 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVAD: Vectorized Scene Representation for Efficient Autonomous Driving
Mar 21, 2023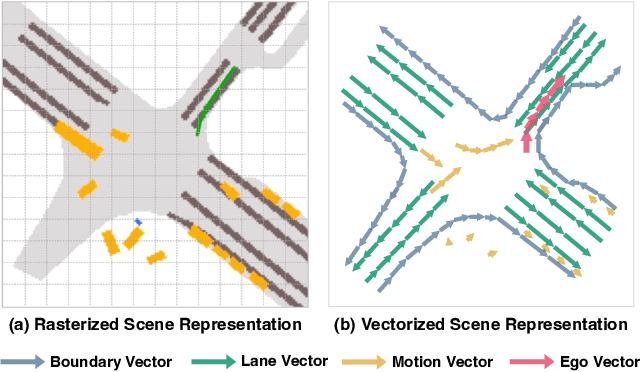
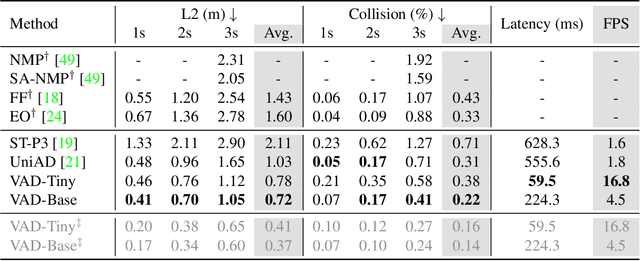
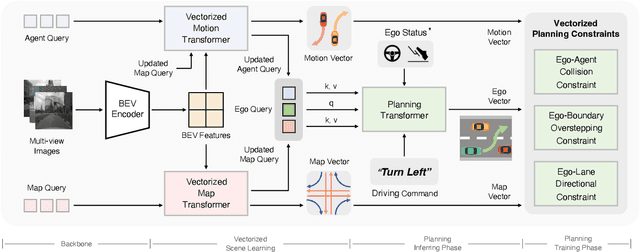
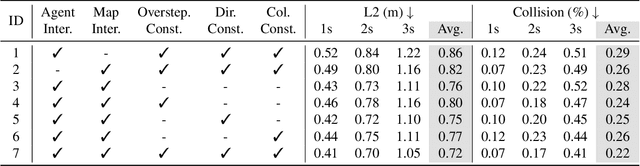
Autonomous driving requires a comprehensive understanding of the surrounding environment for reliable trajectory planning. Previous works rely on dense rasterized scene representation (e.g., agent occupancy and semantic map) to perform planning, which is computationally intensive and misses the instance-level structure information. In this paper, we propose VAD, an end-to-end vectorized paradigm for autonomous driving, which models the driving scene as fully vectorized representation. The proposed vectorized paradigm has two significant advantages. On one hand, VAD exploits the vectorized agent motion and map elements as explicit instance-level planning constraints which effectively improves planning safety. On the other hand, VAD runs much faster than previous end-to-end planning methods by getting rid of computation-intensive rasterized representation and hand-designed post-processing steps. VAD achieves state-of-the-art end-to-end planning performance on the nuScenes dataset, outperforming the previous best method by a large margin (reducing the average collision rate by 48.4%). Besides, VAD greatly improves the inference speed (up to 9.3x), which is critical for the real-world deployment of an autonomous driving system. Code and models will be released for facilitating future research.
Perceive, Interact, Predict: Learning Dynamic and Static Clues for End-to-End Motion Prediction
Dec 05, 2022



Motion prediction is highly relevant to the perception of dynamic objects and static map elements in the scenarios of autonomous driving. In this work, we propose PIP, the first end-to-end Transformer-based framework which jointly and interactively performs online mapping, object detection and motion prediction. PIP leverages map queries, agent queries and mode queries to encode the instance-wise information of map elements, agents and motion intentions, respectively. Based on the unified query representation, a differentiable multi-task interaction scheme is proposed to exploit the correlation between perception and prediction. Even without human-annotated HD map or agent's historical tracking trajectory as guidance information, PIP realizes end-to-end multi-agent motion prediction and achieves better performance than tracking-based and HD-map-based methods. PIP provides comprehensive high-level information of the driving scene (vectorized static map and dynamic objects with motion information), and contributes to the downstream planning and control. Code and models will be released for facilitating further research.
