 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Dynamic Scenes in Ego Centric 4D Point Clouds
Aug 12, 2025Understanding dynamic 4D scenes from an egocentric perspective-modeling changes in 3D spatial structure over time-is crucial for human-machine interaction, autonomous navigation, and embodied intelligence. While existing egocentric datasets contain dynamic scenes, they lack unified 4D annotations and task-driven evaluation protocols for fine-grained spatio-temporal reasoning, especially on motion of objects and human, together with their interactions. To address this gap, we introduce EgoDynamic4D, a novel QA benchmark on highly dynamic scenes, comprising RGB-D video, camera poses, globally unique instance masks, and 4D bounding boxes. We construct 927K QA pairs accompanied by explicit Chain-of-Thought (CoT), enabling verifiable, step-by-step spatio-temporal reasoning. We design 12 dynamic QA tasks covering agent motion, human-object interaction, trajectory prediction, relation understanding, and temporal-causal reasoning, with fine-grained, multidimensional metrics. To tackle these tasks, we propose an end-to-end spatio-temporal reasoning framework that unifies dynamic and static scene information, using instance-aware feature encoding, time and camera encoding, and spatially adaptive down-sampling to compress large 4D scenes into token sequences manageable by LLMs. Experiments on EgoDynamic4D show that our method consistently outperforms baselines, validating the effectiveness of multimodal temporal modeling for egocentric dynamic scene understanding.
MAC-Tuning: LLM Multi-Compositional Problem Reasoning with Enhanced Knowledge Boundary Awareness
Apr 30, 2025With the widespread application of large language models (LLMs), the issue of generating non-existing facts, known as hallucination, has garnered increasing attention. Previous research in enhancing LLM confidence estimation mainly focuses on the single problem setting. However, LLM awareness of its internal parameterized knowledge boundary under the more challenging multi-problem setting, which requires answering multiple problems accurately simultaneously, remains underexplored. To bridge this gap, we introduce a novel method, Multiple Answers and Confidence Stepwise Tuning (MAC-Tuning), that separates the learning of answer prediction and confidence estimation during fine-tuning on instruction data. Extensive experiments demonstrate that our method outperforms baselines by up to 25% in average precision.
Stochastic Monkeys at Play: Random Augmentations Cheaply Break LLM Safety Alignment
Nov 05, 2024Safety alignment of Large Language Models (LLMs) has recently become a critical objective of model developers. In response, a growing body of work has been investigating how safety alignment can be bypassed through various jailbreaking methods, such as adversarial attacks. However, these jailbreak methods can be rather costly or involve a non-trivial amount of creativity and effort, introducing the assumption that malicious users are high-resource or sophisticated. In this paper, we study how simple random augmentations to the input prompt affect safety alignment effectiveness in state-of-the-art LLMs, such as Llama 3 and Qwen 2. We perform an in-depth evaluation of 17 different models and investigate the intersection of safety under random augmentations with multiple dimensions: augmentation type, model size, quantization, fine-tuning-based defenses, and decoding strategies (e.g., sampling temperature). We show that low-resource and unsophisticated attackers, i.e. $\textit{stochastic monkeys}$, can significantly improve their chances of bypassing alignment with just 25 random augmentations per prompt.
Few-Shot Joint Multimodal Entity-Relation Extraction via Knowledge-Enhanced Cross-modal Prompt Model
Oct 18, 2024


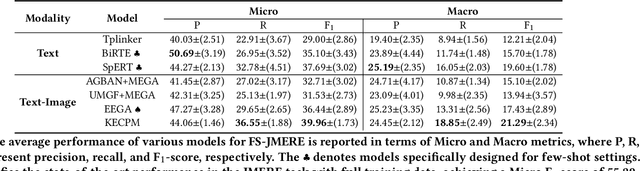
Joint Multimodal Entity-Relation Extraction (JMERE) is a challenging task that aims to extract entities and their relations from text-image pairs in social media posts. Existing methods for JMERE require large amounts of labeled data. However, gathering and annotating fine-grained multimodal data for JMERE poses significant challenges. Initially, we construct diverse and comprehensive multimodal few-shot datasets fitted to the original data distribution. To address the insufficient information in the few-shot setting, we introduce the \textbf{K}nowledge-\textbf{E}nhanced \textbf{C}ross-modal \textbf{P}rompt \textbf{M}odel (KECPM) for JMERE. This method can effectively address the problem of insufficient information in the few-shot setting by guiding a large language model to generate supplementary background knowledge. Our proposed method comprises two stages: (1) a knowledge ingestion stage that dynamically formulates prompts based on semantic similarity guide ChatGPT generating relevant knowledge and employs self-reflection to refine the knowledge; (2) a knowledge-enhanced language model stage that merges the auxiliary knowledge with the original input and utilizes a transformer-based model to align with JMERE's required output format. We extensively evaluate our approach on a few-shot dataset derived from the JMERE dataset, demonstrating its superiority over strong baselines in terms of both micro and macro F$_1$ scores. Additionally, we present qualitative analyses and case studies to elucidate the effectiveness of our model.
CityCraft: A Real Crafter for 3D City Generation
Jun 07, 2024



City scene generation has gained significant attention in autonomous driving, smart city development, and traffic simulation. It helps enhance infrastructure planning and monitoring solutions. Existing methods have employed a two-stage process involving city layout generation, typically using Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), or Transformers, followed by neural rendering. These techniques often exhibit limited diversity and noticeable artifacts in the rendered city scenes. The rendered scenes lack variety, resembling the training images, resulting in monotonous styles. Additionally, these methods lack planning capabilities, leading to less realistic generated scenes. In this paper, we introduce CityCraft, an innovative framework designed to enhance both the diversity and quality of urban scene generation. Our approach integrates three key stages: initially, a diffusion transformer (DiT) model is deployed to generate diverse and controllable 2D city layouts. Subsequently, a Large Language Model(LLM) is utilized to strategically make land-use plans within these layouts based on user prompts and language guidelines. Based on the generated layout and city plan, we utilize the asset retrieval module and Blender for precise asset placement and scene construction. Furthermore, we contribute two new datasets to the field: 1)CityCraft-OSM dataset including 2D semantic layouts of urban areas, corresponding satellite images, and detailed annotations. 2) CityCraft-Buildings dataset, featuring thousands of diverse, high-quality 3D building assets. CityCraft achieves state-of-the-art performance in generating realistic 3D cities.