 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring MLLM-Diffusion Information Transfer with MetaCanvas
Dec 12, 2025Multimodal learning has rapidly advanced visual understanding, largely via multimodal large language models (MLLMs) that use powerful LLMs as cognitive cores. In visual generation, however, these powerful core models are typically reduced to global text encoders for diffusion models, leaving most of their reasoning and planning ability unused. This creates a gap: current multimodal LLMs can parse complex layouts, attributes, and knowledge-intensive scenes, yet struggle to generate images or videos with equally precise and structured control. We propose MetaCanvas, a lightweight framework that lets MLLMs reason and plan directly in spatial and spatiotemporal latent spaces and interface tightly with diffusion generators. We empirically implement MetaCanvas on three different diffusion backbones and evaluate it across six tasks, including text-to-image generation, text/image-to-video generation, image/video editing, and in-context video generation, each requiring precise layouts, robust attribute binding, and reasoning-intensive control. MetaCanvas consistently outperforms global-conditioning baselines, suggesting that treating MLLMs as latent-space planners is a promising direction for narrowing the gap between multimodal understanding and generation.
Think Then Embed: Generative Context Improves Multimodal Embedding
Oct 06, 2025There is a growing interest in Universal Multimodal Embeddings (UME), where models are required to generate task-specific representations. While recent studies show that Multimodal Large Language Models (MLLMs) perform well on such tasks, they treat MLLMs solely as encoders, overlooking their generative capacity. However, such an encoding paradigm becomes less effective as instructions become more complex and require compositional reasoning. Inspired by the proven effectiveness of chain-of-thought reasoning, we propose a general Think-Then-Embed (TTE) framework for UME, composed of a reasoner and an embedder. The reasoner MLLM first generates reasoning traces that explain complex queries, followed by an embedder that produces representations conditioned on both the original query and the intermediate reasoning. This explicit reasoning step enables more nuanced understanding of complex multimodal instructions. Our contributions are threefold. First, by leveraging a powerful MLLM reasoner, we achieve state-of-the-art performance on the MMEB-V2 benchmark, surpassing proprietary models trained on massive in-house datasets. Second, to reduce the dependency on large MLLM reasoners, we finetune a smaller MLLM reasoner using high-quality embedding-centric reasoning traces, achieving the best performance among open-source models with a 7% absolute gain over recently proposed models. Third, we investigate strategies for integrating the reasoner and embedder into a unified model for improved efficiency without sacrificing performance.
Pisces: An Auto-regressive Foundation Model for Image Understanding and Generation
Jun 12, 2025Recent advances in large language models (LLMs) have enabled multimodal foundation models to tackle both image understanding and generation within a unified framework. Despite these gains, unified models often underperform compared to specialized models in either task. A key challenge in developing unified models lies in the inherent differences between the visual features needed for image understanding versus generation, as well as the distinct training processes required for each modality. In this work, we introduce Pisces, an auto-regressive multimodal foundation model that addresses this challenge through a novel decoupled visual encoding architecture and tailored training techniques optimized for multimodal generation. Combined with meticulous data curation, pretraining, and finetuning, Pisces achieves competitive performance in both image understanding and image generation. We evaluate Pisces on over 20 public benchmarks for image understanding, where it demonstrates strong performance across a wide range of tasks. Additionally, on GenEval, a widely adopted benchmark for image generation, Pisces exhibits robust generative capabilities. Our extensive analysis reveals the synergistic relationship between image understanding and generation, and the benefits of using separate visual encoders, advancing the field of unified multimodal models.
Exploring the Deep Fusion of Large Language Models and Diffusion Transformers for Text-to-Image Synthesis
May 15, 2025



This paper does not describe a new method; instead, it provides a thorough exploration of an important yet understudied design space related to recent advances in text-to-image synthesis -- specifically, the deep fusion of large language models (LLMs) and diffusion transformers (DiTs) for multi-modal generation. Previous studies mainly focused on overall system performance rather than detailed comparisons with alternative methods, and key design details and training recipes were often left undisclosed. These gaps create uncertainty about the real potential of this approach. To fill these gaps, we conduct an empirical study on text-to-image generation, performing controlled comparisons with established baselines, analyzing important design choices, and providing a clear, reproducible recipe for training at scale. We hope this work offers meaningful data points and practical guidelines for future research in multi-modal generation.
