 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixSKD: Self-Knowledge Distillation from Mixup for Image Recognition
Aug 11, 2022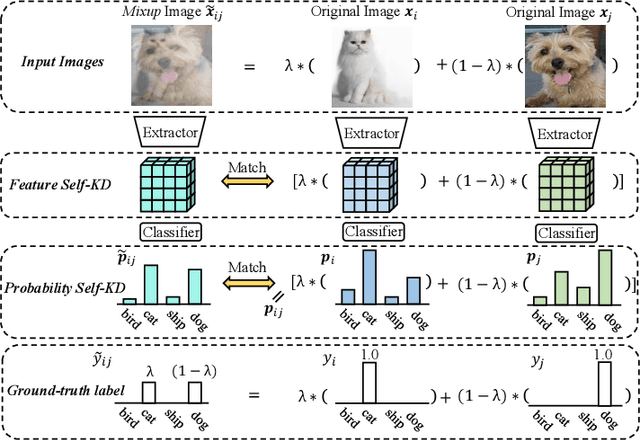
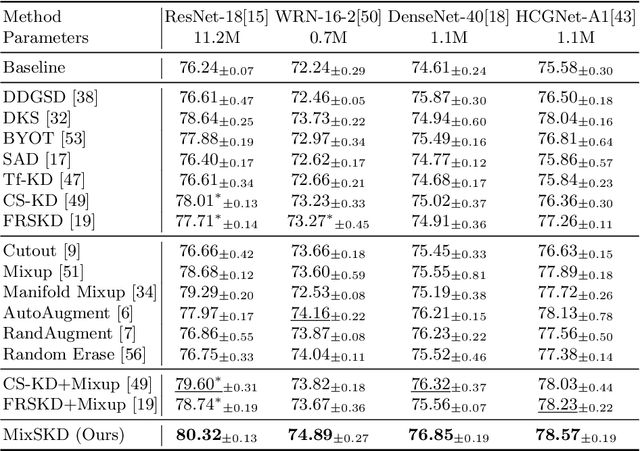
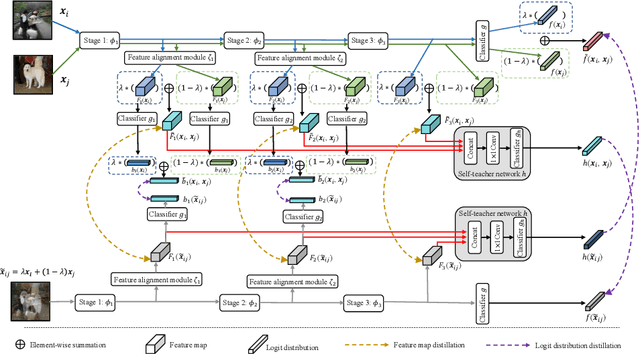
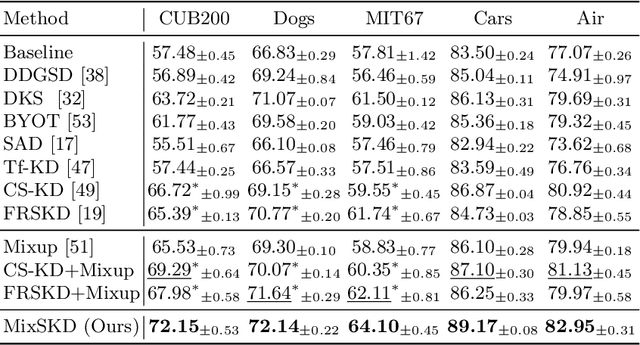
Unlike the conventional Knowledge Distillation (KD), Self-KD allows a network to learn knowledge from itself without any guidance from extra networks. This paper proposes to perform Self-KD from image Mixture (MixSKD), which integrates these two techniques into a unified framework. MixSKD mutually distills feature maps and probability distributions between the random pair of original images and their mixup images in a meaningful way. Therefore, it guides the network to learn cross-image knowledge by modelling supervisory signals from mixup images. Moreover, we construct a self-teacher network by aggregating multi-stage feature maps for providing soft labels to supervise the backbone classifier, further improving the efficacy of self-boosting. Experiments on image classification and transfer learning to object detection and semantic segmentation demonstrate that MixSKD outperforms other state-of-the-art Self-KD and data augmentation methods. The code is available at https://github.com/winycg/Self-KD-Lib.
