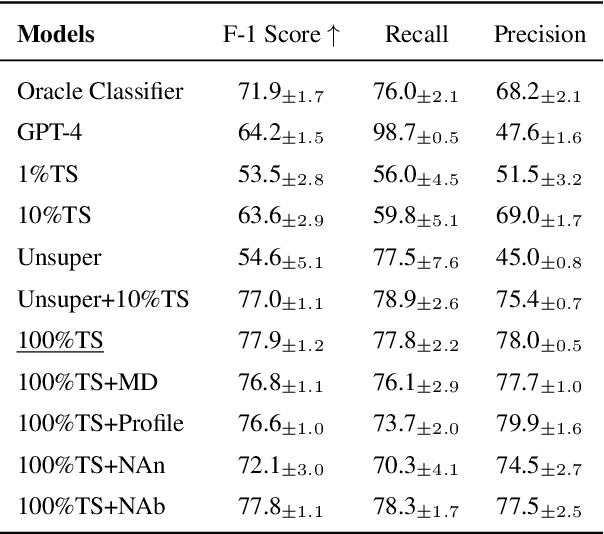
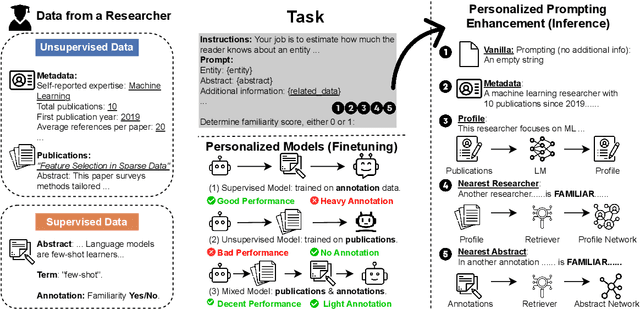

Personalizing jargon detection and explanation is essential for making technical documents accessible to readers with diverse disciplinary backgrounds. However, tailoring models to individual users typically requires substantial annotation efforts and computational resources due to user-specific finetuning. To address this, we present a systematic study of personalized jargon detection, focusing on methods that are both efficient and scalable for real-world deployment. We explore two personalization strategies: (1) lightweight fine-tuning using Low-Rank Adaptation (LoRA) on open-source models, and (2) personalized prompting, which tailors model behavior at inference time without retaining. To reflect realistic constraints, we also investigate hybrid approaches that combine limited annotated data with unsupervised user background signals. Our personalized LoRA model outperforms GPT-4 by 21.4% in F1 score and exceeds the best performing oracle baseline by 8.3%. Remarkably, our method achieves comparable performance using only 10% of the annotated training data, demonstrating its practicality for resource-constrained settings. Our study offers the first work to systematically explore efficient, low-resource personalization of jargon detection using open-source language models, offering a practical path toward scalable, user-adaptive NLP system.
MAC-Tuning: LLM Multi-Compositional Problem Reasoning with Enhanced Knowledge Boundary Awareness
Apr 30, 2025With the widespread application of large language models (LLMs), the issue of generating non-existing facts, known as hallucination, has garnered increasing attention. Previous research in enhancing LLM confidence estimation mainly focuses on the single problem setting. However, LLM awareness of its internal parameterized knowledge boundary under the more challenging multi-problem setting, which requires answering multiple problems accurately simultaneously, remains underexplored. To bridge this gap, we introduce a novel method, Multiple Answers and Confidence Stepwise Tuning (MAC-Tuning), that separates the learning of answer prediction and confidence estimation during fine-tuning on instruction data. Extensive experiments demonstrate that our method outperforms baselines by up to 25% in average precision.