 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManiSplat: Manipulation Trajectory Synthesis from Monocular Video via Decoupled 3D Gaussian Splatting
Jun 09, 2026Reconstructing dynamic and interactive 3D scenes from real-world observations remains a fundamental challenge in computer vision and robotics. While recent advances in 3D Gaussian Splatting have enabled high-fidelity static reconstruction, extending it to interactive environments with articulated robots and manipulable objects remains difficult due to complex contact interactions and abrupt pose changes. To address these challenges, we introduce ManiSplat, a unified framework that reconstructs controllable and decoupled Gaussian digital twins directly from monocular ego-view robotic videos. Our method introduces a Graph-Structured Disentangled Representation that separates the robot, objects, and background into independently optimizable Gaussian subfields organized within a scene graph. To ensure stability, we propose a Task-Oriented Spatio-Temporal Alignment module that leverages the inherent logic of manipulation tasks-alternating between Motion and Skill phases-to construct accurate pseudo-ground-truth trajectories. Finally, a joint photometric-geometric optimization ensures the reconstructed scenes are temporally coherent, physically consistent, and simulation-ready. Extensive experiments demonstrate that our approach reconstructs interaction-driven dynamic scenes with high fidelity and controllability, effectively supporting downstream robotic tasks and policy learning.
Sell More, Play Less: Benchmarking LLM Realistic Selling Skill
Apr 09, 2026Sales dialogues require multi-turn, goal-directed persuasion under asymmetric incentives, which makes them a challenging setting for large language models (LLMs). Yet existing dialogue benchmarks rarely measure deal progression and outcomes. We introduce SalesLLM benchmark, a bilingual (ZH/EN) benchmark derived from realistic applications covering Financial Services and Consumer Goods, built from 30,074 scripted configurations and 1,805 curated multi-turn scenarios with controllable difficulty and personas. We propose a fully automatic evaluation pipeline that combines (i) an LLM-based rater for sales-process progress,and (ii) fine-tuned BERT classifiers for end-of-dialogue buying intent. To improve simulation fidelity, we train a user model, CustomerLM, with SFT and DPO on 8,000+ crowdworker-involved sales conversations, reducing role inversion from 17.44% (GPT-4o) to 8.8%. SalesLLM benchmark scores correlate strongly with expert human ratings (Pearson r=0.98). Experiments across 15 mainstream LLMs reveal substantial variability: top-performance LLMs are competitive with human-level performance while the less capable ones are worse than human. SalesLLM benchmark serves as a scalable benchmark for developing and evaluating outcome-oriented sales agents.
MeMix: Writing Less, Remembering More for Streaming 3D Reconstruction
Mar 16, 2026Reconstruction is a fundamental task in 3D vision and a fundamental capability for spatial intelligence. Particularly, streaming 3D reconstruction is central to real-time spatial perception, yet existing recurrent online models often suffer from progressive degradation on long sequences due to state drift and forgetting, motivating inference-time remedies. We present MeMix, a training-free, plug-and-play module that improves streaming reconstruction by recasting the recurrent state into a Memory Mixture. MeMix partitions the state into multiple independent memory patches and updates only the least-aligned memory patches while exactly preserving others. This selective update mitigates catastrophic forgetting while retaining $O(1)$ inference memory, and requires no fine-tuning or additional learnable parameters, making it directly applicable to existing recurrent reconstruction models. Across standard benchmarks (ScanNet, 7-Scenes, KITTI, etc.), under identical backbones and inference settings, MeMix reduces reconstruction completeness error by 15.3% on average (up to 40.0%) across 300--500 frame streams on 7-Scenes. The code is available at https://dongjiacheng06.github.io/MeMix/
Hand3R: Online 4D Hand-Scene Reconstruction in the Wild
Feb 03, 2026For Embodied AI, jointly reconstructing dynamic hands and the dense scene context is crucial for understanding physical interaction. However, most existing methods recover isolated hands in local coordinates, overlooking the surrounding 3D environment. To address this, we present Hand3R, the first online framework for joint 4D hand-scene reconstruction from monocular video. Hand3R synergizes a pre-trained hand expert with a 4D scene foundation model via a scene-aware visual prompting mechanism. By injecting high-fidelity hand priors into a persistent scene memory, our approach enables simultaneous reconstruction of accurate hand meshes and dense metric-scale scene geometry in a single forward pass. Experiments demonstrate that Hand3R bypasses the reliance on offline optimization and delivers competitive performance in both local hand reconstruction and global positioning.