Knowledge Distillation Using Hierarchical Self-Supervision Augmented Distribution
Sep 07, 2021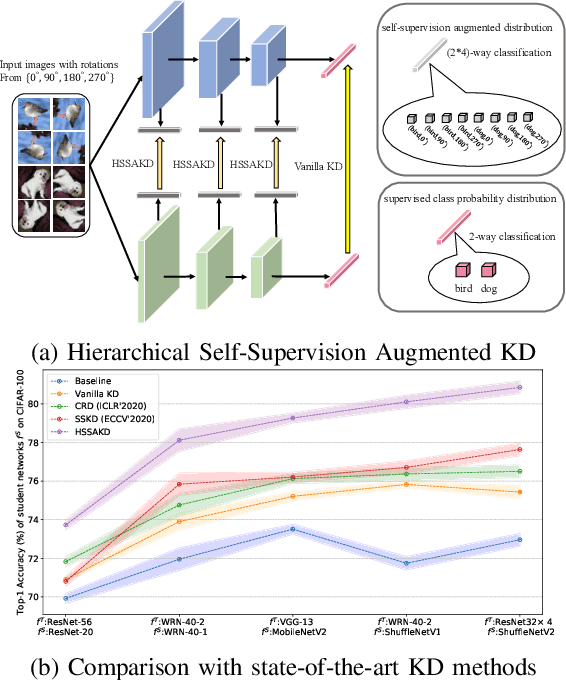
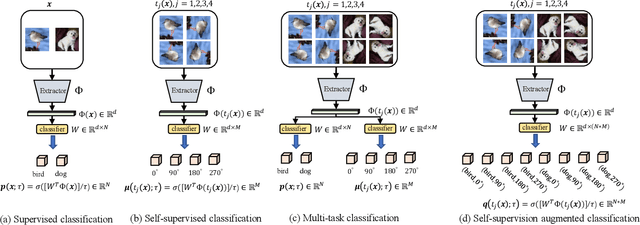
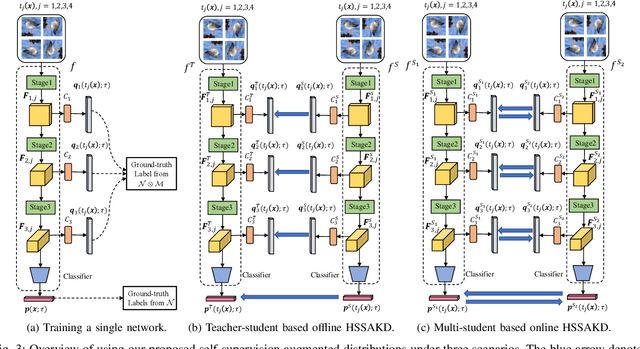
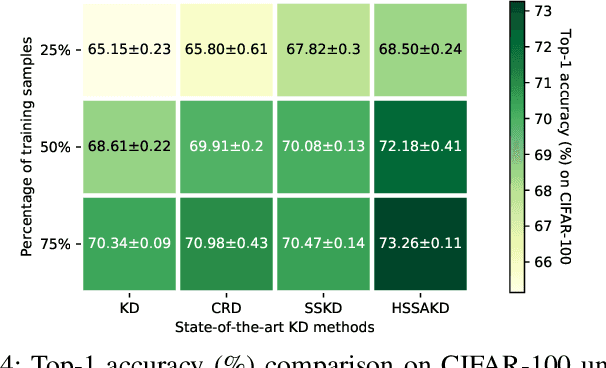
Knowledge distillation (KD) is an effective framework that aims to transfer meaningful information from a large teacher to a smaller student. Generally, KD often involves how to define and transfer knowledge. Previous KD methods often focus on mining various forms of knowledge, for example, feature maps and refined information. However, the knowledge is derived from the primary supervised task and thus is highly task-specific. Motivated by the recent success of self-supervised representation learning, we propose an auxiliary self-supervision augmented task to guide networks to learn more meaningful features. Therefore, we can derive soft self-supervision augmented distributions as richer dark knowledge from this task for KD. Unlike previous knowledge, this distribution encodes joint knowledge from supervised and self-supervised feature learning. Beyond knowledge exploration, another crucial aspect is how to learn and distill our proposed knowledge effectively. To fully take advantage of hierarchical feature maps, we propose to append several auxiliary branches at various hidden layers. Each auxiliary branch is guided to learn self-supervision augmented task and distill this distribution from teacher to student. Thus we call our KD method as Hierarchical Self-Supervision Augmented Knowledge Distillation (HSSAKD). Experiments on standard image classification show that both offline and online HSSAKD achieves state-of-the-art performance in the field of KD. Further transfer experiments on object detection further verify that HSSAKD can guide the network to learn better features, which can be attributed to learn and distill an auxiliary self-supervision augmented task effectively.