MixSKD: Self-Knowledge Distillation from Mixup for Image Recognition
Aug 11, 2022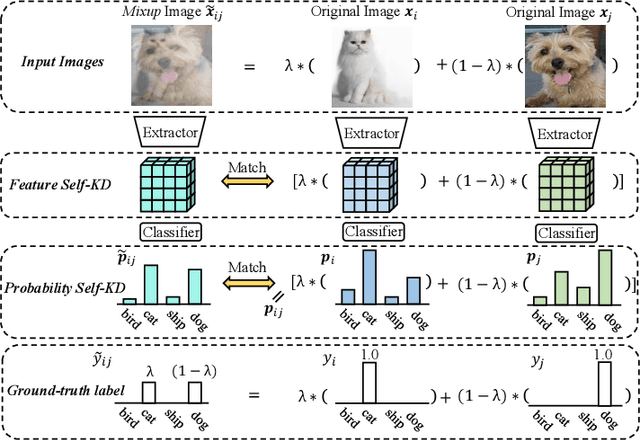
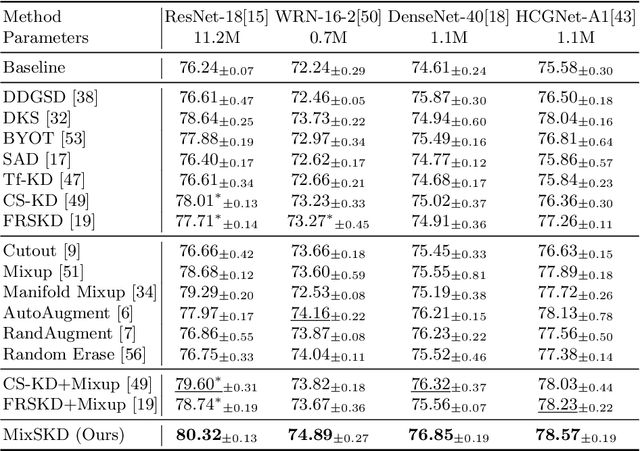
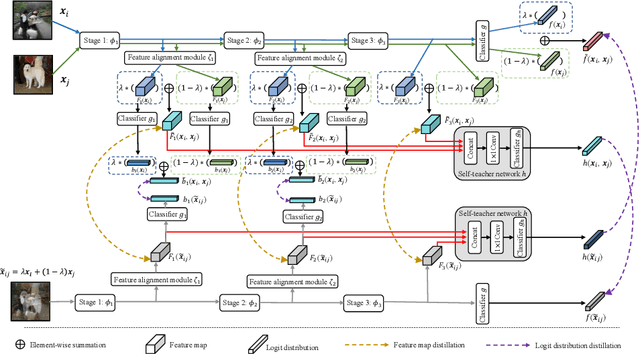
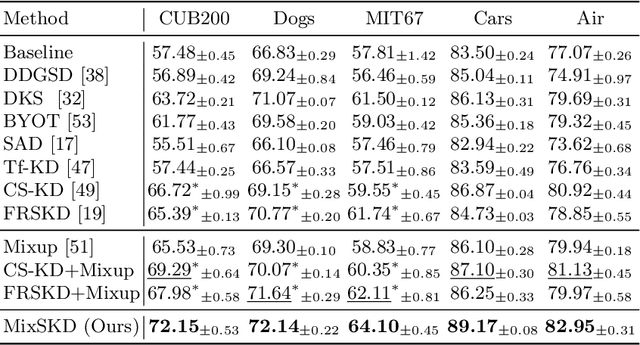
Unlike the conventional Knowledge Distillation (KD), Self-KD allows a network to learn knowledge from itself without any guidance from extra networks. This paper proposes to perform Self-KD from image Mixture (MixSKD), which integrates these two techniques into a unified framework. MixSKD mutually distills feature maps and probability distributions between the random pair of original images and their mixup images in a meaningful way. Therefore, it guides the network to learn cross-image knowledge by modelling supervisory signals from mixup images. Moreover, we construct a self-teacher network by aggregating multi-stage feature maps for providing soft labels to supervise the backbone classifier, further improving the efficacy of self-boosting. Experiments on image classification and transfer learning to object detection and semantic segmentation demonstrate that MixSKD outperforms other state-of-the-art Self-KD and data augmentation methods. The code is available at https://github.com/winycg/Self-KD-Lib.
