 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisRefiner: Learning from Visual Differences for Screenshot-to-Code Generation
Feb 05, 2026Screenshot-to-code generation aims to translate user interface screenshots into executable frontend code that faithfully reproduces the target layout and style. Existing multimodal large language models perform this mapping directly from screenshots but are trained without observing the visual outcomes of their generated code. In contrast, human developers iteratively render their implementation, compare it with the design, and learn how visual differences relate to code changes. Inspired by this process, we propose VisRefiner, a training framework that enables models to learn from visual differences between rendered predictions and reference designs. We construct difference-aligned supervision that associates visual discrepancies with corresponding code edits, allowing the model to understand how appearance variations arise from implementation changes. Building on this, we introduce a reinforcement learning stage for self-refinement, where the model improves its generated code by observing both the rendered output and the target design, identifying their visual differences, and updating the code accordingly. Experiments show that VisRefiner substantially improves single-step generation quality and layout fidelity, while also endowing models with strong self-refinement ability. These results demonstrate the effectiveness of learning from visual differences for advancing screenshot-to-code generation.
Beyond Rejection Sampling: Trajectory Fusion for Scaling Mathematical Reasoning
Feb 04, 2026Large language models (LLMs) have made impressive strides in mathematical reasoning, often fine-tuned using rejection sampling that retains only correct reasoning trajectories. While effective, this paradigm treats supervision as a binary filter that systematically excludes teacher-generated errors, leaving a gap in how reasoning failures are modeled during training. In this paper, we propose TrajFusion, a fine-tuning strategy that reframes rejection sampling as a structured supervision construction process. Specifically, TrajFusion forms fused trajectories that explicitly model trial-and-error reasoning by interleaving selected incorrect trajectories with reflection prompts and correct trajectories. The length of each fused sample is adaptively controlled based on the frequency and diversity of teacher errors, providing richer supervision for challenging problems while safely reducing to vanilla rejection sampling fine-tuning (RFT) when error signals are uninformative. TrajFusion requires no changes to the architecture or training objective. Extensive experiments across multiple math benchmarks demonstrate that TrajFusion consistently outperforms RFT, particularly on challenging and long-form reasoning problems.
ConPress: Learning Efficient Reasoning from Multi-Question Contextual Pressure
Feb 01, 2026Large reasoning models (LRMs) typically solve reasoning-intensive tasks by generating long chain-of-thought (CoT) traces, leading to substantial inference overhead. We identify a reproducible inference-time phenomenon, termed Self-Compression: when multiple independent and answerable questions are presented within a single prompt, the model spontaneously produces shorter reasoning traces for each question. This phenomenon arises from multi-question contextual pressure during generation and consistently manifests across models and benchmarks. Building on this observation, we propose ConPress (Learning from Contextual Pressure), a lightweight self-supervised fine-tuning approach. ConPress constructs multi-question prompts to induce self-compression, samples the resulting model outputs, and parses and filters per-question traces to obtain concise yet correct reasoning trajectories. These trajectories are directly used for supervised fine-tuning, internalizing compressed reasoning behavior in single-question settings without external teachers, manual pruning, or reinforcement learning. With only 8k fine-tuning examples, ConPress reduces reasoning token usage by 59% on MATH500 and 33% on AIME25, while maintaining competitive accuracy.
