 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Medical Reasoning Verification via Tool-Integrated Reinforcement Learning
Jan 28, 2026Large language models have achieved strong performance on medical reasoning benchmarks, yet their deployment in clinical settings demands rigorous verification to ensure factual accuracy. While reward models offer a scalable approach for reasoning trace verification, existing methods face two limitations: they produce only scalar reward values without explicit justification, and they rely on single-pass retrieval that precludes adaptive knowledge access as verification unfolds. We introduce $\method$, an agentic framework that addresses these limitations by training medical reasoning verifiers to iteratively query external medical corpora during evaluation. Our approach combines tool-augmented verification with an iterative reinforcement learning paradigm that requires only trace-level supervision, alongside an adaptive curriculum mechanism that dynamically adjusts training data distribution. Across four medical reasoning benchmarks, $\method$ achieves substantial gains over existing methods, improving MedQA accuracy by 23.5% and MedXpertQA by 32.0% relative to the base generator in particular. Crucially, $\method$ demonstrates an $\mathbf{8\times}$ reduction in sampling budget requirement compared to prior reward model baselines. These findings establish that grounding verification in dynamically retrieved evidence offers a principled path toward more reliable medical reasoning systems.
MedRAGChecker: Claim-Level Verification for Biomedical Retrieval-Augmented Generation
Jan 10, 2026Biomedical retrieval-augmented generation (RAG) can ground LLM answers in medical literature, yet long-form outputs often contain isolated unsupported or contradictory claims with safety implications. We introduce MedRAGChecker, a claim-level verification and diagnostic framework for biomedical RAG. Given a question, retrieved evidence, and a generated answer, MedRAGChecker decomposes the answer into atomic claims and estimates claim support by combining evidence-grounded natural language inference (NLI) with biomedical knowledge-graph (KG) consistency signals. Aggregating claim decisions yields answer-level diagnostics that help disentangle retrieval and generation failures, including faithfulness, under-evidence, contradiction, and safety-critical error rates. To enable scalable evaluation, we distill the pipeline into compact biomedical models and use an ensemble verifier with class-specific reliability weighting. Experiments on four biomedical QA benchmarks show that MedRAGChecker reliably flags unsupported and contradicted claims and reveals distinct risk profiles across generators, particularly on safety-critical biomedical relations.
KANO: Kolmogorov-Arnold Neural Operator for Image Super-Resolution
Dec 28, 2025The highly nonlinear degradation process, complex physical interactions, and various sources of uncertainty render single-image Super-resolution (SR) a particularly challenging task. Existing interpretable SR approaches, whether based on prior learning or deep unfolding optimization frameworks, typically rely on black-box deep networks to model latent variables, which leaves the degradation process largely unknown and uncontrollable. Inspired by the Kolmogorov-Arnold theorem (KAT), we for the first time propose a novel interpretable operator, termed Kolmogorov-Arnold Neural Operator (KANO), with the application to image SR. KANO provides a transparent and structured representation of the latent degradation fitting process. Specifically, we employ an additive structure composed of a finite number of B-spline functions to approximate continuous spectral curves in a piecewise fashion. By learning and optimizing the shape parameters of these spline functions within defined intervals, our KANO accurately captures key spectral characteristics, such as local linear trends and the peak-valley structures at nonlinear inflection points, thereby endowing SR results with physical interpretability. Furthermore, through theoretical modeling and experimental evaluations across natural images, aerial photographs, and satellite remote sensing data, we systematically compare multilayer perceptrons (MLPs) and Kolmogorov-Arnold networks (KANs) in handling complex sequence fitting tasks. This comparative study elucidates the respective advantages and limitations of these models in characterizing intricate degradation mechanisms, offering valuable insights for the development of interpretable SR techniques.