Hierarchical Self-supervised Augmented Knowledge Distillation
Jul 29, 2021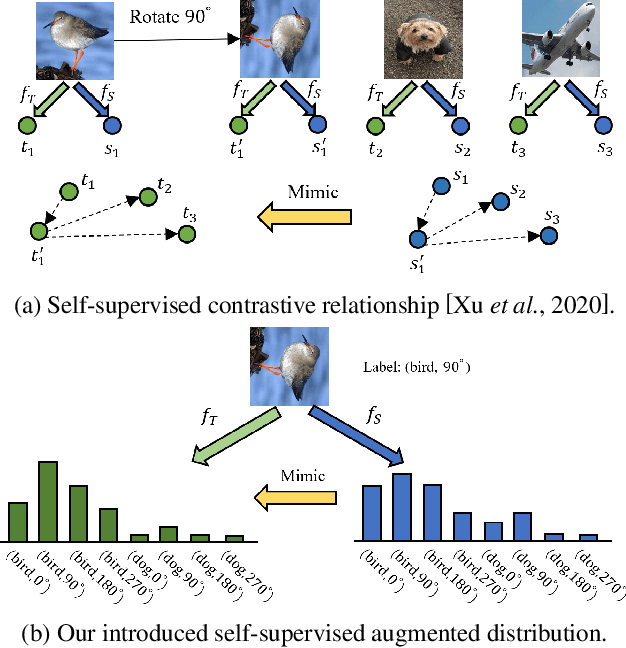

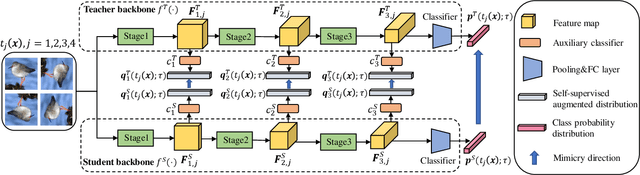
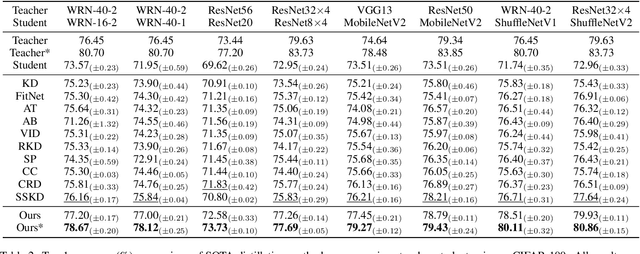
Knowledge distillation often involves how to define and transfer knowledge from teacher to student effectively. Although recent self-supervised contrastive knowledge achieves the best performance, forcing the network to learn such knowledge may damage the representation learning of the original class recognition task. We therefore adopt an alternative self-supervised augmented task to guide the network to learn the joint distribution of the original recognition task and self-supervised auxiliary task. It is demonstrated as a richer knowledge to improve the representation power without losing the normal classification capability. Moreover, it is incomplete that previous methods only transfer the probabilistic knowledge between the final layers. We propose to append several auxiliary classifiers to hierarchical intermediate feature maps to generate diverse self-supervised knowledge and perform the one-to-one transfer to teach the student network thoroughly. Our method significantly surpasses the previous SOTA SSKD with an average improvement of 2.56\% on CIFAR-100 and an improvement of 0.77\% on ImageNet across widely used network pairs. Codes are available at https://github.com/winycg/HSAKD.