Online Knowledge Distillation via Mutual Contrastive Learning for Visual Recognition
Jul 23, 2022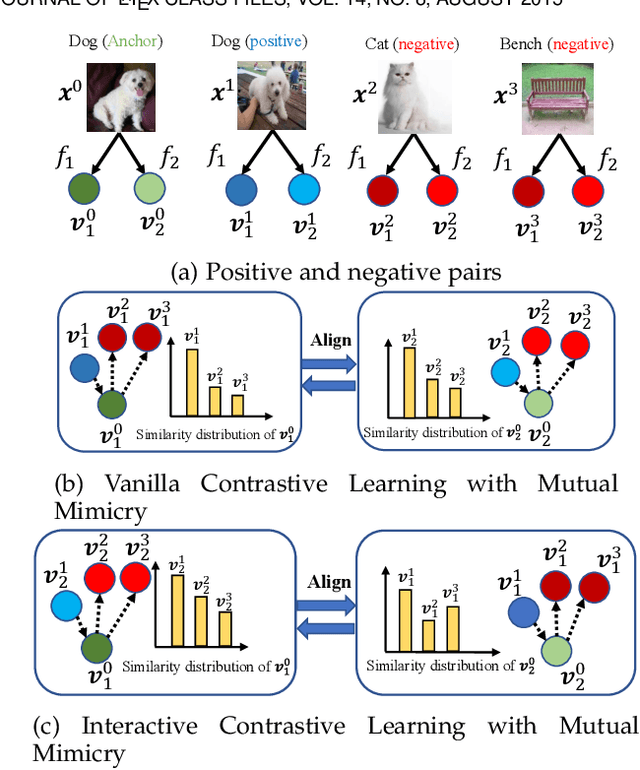
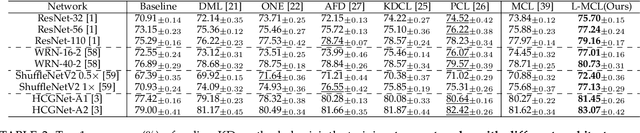
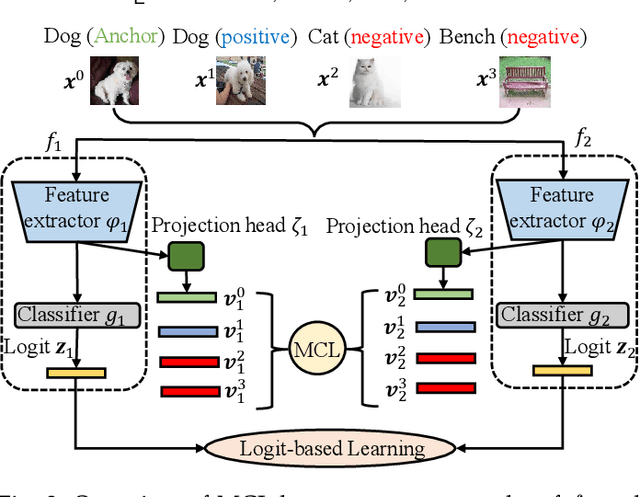
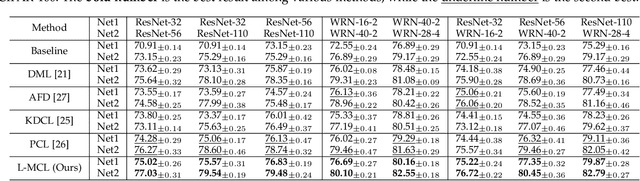
The teacher-free online Knowledge Distillation (KD) aims to train an ensemble of multiple student models collaboratively and distill knowledge from each other. Although existing online KD methods achieve desirable performance, they often focus on class probabilities as the core knowledge type, ignoring the valuable feature representational information. We present a Mutual Contrastive Learning (MCL) framework for online KD. The core idea of MCL is to perform mutual interaction and transfer of contrastive distributions among a cohort of networks in an online manner. Our MCL can aggregate cross-network embedding information and maximize the lower bound to the mutual information between two networks. This enables each network to learn extra contrastive knowledge from others, leading to better feature representations, thus improving the performance of visual recognition tasks. Beyond the final layer, we extend MCL to several intermediate layers assisted by auxiliary