Any-Optical-Model: A Universal Foundation Model for Optical Remote Sensing
Dec 19, 2025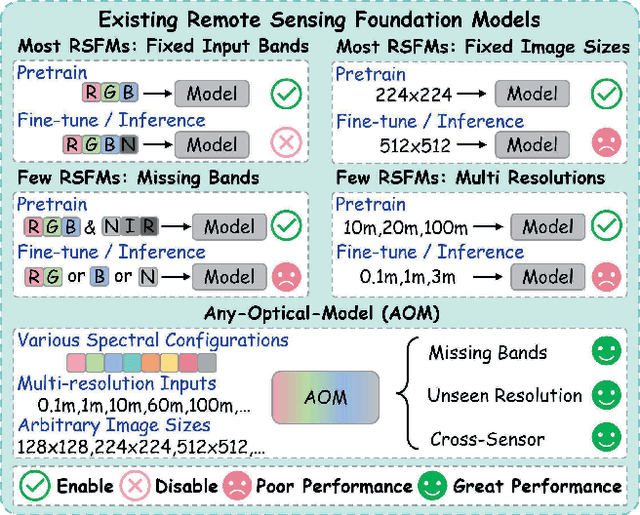
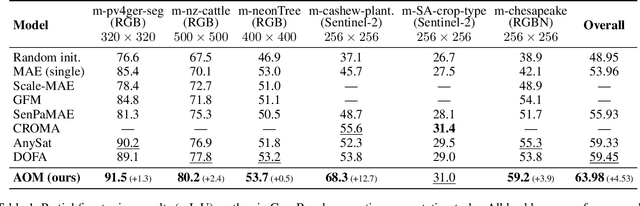
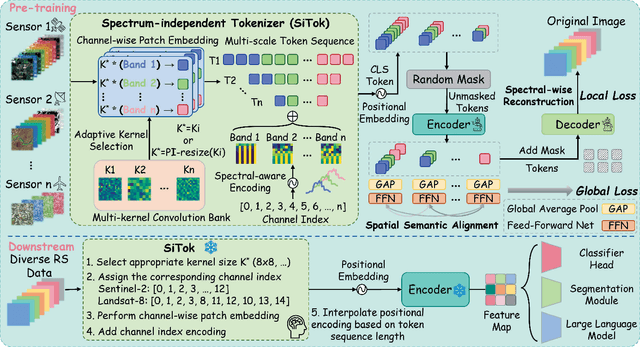
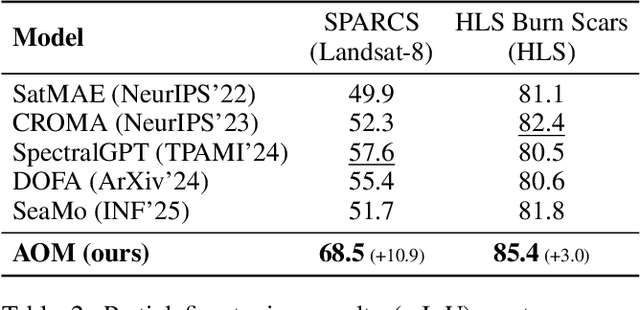
Optical satellites, with their diverse band layouts and ground sampling distances, supply indispensable evidence for tasks ranging from ecosystem surveillance to emergency response. However, significant discrepancies in band composition and spatial resolution across different optical sensors present major challenges for existing Remote Sensing Foundation Models (RSFMs). These models are typically pretrained on fixed band configurations and resolutions, making them vulnerable to real world scenarios involving missing bands, cross sensor fusion, and unseen spatial scales, thereby limiting their generalization and practical deployment. To address these limitations, we propose Any Optical Model (AOM), a universal RSFM explicitly designed to accommodate arbitrary band compositions, sensor types, and resolution scales. To preserve distinctive spectral characteristics even when bands are missing or newly introduced, AOM introduces a spectrum-independent tokenizer that assigns each channel a dedicated band embedding, enabling explicit encoding of spectral identity. To effectively capture texture and contextual patterns from sub-meter to hundred-meter imagery, we design a multi-scale adaptive patch embedding mechanism that dynamically modulates the receptive field. Furthermore, to maintain global semantic consistency across varying resolutions, AOM incorporates a multi-scale semantic alignment mechanism alongside a channel-wise self-supervised masking and reconstruction pretraining strategy that jointly models spectral-spatial relationships. Extensive experiments on over 10 public datasets, including those from Sentinel-2, Landsat, and HLS, demonstrate that AOM consistently achieves state-of-the-art (SOTA) performance under challenging conditions such as band missing, cross sensor, and cross resolution settings.