Mutual Contrastive Learning for Visual Representation Learning
Apr 26, 2021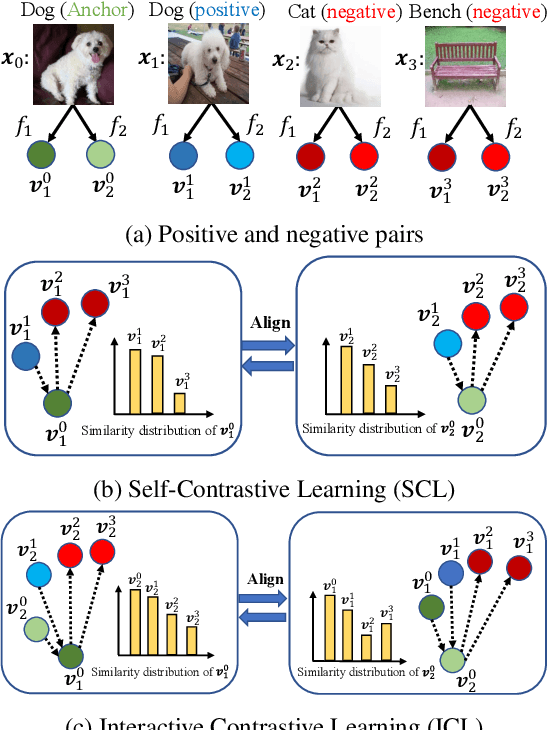
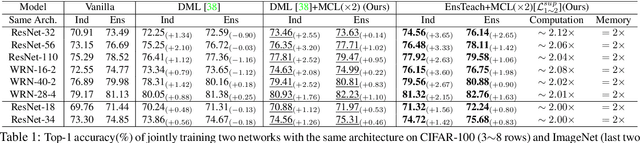
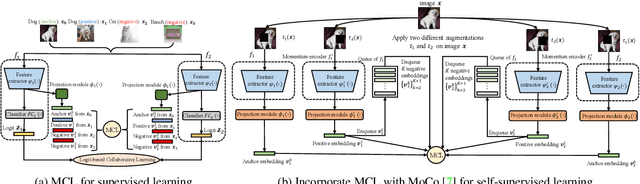
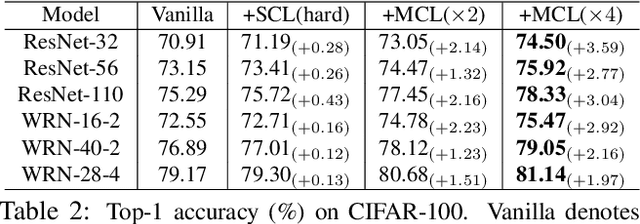
We present a collaborative learning method called Mutual Contrastive Learning (MCL) for general visual representation learning. The core idea of MCL is to perform mutual interaction and transfer of contrastive distributions among a cohort of models. Benefiting from MCL, each model can learn extra contrastive knowledge from others, leading to more meaningful feature representations for visual recognition tasks. We emphasize that MCL is conceptually simple yet empirically powerful. It is a generic framework that can be applied to both supervised and self-supervised representation learning. Experimental results on supervised and self-supervised image classification, transfer learning and few-shot learning show that MCL can lead to consistent performance gains, demonstrating that MCL can guide the network to generate better feature representations.
GHFP: Gradually Hard Filter Pruning
Nov 06, 2020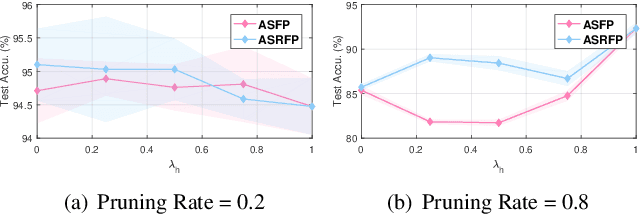
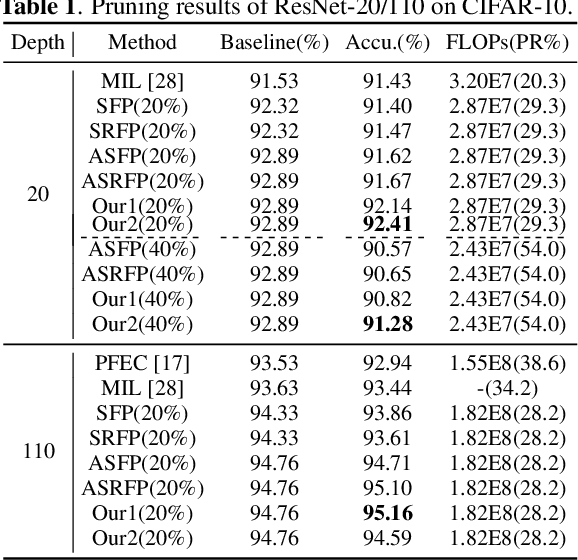
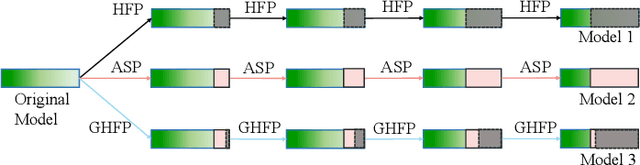
Filter pruning is widely used to reduce the computation of deep learning, enabling the deployment of Deep Neural Networks (DNNs) in resource-limited devices. Conventional Hard Filter Pruning (HFP) method zeroizes pruned filters and stops updating them, thus reducing the search space of the model. On the contrary, Soft Filter Pruning (SFP) simply zeroizes pruned filters, keeping updating them in the following training epochs, thus maintaining the capacity of the network. However, SFP, together with its variants, converges much slower than HFP due to its larger search space. Our question is whether SFP-based methods and HFP can be combined to achieve better performance and speed up convergence. Firstly, we generalize SFP-based methods and HFP to analyze their characteristics. Then we propose a Gradually Hard Filter Pruning (GHFP) method to smoothly switch from SFP-based methods to HFP during training and pruning, thus maintaining a large search space at first, gradually reducing the capacity of the model to ensure a moderate convergence speed. Experimental results on CIFAR-10/100 show that our method achieves the state-of-the-art performance.