feature refinement modules. This further enhances the ability of representation learning for online KD. Experiments on image classification and transfer learning to visual recognition tasks show that MCL can lead to consistent performance gains against state-of-the-art online KD approaches. The superiority demonstrates that MCL can guide the network to generate better feature representations. Our code is publicly available at https://github.com/winycg/MCL.
HOPE: Hierarchical Spatial-temporal Network for Occupancy Flow Prediction
Jun 21, 2022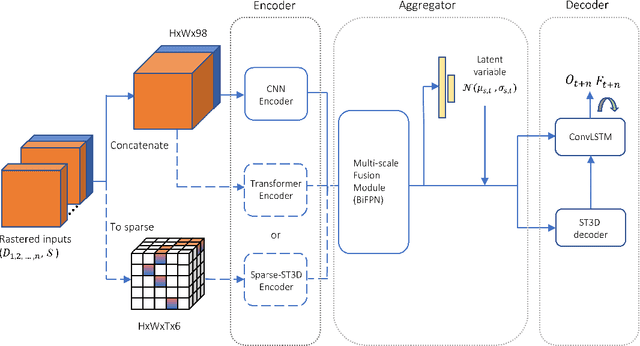

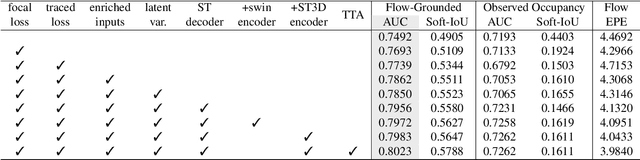
In this report, we introduce our solution to the Occupancy and Flow Prediction challenge in the Waymo Open Dataset Challenges at CVPR 2022, which ranks 1st on the leaderboard. We have developed a novel hierarchical spatial-temporal network featured with spatial-temporal encoders, a multi-scale aggregator enriched with latent variables, and a recursive hierarchical 3D decoder. We use multiple losses including focal loss and modified flow trace loss to efficiently guide the training process. Our method achieves a Flow-Grounded Occupancy AUC of 0.8389 and outperforms all the other teams on the leaderboard.