Automated Extraction of Fluoropyrimidine Treatment and Treatment-Related Toxicities from Clinical Notes Using Natural Language Processing
Oct 23, 2025



Objective: Fluoropyrimidines are widely prescribed for colorectal and breast cancers, but are associated with toxicities such as hand-foot syndrome and cardiotoxicity. Since toxicity documentation is often embedded in clinical notes, we aimed to develop and evaluate natural language processing (NLP) methods to extract treatment and toxicity information. Materials and Methods: We constructed a gold-standard dataset of 236 clinical notes from 204,165 adult oncology patients. Domain experts annotated categories related to treatment regimens and toxicities. We developed rule-based, machine learning-based (Random Forest, Support Vector Machine [SVM], Logistic Regression [LR]), deep learning-based (BERT, ClinicalBERT), and large language models (LLM)-based NLP approaches (zero-shot and error-analysis prompting). Models used an 80:20 train-test split. Results: Sufficient data existed to train and evaluate 5 annotated categories. Error-analysis prompting achieved optimal precision, recall, and F1 scores (F1=1.000) for treatment and toxicities extraction, whereas zero-shot prompting reached F1=1.000 for treatment and F1=0.876 for toxicities extraction.LR and SVM ranked second for toxicities (F1=0.937). Deep learning underperformed, with BERT (F1=0.873 treatment; F1= 0.839 toxicities) and ClinicalBERT (F1=0.873 treatment; F1 = 0.886 toxicities). Rule-based methods served as our baseline with F1 scores of 0.857 in treatment and 0.858 in toxicities. Discussion: LMM-based approaches outperformed all others, followed by machine learning methods. Machine and deep learning approaches were limited by small training data and showed limited generalizability, particularly for rare categories. Conclusion: LLM-based NLP most effectively extracted fluoropyrimidine treatment and toxicity information from clinical notes, and has strong potential to support oncology research and pharmacovigilance.
Hyperspectral Imaging
Aug 11, 2025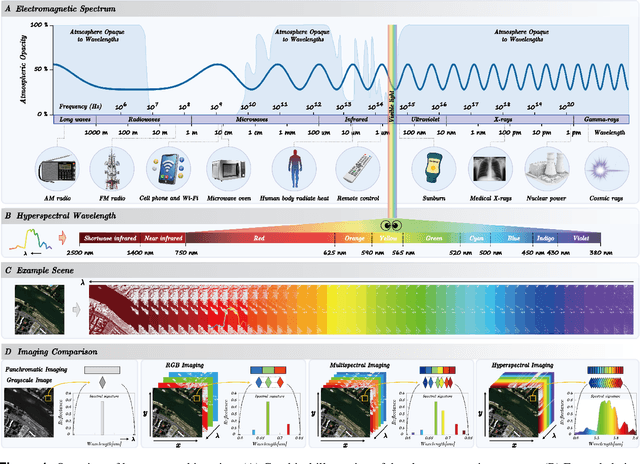
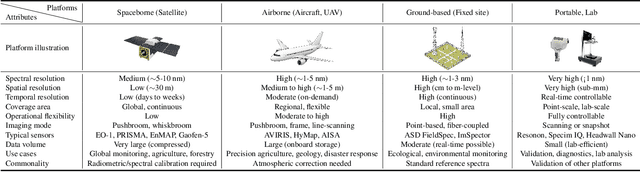
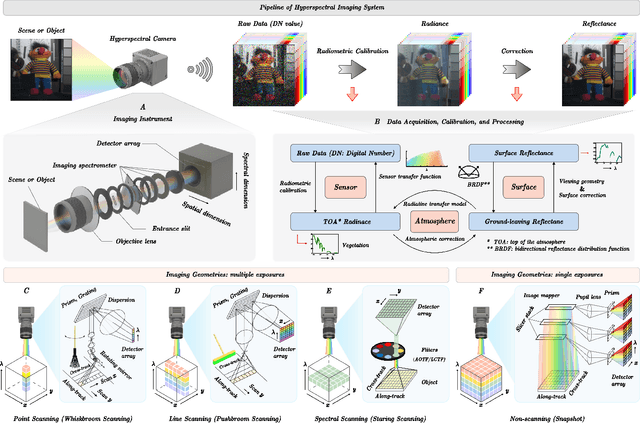

Hyperspectral imaging (HSI) is an advanced sensing modality that simultaneously captures spatial and spectral information, enabling non-invasive, label-free analysis of material, chemical, and biological properties. This Primer presents a comprehensive overview of HSI, from the underlying physical principles and sensor architectures to key steps in data acquisition, calibration, and correction. We summarize common data structures and highlight classical and modern analysis methods, including dimensionality reduction, classification, spectral unmixing, and AI-driven techniques such as deep learning. Representative applications across Earth observation, precision agriculture, biomedicine, industrial inspection, cultural heritage, and security are also discussed, emphasizing HSI's ability to uncover sub-visual features for advanced monitoring, diagnostics, and decision-making. Persistent challenges, such as hardware trade-offs, acquisition variability, and the complexity of high-dimensional data, are examined alongside emerging solutions, including computational imaging, physics-informed modeling, cross-modal fusion, and self-supervised learning. Best practices for dataset sharing, reproducibility, and metadata documentation are further highlighted to support transparency and reuse. Looking ahead, we explore future directions toward scalable, real-time, and embedded HSI systems, driven by sensor miniaturization, self-supervised learning, and foundation models. As HSI evolves into a general-purpose, cross-disciplinary platform, it holds promise for transformative applications in science, technology, and society.