GO-MLVTON: Garment Occlusion-Aware Multi-Layer Virtual Try-On with Diffusion Models
Jan 20, 2026Existing Image-based virtual try-on (VTON) methods primarily focus on single-layer or multi-garment VTON, neglecting multi-layer VTON (ML-VTON), which involves dressing multiple layers of garments onto the human body with realistic deformation and layering to generate visually plausible outcomes. The main challenge lies in accurately modeling occlusion relationships between inner and outer garments to reduce interference from redundant inner garment features. To address this, we propose GO-MLVTON, the first multi-layer VTON method, introducing the Garment Occlusion Learning module to learn occlusion relationships and the StableDiffusion-based Garment Morphing & Fitting module to deform and fit garments onto the human body, producing high-quality multi-layer try-on results. Additionally, we present the MLG dataset for this task and propose a new metric named Layered Appearance Coherence Difference (LACD) for evaluation. Extensive experiments demonstrate the state-of-the-art performance of GO-MLVTON. Project page: https://upyuyang.github.io/go-mlvton/.
Flexible-Duplex Cell-Free Architecture for Secure Uplink Communications in Low-Altitude Wireless Networks
Jan 07, 2026Low-altitude wireless networks (LAWNs) are expected to play a central role in future 6G infrastructures, yet uplink transmissions of uncrewed aerial vehicles (UAVs) remain vulnerable to eavesdropping due to their limited transmit power, constrained antenna resources, and highly exposed air-ground propagation conditions. To address this fundamental bottleneck, we propose a flexible-duplex cell-free (CF) architecture in which each distributed access point (AP) can dynamically operate either as a receive AP for UAV uplink collection or as a transmit AP that generates cooperative artificial noise (AN) for secrecy enhancement. Such AP-level duplex flexibility introduces an additional spatial degree of freedom that enables distributed and adaptive protection against wiretapping in LAWNs. Building upon this architecture, we formulate a max-min secrecy-rate problem that jointly optimizes AP mode selection, receive combining, and AN covariance design. This tightly coupled and nonconvex optimization is tackled by first deriving the optimal receive combiners in closed form, followed by developing a penalty dual decomposition (PDD) algorithm with guaranteed convergence to a stationary solution. To further reduce computational burden, we propose a low-complexity sequential scheme that determines AP modes via a heuristic metric and then updates the AN covariance matrices through closed-form iterations embedded in the PDD framework. Simulation results show that the proposed flexible-duplex architecture yields substantial secrecy-rate gains over CF systems with fixed AP roles. The joint optimization method attains the highest secrecy performance, while the low-complexity approach achieves over 90% of the optimal performance with an order-of-magnitude lower computational complexity, offering a practical solution for secure uplink communications in LAWNs.
RecurGS: Interactive Scene Modeling via Discrete-State Recurrent Gaussian Fusion
Dec 20, 2025Recent advances in 3D scene representations have enabled high-fidelity novel view synthesis, yet adapting to discrete scene changes and constructing interactive 3D environments remain open challenges in vision and robotics. Existing approaches focus solely on updating a single scene without supporting novel-state synthesis. Others rely on diffusion-based object-background decoupling that works on one state at a time and cannot fuse information across multiple observations. To address these limitations, we introduce RecurGS, a recurrent fusion framework that incrementally integrates discrete Gaussian scene states into a single evolving representation capable of interaction. RecurGS detects object-level changes across consecutive states, aligns their geometric motion using semantic correspondence and Lie-algebra based SE(3) refinement, and performs recurrent updates that preserve historical structures through replay supervision. A voxelized, visibility-aware fusion module selectively incorporates newly observed regions while keeping stable areas fixed, mitigating catastrophic forgetting and enabling efficient long-horizon updates. RecurGS supports object-level manipulation, synthesizes novel scene states without requiring additional scans, and maintains photorealistic fidelity across evolving environments. Extensive experiments across synthetic and real-world datasets demonstrate that our framework delivers high-quality reconstructions with substantially improved update efficiency, providing a scalable step toward continuously interactive Gaussian worlds.