Softer Pruning, Incremental Regularization
Oct 19, 2020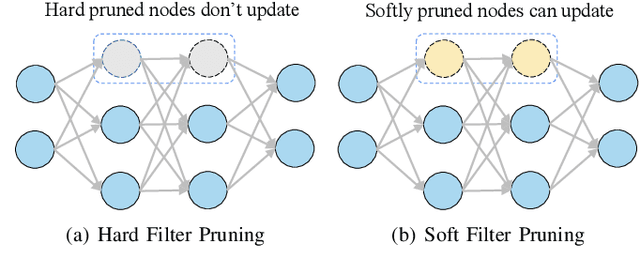
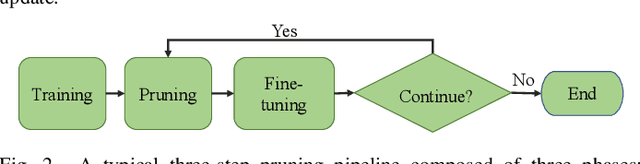
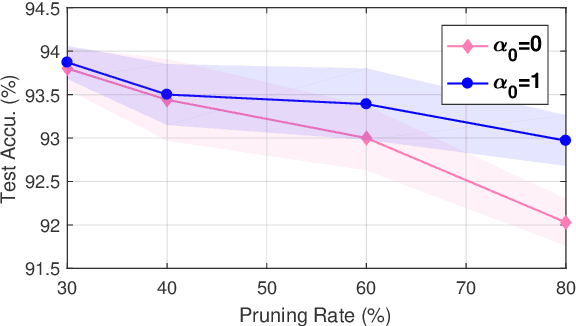
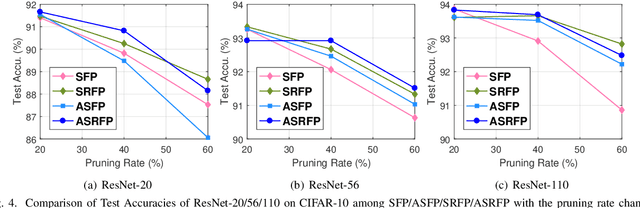
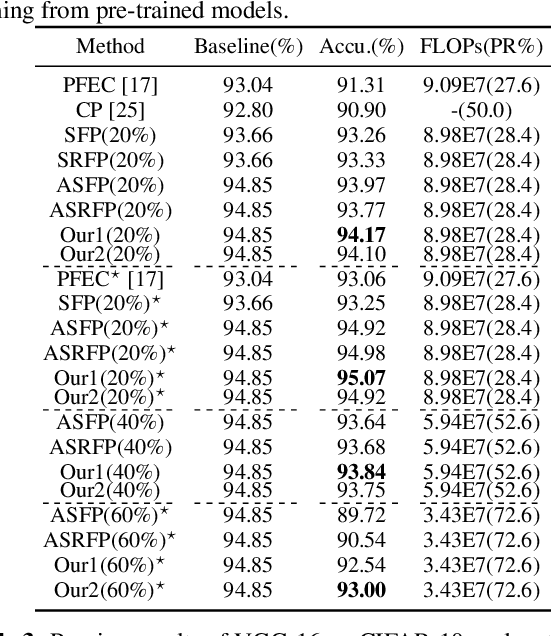
Network pruning is widely used to compress Deep Neural Networks (DNNs). The Soft Filter Pruning (SFP) method zeroizes the pruned filters during training while updating them in the next training epoch. Thus the trained information of the pruned filters is completely dropped. To utilize the trained pruned filters, we proposed a SofteR Filter Pruning (SRFP) method and its variant, Asymptotic SofteR Filter Pruning (ASRFP), simply decaying the pruned weights with a monotonic decreasing parameter. Our methods perform well across various networks, datasets and pruning rates, also transferable to weight pruning. On ILSVRC-2012, ASRFP prunes 40% of the parameters on ResNet-34 with 1.63% top-1 and 0.68% top-5 accuracy improvement. In theory, SRFP and ASRFP are an incremental regularization of the pruned filters. Besides, We note that SRFP and ASRFP pursue better results while slowing down the speed of convergence.