A Computational Approach to Improving Fairness in K-means Clustering
May 29, 2025The popular K-means clustering algorithm potentially suffers from a major weakness for further analysis or interpretation. Some cluster may have disproportionately more (or fewer) points from one of the subpopulations in terms of some sensitive variable, e.g., gender or race. Such a fairness issue may cause bias and unexpected social consequences. This work attempts to improve the fairness of K-means clustering with a two-stage optimization formulation--clustering first and then adjust cluster membership of a small subset of selected data points. Two computationally efficient algorithms are proposed in identifying those data points that are expensive for fairness, with one focusing on nearest data points outside of a cluster and the other on highly 'mixed' data points. Experiments on benchmark datasets show substantial improvement on fairness with a minimal impact to clustering quality. The proposed algorithms can be easily extended to a broad class of clustering algorithms or fairness metrics.
Research on Defect Detection Method of Motor Control Board Based on Image Processing
May 23, 2025



The motor control board has various defects such as inconsistent color differences, incorrect plug-in positions, solder short circuits, and more. These defects directly affect the performance and stability of the motor control board, thereby having a negative impact on product quality. Therefore, studying the defect detection technology of the motor control board is an important means to improve the quality control level of the motor control board. Firstly, the processing methods of digital images about the motor control board were studied, and the noise suppression methods that affect image feature extraction were analyzed. Secondly, a specific model for defect feature extraction and color difference recognition of the tested motor control board was established, and qualified or defective products were determined based on feature thresholds. Thirdly, the search algorithm for defective images was optimized. Finally, comparative experiments were conducted on the typical motor control board, and the experimental results demonstrate that the accuracy of the motor control board defect detection model-based on image processing established in this paper reached over 99%. It is suitable for timely image processing of large quantities of motor control boards on the production line, and achieved efficient defect detection. The defect detection method can not only be used for online detection of the motor control board defects, but also provide solutions for the integrated circuit board defect processing for the industry.
Joint Super-Resolution and Segmentation for 1-m Impervious Surface Area Mapping in China's Yangtze River Economic Belt
May 08, 2025We propose a novel joint framework by integrating super-resolution and segmentation, called JointSeg, which enables the generation of 1-meter ISA maps directly from freely available Sentinel-2 imagery. JointSeg was trained on multimodal cross-resolution inputs, offering a scalable and affordable alternative to traditional approaches. This synergistic design enables gradual resolution enhancement from 10m to 1m while preserving fine-grained spatial textures, and ensures high classification fidelity through effective cross-scale feature fusion. This method has been successfully applied to the Yangtze River Economic Belt (YREB), a region characterized by complex urban-rural patterns and diverse topography. As a result, a comprehensive ISA mapping product for 2021, referred to as ISA-1, was generated, covering an area of over 2.2 million square kilometers. Quantitative comparisons against the 10m ESA WorldCover and other benchmark products reveal that ISA-1 achieves an F1-score of 85.71%, outperforming bilinear-interpolation-based segmentation by 9.5%, and surpassing other ISA datasets by 21.43%-61.07%. In densely urbanized areas (e.g., Suzhou, Nanjing), ISA-1 reduces ISA overestimation through improved discrimination of green spaces and water bodies. Conversely, in mountainous regions (e.g., Ganzi, Zhaotong), it identifies significantly more ISA due to its enhanced ability to detect fragmented anthropogenic features such as rural roads and sparse settlements, demonstrating its robustness across diverse landscapes. Moreover, we present biennial ISA maps from 2017 to 2023, capturing spatiotemporal urbanization dynamics across representative cities. The results highlight distinct regional growth patterns: rapid expansion in upstream cities, moderate growth in midstream regions, and saturation in downstream metropolitan areas.