Cross-Image Relational Knowledge Distillation for Semantic Segmentation
Apr 14, 2022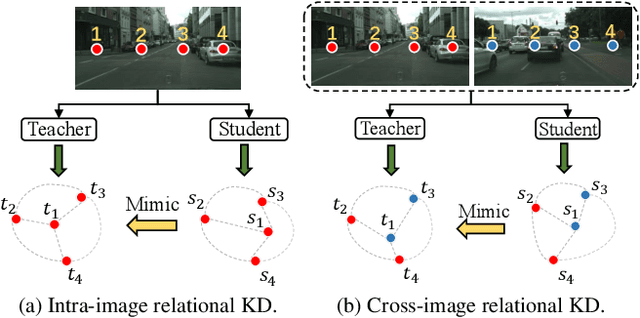
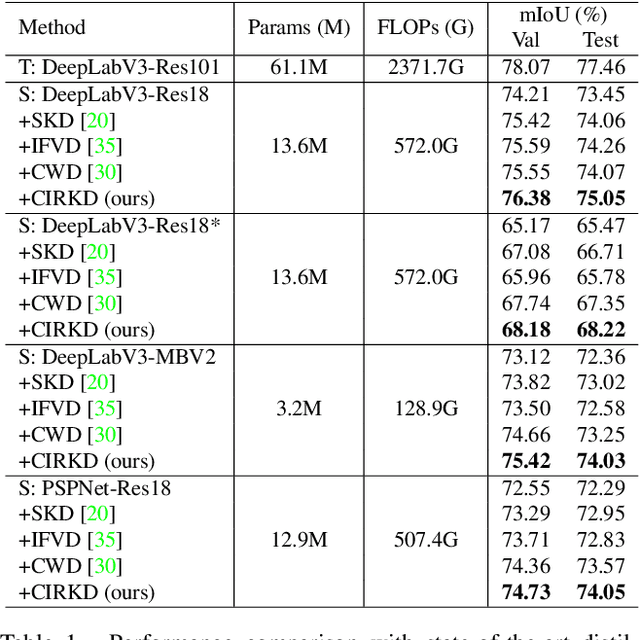
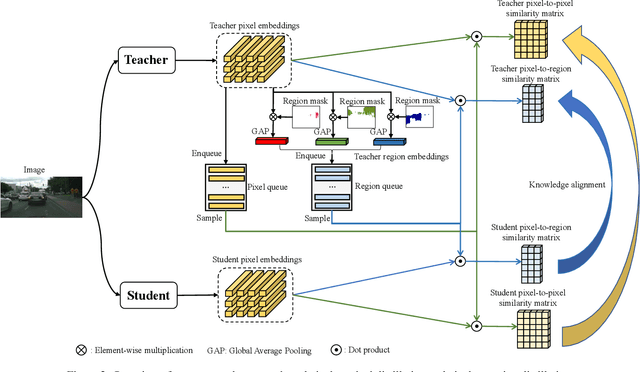
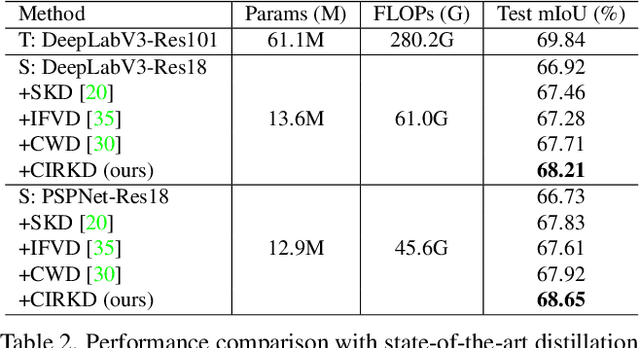
Current Knowledge Distillation (KD) methods for semantic segmentation often guide the student to mimic the teacher's structured information generated from individual data samples. However, they ignore the global semantic relations among pixels across various images that are valuable for KD. This paper proposes a novel Cross-Image Relational KD (CIRKD), which focuses on transferring structured pixel-to-pixel and pixel-to-region relations among the whole images. The motivation is that a good teacher network could construct a well-structured feature space in terms of global pixel dependencies. CIRKD makes the student mimic better structured semantic relations from the teacher, thus improving the segmentation performance. Experimental results over Cityscapes, CamVid and Pascal VOC datasets demonstrate the effectiveness of our proposed approach against state-of-the-art distillation methods. The code is available at https://github.com/winycg/CIRKD.