Hybrid Spiking Vision Transformer for Object Detection with Event Cameras
May 12, 2025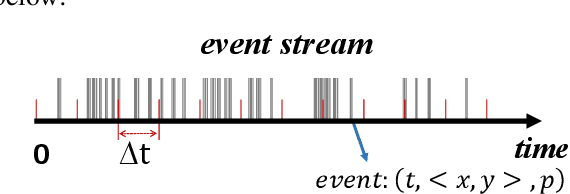
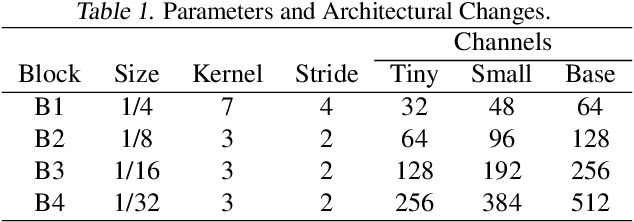

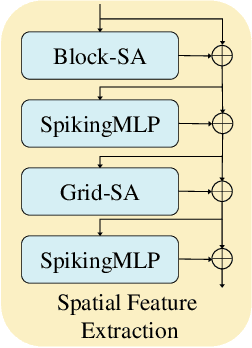
Event-based object detection has gained increasing attention due to its advantages such as high temporal resolution, wide dynamic range, and asynchronous address-event representation. Leveraging these advantages, Spiking Neural Networks (SNNs) have emerged as a promising approach, offering low energy consumption and rich spatiotemporal dynamics. To further enhance the performance of event-based object detection, this study proposes a novel hybrid spike vision Transformer (HsVT) model. The HsVT model integrates a spatial feature extraction module to capture local and global features, and a temporal feature extraction module to model time dependencies and long-term patterns in event sequences. This combination enables HsVT to capture spatiotemporal features, improving its capability to handle complex event-based object detection tasks. To support research in this area, we developed and publicly released The Fall Detection Dataset as a benchmark for event-based object detection tasks. This dataset, captured using an event-based camera, ensures facial privacy protection and reduces memory usage due to the event representation format. We evaluated the HsVT model on GEN1 and Fall Detection datasets across various model sizes. Experimental results demonstrate that HsVT achieves significant performance improvements in event detection with fewer parameters.
Joint Super-Resolution and Segmentation for 1-m Impervious Surface Area Mapping in China's Yangtze River Economic Belt
May 08, 2025We propose a novel joint framework by integrating super-resolution and segmentation, called JointSeg, which enables the generation of 1-meter ISA maps directly from freely available Sentinel-2 imagery. JointSeg was trained on multimodal cross-resolution inputs, offering a scalable and affordable alternative to traditional approaches. This synergistic design enables gradual resolution enhancement from 10m to 1m while preserving fine-grained spatial textures, and ensures high classification fidelity through effective cross-scale feature fusion. This method has been successfully applied to the Yangtze River Economic Belt (YREB), a region characterized by complex urban-rural patterns and diverse topography. As a result, a comprehensive ISA mapping product for 2021, referred to as ISA-1, was generated, covering an area of over 2.2 million square kilometers. Quantitative comparisons against the 10m ESA WorldCover and other benchmark products reveal that ISA-1 achieves an F1-score of 85.71%, outperforming bilinear-interpolation-based segmentation by 9.5%, and surpassing other ISA datasets by 21.43%-61.07%. In densely urbanized areas (e.g., Suzhou, Nanjing), ISA-1 reduces ISA overestimation through improved discrimination of green spaces and water bodies. Conversely, in mountainous regions (e.g., Ganzi, Zhaotong), it identifies significantly more ISA due to its enhanced ability to detect fragmented anthropogenic features such as rural roads and sparse settlements, demonstrating its robustness across diverse landscapes. Moreover, we present biennial ISA maps from 2017 to 2023, capturing spatiotemporal urbanization dynamics across representative cities. The results highlight distinct regional growth patterns: rapid expansion in upstream cities, moderate growth in midstream regions, and saturation in downstream metropolitan areas.
Direct Sparse Odometry with Continuous 3D Gaussian Maps for Indoor Environments
Mar 05, 2025



Accurate localization is essential for robotics and augmented reality applications such as autonomous navigation. Vision-based methods combining prior maps aim to integrate LiDAR-level accuracy with camera cost efficiency for robust pose estimation. Existing approaches, however, often depend on unreliable interpolation procedures when associating discrete point cloud maps with dense image pixels, which inevitably introduces depth errors and degrades pose estimation accuracy. We propose a monocular visual odometry framework utilizing a continuous 3D Gaussian map, which directly assigns geometrically consistent depth values to all extracted high-gradient points without interpolation. Evaluations on two public datasets demonstrate superior tracking accuracy compared to existing methods. We have released the source code of this work for the development of the community.