IGFuse: Interactive 3D Gaussian Scene Reconstruction via Multi-Scans Fusion
Aug 18, 2025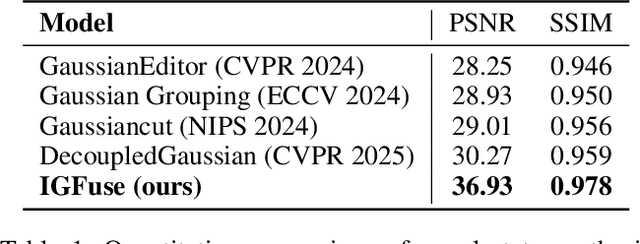



Reconstructing complete and interactive 3D scenes remains a fundamental challenge in computer vision and robotics, particularly due to persistent object occlusions and limited sensor coverage. Multiview observations from a single scene scan often fail to capture the full structural details. Existing approaches typically rely on multi stage pipelines, such as segmentation, background completion, and inpainting or require per-object dense scanning, both of which are error-prone, and not easily scalable. We propose IGFuse, a novel framework that reconstructs interactive Gaussian scene by fusing observations from multiple scans, where natural object rearrangement between captures reveal previously occluded regions. Our method constructs segmentation aware Gaussian fields and enforces bi-directional photometric and semantic consistency across scans. To handle spatial misalignments, we introduce a pseudo-intermediate scene state for unified alignment, alongside collaborative co-pruning strategies to refine geometry. IGFuse enables high fidelity rendering and object level scene manipulation without dense observations or complex pipelines. Extensive experiments validate the framework's strong generalization to novel scene configurations, demonstrating its effectiveness for real world 3D reconstruction and real-to-simulation transfer. Our project page is available online.
Energy-Efficient Hybrid Beamfocusing for Near-Field Integrated Sensing and Communication
Aug 06, 2025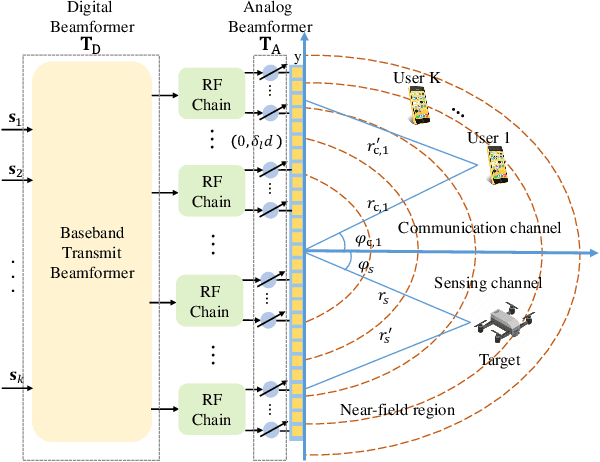
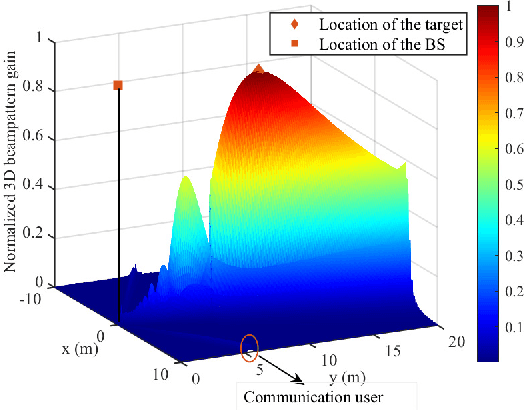
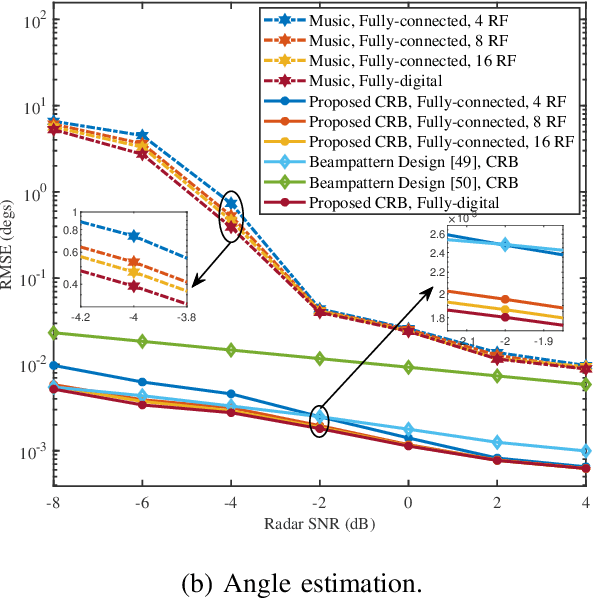
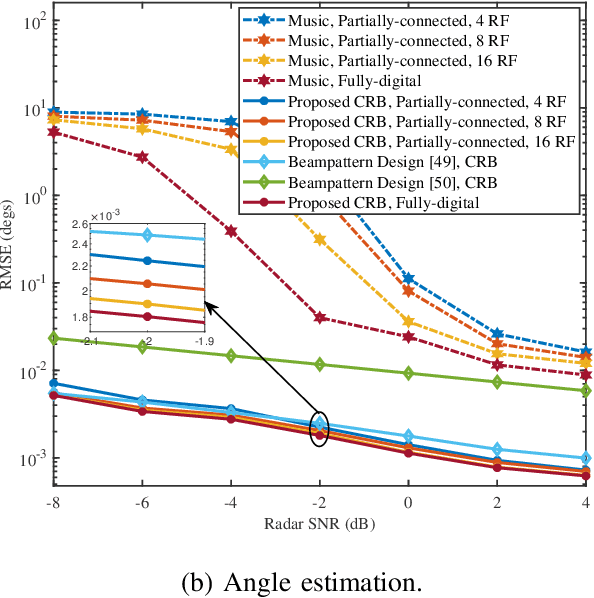
Integrated sensing and communication (ISAC) is a pivotal component of sixth-generation (6G) wireless networks, leveraging high-frequency bands and massive multiple-input multiple-output (M-MIMO) to deliver both high-capacity communication and high-precision sensing. However, these technological advancements lead to significant near-field effects, while the implementation of M-MIMO \mbox{is associated with considerable} hardware costs and escalated power consumption. In this context, hybrid architecture designs emerge as both hardware-efficient and energy-efficient solutions. Motivated by these considerations, we investigate the design of energy-efficient hybrid beamfocusing for near-field ISAC under two distinct target scenarios, i.e., a point target and an extended target. Specifically, we first derive the closed-form Cram\'{e}r-Rao bound (CRB) of joint angle-and-distance estimation for