Leveraging Unimodal Self-Supervised Learning for Multimodal Audio-Visual Speech Recognition
Mar 26, 2022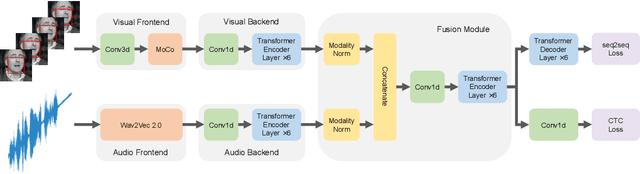
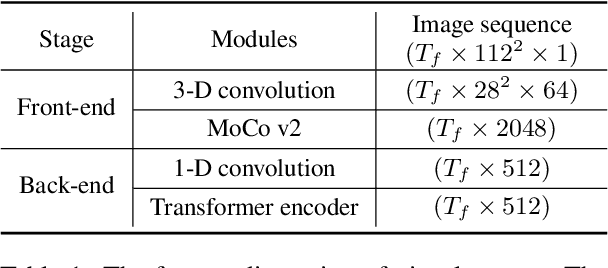


Training Transformer-based models demands a large amount of data, while obtaining aligned and labelled data in multimodality is rather cost-demanding, especially for audio-visual speech recognition (AVSR). Thus it makes a lot of sense to make use of unlabelled unimodal data. On the other side, although the effectiveness of large-scale self-supervised learning is well established in both audio and visual modalities, how to integrate those pre-trained models into a multimodal scenario remains underexplored. In this work, we successfully leverage unimodal self-supervised learning to promote the multimodal AVSR. In particular, audio and visual front-ends are trained on large-scale unimodal datasets, then we integrate components of both front-ends into a larger multimodal framework which learns to recognize parallel audio-visual data into characters through a combination of CTC and seq2seq decoding. We show that both components inherited from unimodal self-supervised learning cooperate well, resulting in that the multimodal framework yields competitive results through fine-tuning. Our model is experimentally validated on both word-level and sentence-level tasks. Especially, even without an external language model, our proposed model raises the state-of-the-art performances on the widely accepted Lip Reading Sentences 2 (LRS2) dataset by a large margin, with a relative improvement of 30%.
Rethinking Soft Labels for Knowledge Distillation: A Bias-Variance Tradeoff Perspective
Feb 01, 2021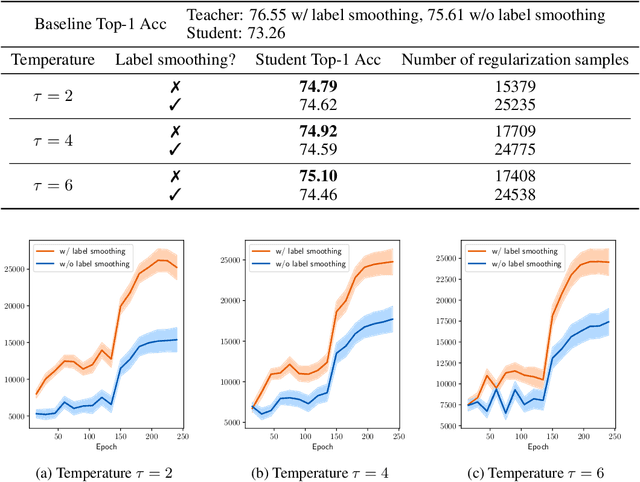
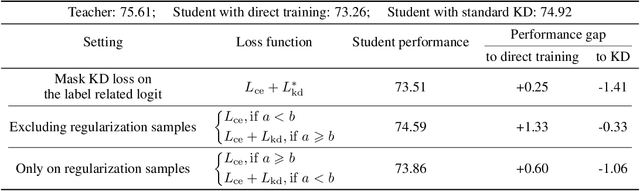

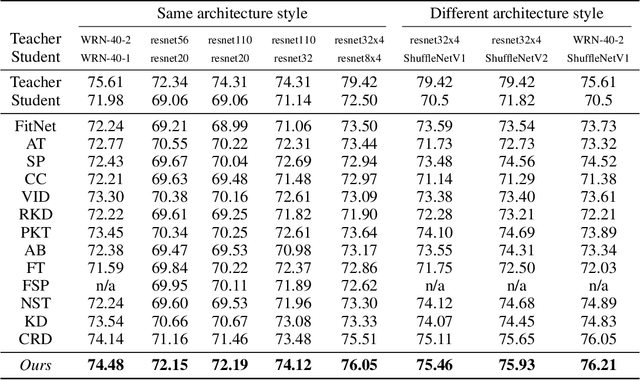
Knowledge distillation is an effective approach to leverage a well-trained network or an ensemble of them, named as the teacher, to guide the training of a student network. The outputs from the teacher network are used as soft labels for supervising the training of a new network. Recent studies \citep{muller2019does,yuan2020revisiting} revealed an intriguing property of the soft labels that making labels soft serves as a good regularization to the student network. From the perspective of statistical learning, regularization aims to reduce the variance, however how bias and variance change is not clear for training with soft labels. In this paper, we investigate the bias-variance tradeoff brought by distillation with soft labels. Specifically, we observe that during training the bias-variance tradeoff varies sample-wisely. Further, under the same distillation temperature setting, we observe that the distillation performance is negatively associated with the number of some specific samples, which are named as regularization samples since these samples lead to bias increasing and variance decreasing. Nevertheless, we empirically find that completely filtering out regularization samples also deteriorates distillation performance. Our discoveries inspired us to propose the novel weighted soft labels to help the network adaptively handle the sample-wise bias-variance tradeoff. Experiments on standard evaluation benchmarks validate the effectiveness of our method. Our code is available at \url{https://github.com/bellymonster/Weighted-Soft-Label-Distillation}.