FlexiMo: A Flexible Remote Sensing Foundation Model
Mar 31, 2025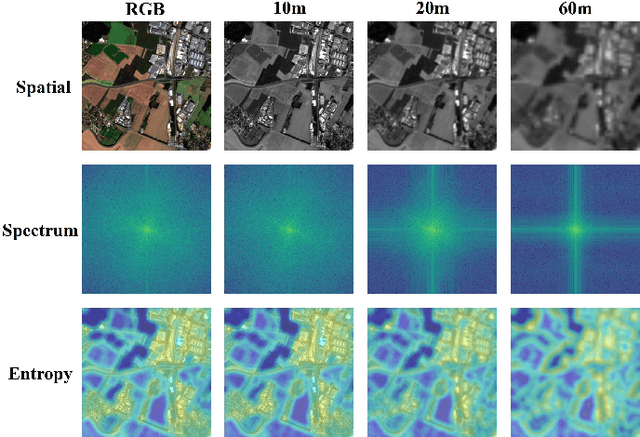
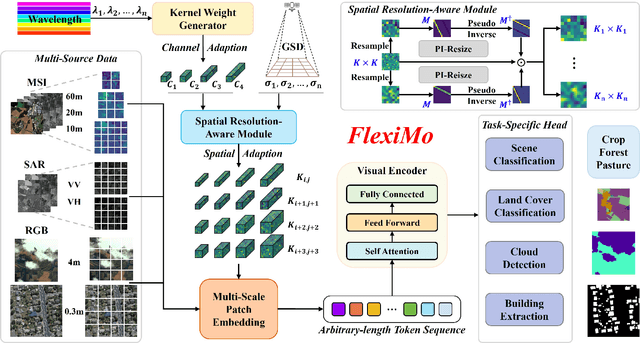
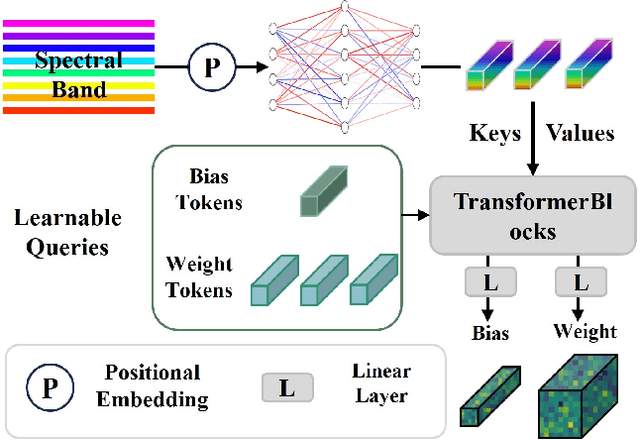

The rapid expansion of multi-source satellite imagery drives innovation in Earth observation, opening unprecedented opportunities for Remote Sensing Foundation Models to harness diverse data. However, many existing models remain constrained by fixed spatial resolutions and patch sizes, limiting their ability to fully exploit the heterogeneous spatial characteristics inherent in satellite imagery. To address these challenges, we propose FlexiMo, a flexible remote sensing foundation model that endows the pre-trained model with the flexibility to adapt to arbitrary spatial resolutions. Central to FlexiMo is a spatial resolution-aware module that employs a parameter-free alignment embedding mechanism to dynamically recalibrate patch embeddings based on the input image's resolution and dimensions. This design not only preserves critical token characteristics and ensures multi-scale feature fidelity but also enables efficient feature extraction without requiring modifications to the underlying network architecture. In addition, FlexiMo incorporates a lightweight channel adaptation module that leverages prior spectral information from sensors. This mechanism allows the model to process images with varying numbers of channels while maintaining the data's intrinsic physical properties. Extensive experiments on diverse multimodal, multi-resolution, and multi-scale datasets demonstrate that FlexiMo significantly enhances model generalization and robustness. In particular, our method achieves outstanding performance across a range of downstream tasks, including scene classification, land cover classification, urban building segmentation, and cloud detection. By enabling parameter-efficient and physically consistent adaptation, FlexiMo paves the way for more adaptable and effective foundation models in real-world remote sensing applications.