the point target and the Bayesian CRB (BCRB) of the target response matrix for the extended target. Building on these derived results, we minimize the CRB/BCRB by optimizing the transmit beamfocusing, while ensuring the energy efficiency (EE) of the system and the quality-of-service (QoS) for communication users. To address the resulting \mbox{nonconvex problems}, we first utilize a penalty-based successive convex approximation technique with a fully-digital beamformer to obtain a suboptimal solution. Then, we propose an efficient alternating \mbox{optimization} algorithm to design the analog-and-digital beamformer. \mbox{Simulation} results indicate that joint distance-and-angle estimation is feasible in the near-field region. However, the adopted hybrid architectures inevitably degrade the accuracy of distance estimation, compared with their fully-digital counterparts. Furthermore, enhancements in system EE would compromise the accuracy of target estimation, unveiling a nontrivial tradeoff.
DSG-World: Learning a 3D Gaussian World Model from Dual State Videos
Jun 05, 2025Building an efficient and physically consistent world model from limited observations is a long standing challenge in vision and robotics. Many existing world modeling pipelines are based on implicit generative models, which are hard to train and often lack 3D or physical consistency. On the other hand, explicit 3D methods built from a single state often require multi-stage processing-such as segmentation, background completion, and inpainting-due to occlusions. To address this, we leverage two perturbed observations of the same scene under different object configurations. These dual states offer complementary visibility, alleviating occlusion issues during state transitions and enabling more stable and complete reconstruction. In this paper, we present DSG-World, a novel end-to-end framework that explicitly constructs a 3D Gaussian World model from Dual State observations. Our approach builds dual segmentation-aware Gaussian fields and enforces bidirectional photometric and semantic consistency. We further introduce a pseudo intermediate state for symmetric alignment and design collaborative co-pruning trategies to refine geometric completeness. DSG-World enables efficient real-to-simulation transfer purely in the explicit Gaussian representation space, supporting high-fidelity rendering and object-level scene manipulation without relying on dense observations or multi-stage pipelines. Extensive experiments demonstrate strong generalization to novel views and scene states, highlighting the effectiveness of our approach for real-world 3D reconstruction and simulation.