VarGNet: Variable Group Convolutional Neural Network for Efficient Embedded Computing
Jul 12, 2019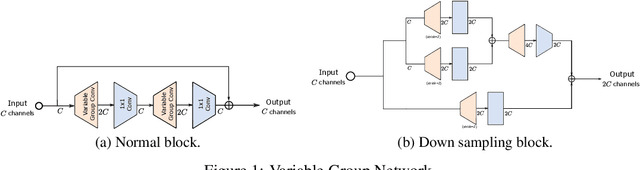
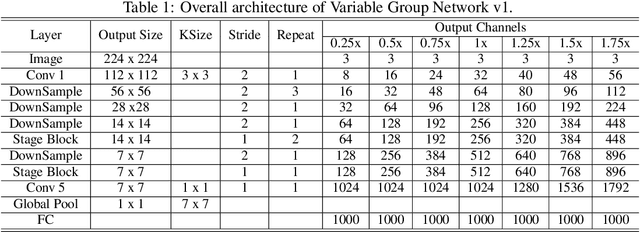
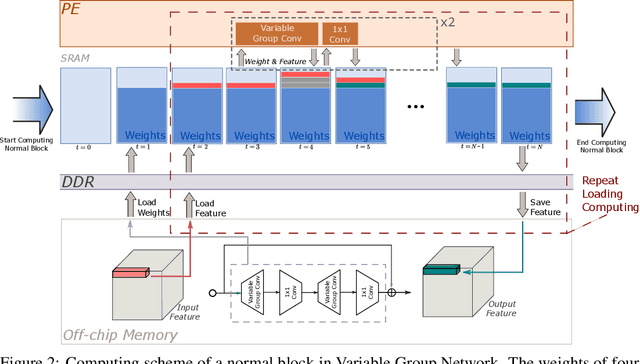
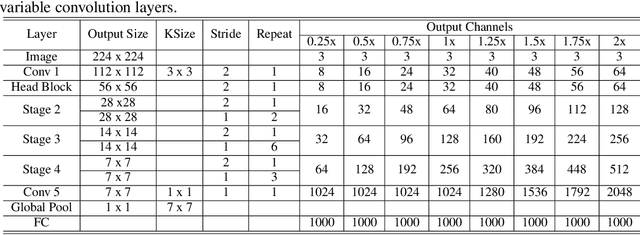
In this paper, we propose a novel network design mechanism for efficient embedded computing. Inspired by the limited computing patterns, we propose to fix the number of channels in a group convolution, instead of the existing practice that fixing the total group numbers. Our solution based network, named Variable Group Convolutional Network (VarGNet), can be optimized easier on hardware side, due to the more unified computing schemes among the layers. Extensive experiments on various vision tasks, including classification, detection, pixel-wise parsing and face recognition, have demonstrated the practical value of our VarGNet.