A Survey of Sample-Efficient Deep Learning for Change Detection in Remote Sensing: Tasks, Strategies, and Challenges
Feb 05, 2025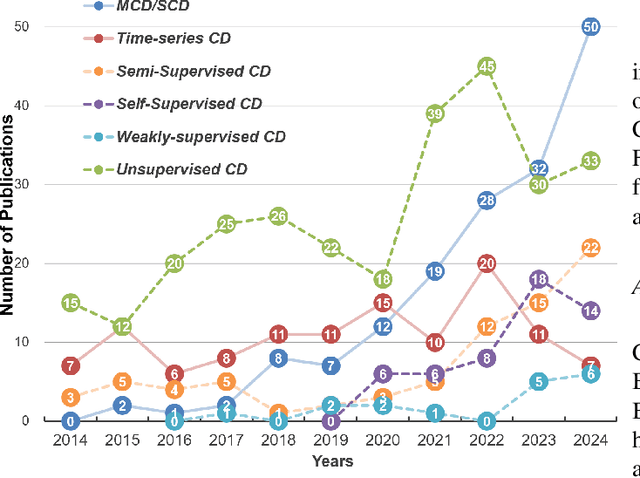
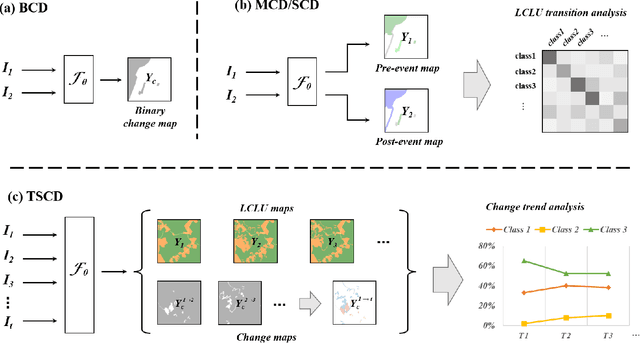
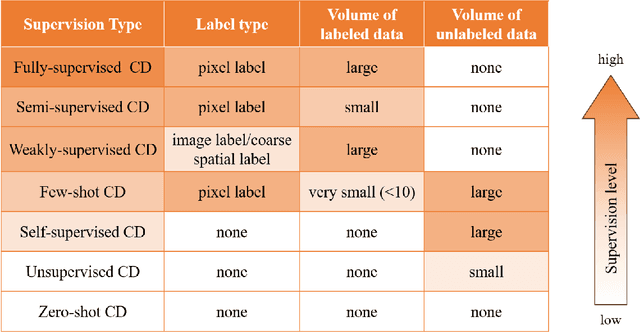
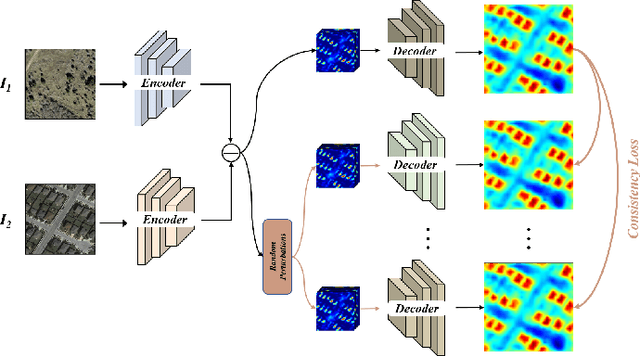
In the last decade, the rapid development of deep learning (DL) has made it possible to perform automatic, accurate, and robust Change Detection (CD) on large volumes of Remote Sensing Images (RSIs). However, despite advances in CD methods, their practical application in real-world contexts remains limited due to the diverse input data and the applicational context. For example, the collected RSIs can be time-series observations, and more informative results are required to indicate the time of change or the specific change category. Moreover, training a Deep Neural Network (DNN) requires a massive amount of training samples, whereas in many cases these samples are difficult to collect. To address these challenges, various specific CD methods have been developed considering different application scenarios and training resources. Additionally, recent advancements in image generation, self-supervision, and visual foundation models (VFMs) have opened up new approaches to address the 'data-hungry' issue of DL-based CD. The development of these methods in broader application scenarios requires further investigation and discussion. Therefore, this article summarizes the literature methods for different CD tasks and the available strategies and techniques to train and deploy DL-based CD methods in sample-limited scenarios. We expect that this survey can provide new insights and inspiration for researchers in this field to develop more effective CD methods that can be applied in a wider range of contexts.