BLIP3-o: A Family of Fully Open Unified Multimodal Models-Architecture, Training and Dataset
May 14, 2025Unifying image understanding and generation has gained growing attention in recent research on multimodal models. Although design choices for image understanding have been extensively studied, the optimal model architecture and training recipe for a unified framework with image generation remain underexplored. Motivated by the strong potential of autoregressive and diffusion models for high-quality generation and scalability, we conduct a comprehensive study of their use in unified multimodal settings, with emphasis on image representations, modeling objectives, and training strategies. Grounded in these investigations, we introduce a novel approach that employs a diffusion transformer to generate semantically rich CLIP image features, in contrast to conventional VAE-based representations. This design yields both higher training efficiency and improved generative quality. Furthermore, we demonstrate that a sequential pretraining strategy for unified models-first training on image understanding and subsequently on image generation-offers practical advantages by preserving image understanding capability while developing strong image generation ability. Finally, we carefully curate a high-quality instruction-tuning dataset BLIP3o-60k for image generation by prompting GPT-4o with a diverse set of captions covering various scenes, objects, human gestures, and more. Building on our innovative model design, training recipe, and datasets, we develop BLIP3-o, a suite of state-of-the-art unified multimodal models. BLIP3-o achieves superior performance across most of the popular benchmarks spanning both image understanding and generation tasks. To facilitate future research, we fully open-source our models, including code, model weights, training scripts, and pretraining and instruction tuning datasets.
Transfer between Modalities with MetaQueries
Apr 08, 2025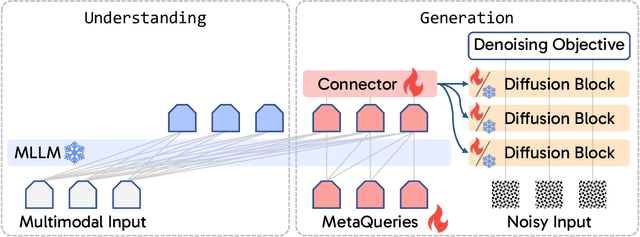


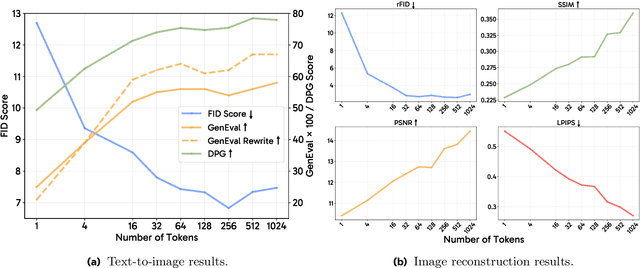
Unified multimodal models aim to integrate understanding (text output) and generation (pixel output), but aligning these different modalities within a single architecture often demands complex training recipes and careful data balancing. We introduce MetaQueries, a set of learnable queries that act as an efficient interface between autoregressive multimodal LLMs (MLLMs) and diffusion models. MetaQueries connects the MLLM's latents to the diffusion decoder, enabling knowledge-augmented image generation by leveraging the MLLM's deep understanding and reasoning capabilities. Our method simplifies training, requiring only paired image-caption data and standard diffusion objectives. Notably, this transfer is effective even when the MLLM backbone remains frozen, thereby preserving its state-of-the-art multimodal understanding capabilities while achieving strong generative performance. Additionally, our method is flexible and can be easily instruction-tuned for advanced applications such as image editing and subject-driven generation.
PISA Experiments: Exploring Physics Post-Training for Video Diffusion Models by Watching Stuff Drop
Mar 12, 2025
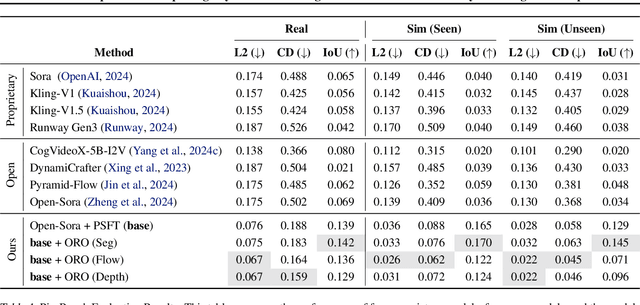
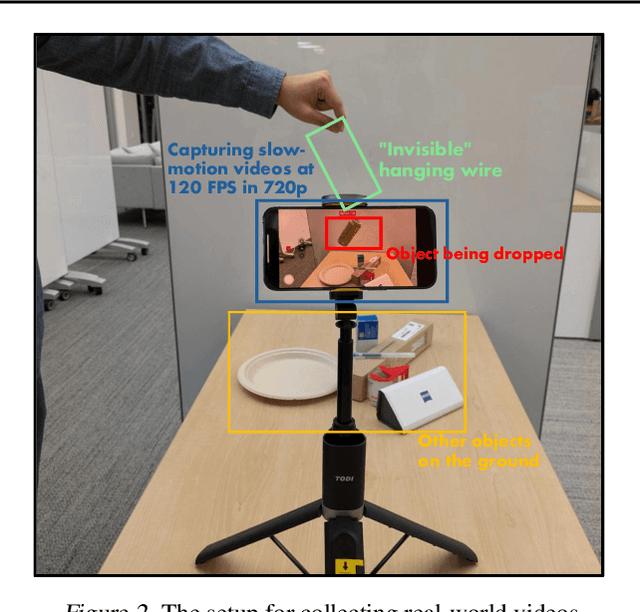

Large-scale pre-trained video generation models excel in content creation but are not reliable as physically accurate world simulators out of the box. This work studies the process of post-training these models for accurate world modeling through the lens of the simple, yet fundamental, physics task of modeling object freefall. We show state-of-the-art video generation models struggle with this basic task, despite their visually impressive outputs. To remedy this problem, we find that fine-tuning on a relatively small amount of simulated videos is effective in inducing the dropping behavior in the model, and we can further improve results through a novel reward modeling procedure we introduce. Our study also reveals key limitations of post-training in generalization and distribution modeling. Additionally, we release a benchmark for this task that may serve as a useful diagnostic tool for tracking physical accuracy in large-scale video generative model development.
Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs
Jun 24, 2024


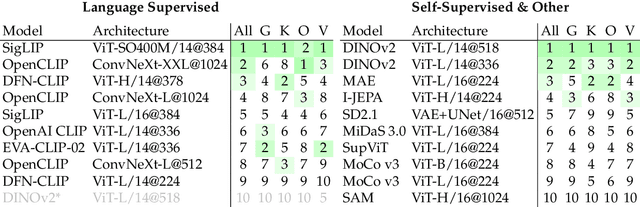
We introduce Cambrian-1, a family of multimodal LLMs (MLLMs) designed with a vision-centric approach. While stronger language models can enhance multimodal capabilities, the design choices for vision components are often insufficiently explored and disconnected from visual representation learning research. This gap hinders accurate sensory grounding in real-world scenarios. Our study uses LLMs and visual instruction tuning as an interface to evaluate various visual representations, offering new insights into different models and architectures -- self-supervised, strongly supervised, or combinations thereof -- based on experiments with over 20 vision encoders. We critically examine existing MLLM benchmarks, addressing the difficulties involved in consolidating and interpreting results from various tasks, and introduce a new vision-centric benchmark, CV-Bench. To further improve visual grounding, we propose the Spatial Vision Aggregator (SVA), a dynamic and spatially-aware connector that integrates high-resolution vision features with LLMs while reducing the number of tokens. Additionally, we discuss the curation of high-quality visual instruction-tuning data from publicly available sources, emphasizing the importance of data source balancing and distribution ratio. Collectively, Cambrian-1 not only achieves state-of-the-art performance but also serves as a comprehensive, open cookbook for instruction-tuned MLLMs. We provide model weights, code, supporting tools, datasets, and detailed instruction-tuning and evaluation recipes. We hope our release will inspire and accelerate advancements in multimodal systems and visual representation learning.
Image Sculpting: Precise Object Editing with 3D Geometry Control
Jan 02, 2024We present Image Sculpting, a new framework for editing 2D images by incorporating tools from 3D geometry and graphics. This approach differs markedly from existing methods, which are confined to 2D spaces and typically rely on textual instructions, leading to ambiguity and limited control. Image Sculpting converts 2D objects into 3D, enabling direct interaction with their 3D geometry. Post-editing, these objects are re-rendered into 2D, merging into the original image to produce high-fidelity results through a coarse-to-fine enhancement process. The framework supports precise, quantifiable, and physically-plausible editing options such as pose editing, rotation, translation, 3D composition, carving, and serial addition. It marks an initial step towards combining the creative freedom of generative models with the precision of graphics pipelines.
Kosmos-G: Generating Images in Context with Multimodal Large Language Models
Oct 04, 2023Recent advancements in text-to-image (T2I) and vision-language-to-image (VL2I) generation have made significant strides. However, the generation from generalized vision-language inputs, especially involving multiple images, remains under-explored. This paper presents Kosmos-G, a model that leverages the advanced perception capabilities of Multimodal Large Language Models (MLLMs) to tackle the aforementioned challenge. Our approach aligns the output space of MLLM with CLIP using the textual modality as an anchor and performs compositional instruction tuning on curated data. Kosmos-G demonstrates a unique capability of zero-shot multi-entity subject-driven generation. Notably, the score distillation instruction tuning requires no modifications to the image decoder. This allows for a seamless substitution of CLIP and effortless integration with a myriad of U-Net techniques ranging from fine-grained controls to personalized image decoder variants. We posit Kosmos-G as an initial attempt towards the goal of "image as a foreign language in image generation."