 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixSKD: Self-Knowledge Distillation from Mixup for Image Recognition
Aug 11, 2022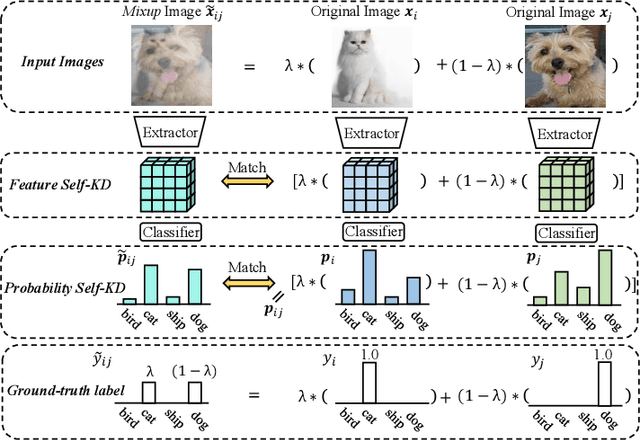
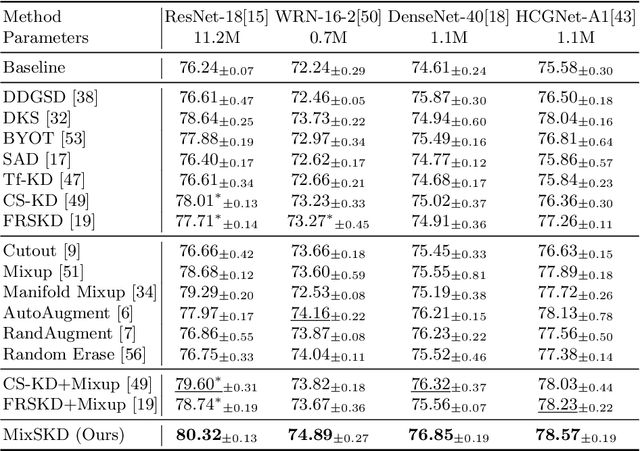
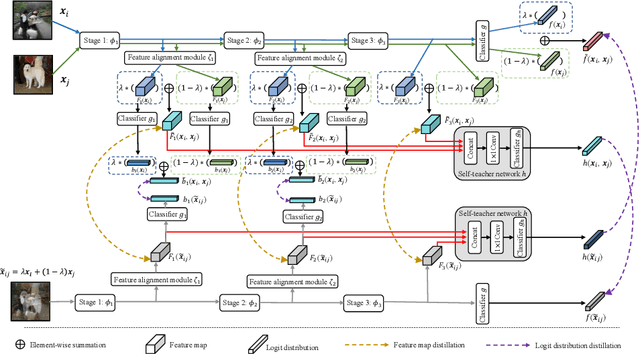
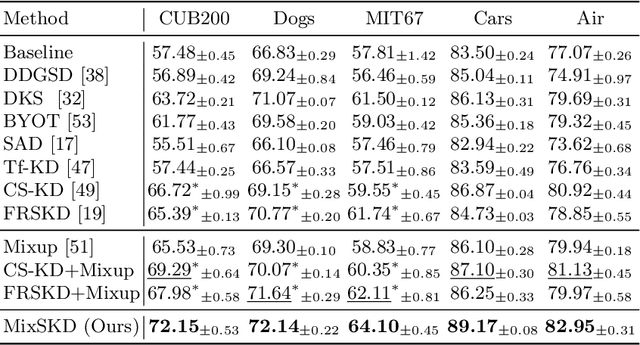
Unlike the conventional Knowledge Distillation (KD), Self-KD allows a network to learn knowledge from itself without any guidance from extra networks. This paper proposes to perform Self-KD from image Mixture (MixSKD), which integrates these two techniques into a unified framework. MixSKD mutually distills feature maps and probability distributions between the random pair of original images and their mixup images in a meaningful way. Therefore, it guides the network to learn cross-image knowledge by modelling supervisory signals from mixup images. Moreover, we construct a self-teacher network by aggregating multi-stage feature maps for providing soft labels to supervise the backbone classifier, further improving the efficacy of self-boosting. Experiments on image classification and transfer learning to object detection and semantic segmentation demonstrate that MixSKD outperforms other state-of-the-art Self-KD and data augmentation methods. The code is available at https://github.com/winycg/Self-KD-Lib.
Lifelong Generative Learning via Knowledge Reconstruction
Jan 17, 2022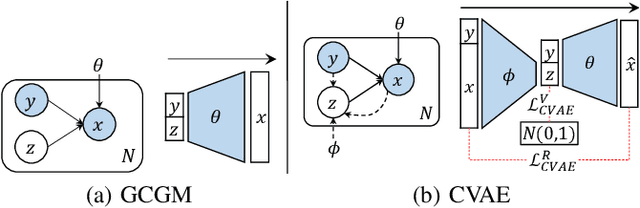
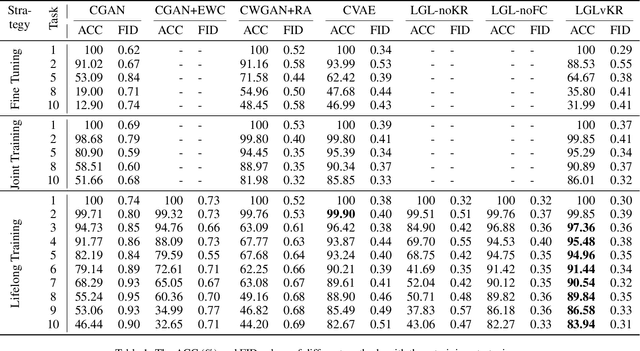
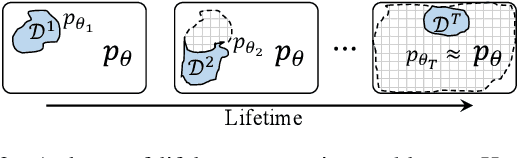
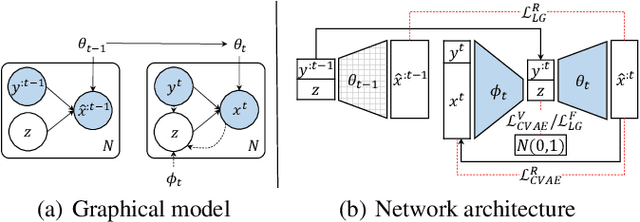
Generative models often incur the catastrophic forgetting problem when they are used to sequentially learning multiple tasks, i.e., lifelong generative learning. Although there are some endeavors to tackle this problem, they suffer from high time-consumptions or error accumulation. In this work, we develop an efficient and effective lifelong generative model based on variational autoencoder (VAE). Unlike the generative adversarial network, VAE enjoys high efficiency in the training process, providing natural benefits with few resources. We deduce a lifelong generative model by expending the intrinsic reconstruction character of VAE to the historical knowledge retention. Further, we devise a feedback strategy about the reconstructed data to alleviate the error accumulation. Experiments on the lifelong generating tasks of MNIST, FashionMNIST, and SVHN verified the efficacy of our approach, where the results were comparable to SOTA.