CityCraft: A Real Crafter for 3D City Generation
Jun 07, 2024



City scene generation has gained significant attention in autonomous driving, smart city development, and traffic simulation. It helps enhance infrastructure planning and monitoring solutions. Existing methods have employed a two-stage process involving city layout generation, typically using Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), or Transformers, followed by neural rendering. These techniques often exhibit limited diversity and noticeable artifacts in the rendered city scenes. The rendered scenes lack variety, resembling the training images, resulting in monotonous styles. Additionally, these methods lack planning capabilities, leading to less realistic generated scenes. In this paper, we introduce CityCraft, an innovative framework designed to enhance both the diversity and quality of urban scene generation. Our approach integrates three key stages: initially, a diffusion transformer (DiT) model is deployed to generate diverse and controllable 2D city layouts. Subsequently, a Large Language Model(LLM) is utilized to strategically make land-use plans within these layouts based on user prompts and language guidelines. Based on the generated layout and city plan, we utilize the asset retrieval module and Blender for precise asset placement and scene construction. Furthermore, we contribute two new datasets to the field: 1)CityCraft-OSM dataset including 2D semantic layouts of urban areas, corresponding satellite images, and detailed annotations. 2) CityCraft-Buildings dataset, featuring thousands of diverse, high-quality 3D building assets. CityCraft achieves state-of-the-art performance in generating realistic 3D cities.
Medical Visual Prompting (MVP): A Unified Framework for Versatile and High-Quality Medical Image Segmentation
Apr 01, 2024



Accurate segmentation of lesion regions is crucial for clinical diagnosis and treatment across various diseases. While deep convolutional networks have achieved satisfactory results in medical image segmentation, they face challenges such as loss of lesion shape information due to continuous convolution and downsampling, as well as the high cost of manually labeling lesions with varying shapes and sizes. To address these issues, we propose a novel medical visual prompting (MVP) framework that leverages pre-training and prompting concepts from natural language processing (NLP). The framework utilizes three key components: Super-Pixel Guided Prompting (SPGP) for superpixelating the input image, Image Embedding Guided Prompting (IEGP) for freezing patch embedding and merging with superpixels to provide visual prompts, and Adaptive Attention Mechanism Guided Prompting (AAGP) for pinpointing prompt content and efficiently adapting all layers. By integrating SPGP, IEGP, and AAGP, the MVP enables the segmentation network to better learn shape prompting information and facilitates mutual learning across different tasks. Extensive experiments conducted on five datasets demonstrate superior performance of this method in various challenging medical image tasks, while simplifying single-task medical segmentation models. This novel framework offers improved performance with fewer parameters and holds significant potential for accurate segmentation of lesion regions in various medical tasks, making it clinically valuable.
VersaT2I: Improving Text-to-Image Models with Versatile Reward
Mar 27, 2024Recent text-to-image (T2I) models have benefited from large-scale and high-quality data, demonstrating impressive performance. However, these T2I models still struggle to produce images that are aesthetically pleasing, geometrically accurate, faithful to text, and of good low-level quality. We present VersaT2I, a versatile training framework that can boost the performance with multiple rewards of any T2I model. We decompose the quality of the image into several aspects such as aesthetics, text-image alignment, geometry, low-level quality, etc. Then, for every quality aspect, we select high-quality images in this aspect generated by the model as the training set to finetune the T2I model using the Low-Rank Adaptation (LoRA). Furthermore, we introduce a gating function to combine multiple quality aspects, which can avoid conflicts between different quality aspects. Our method is easy to extend and does not require any manual annotation, reinforcement learning, or model architecture changes. Extensive experiments demonstrate that VersaT2I outperforms the baseline methods across various quality criteria.