 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Knowledge Distillation via Mutual Contrastive Learning for Visual Recognition
Jul 23, 2022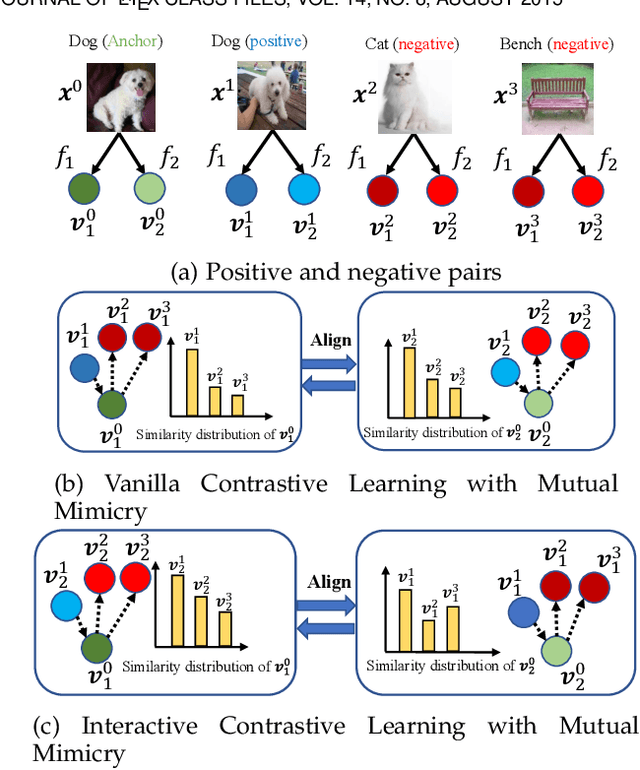
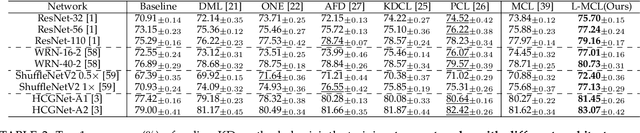
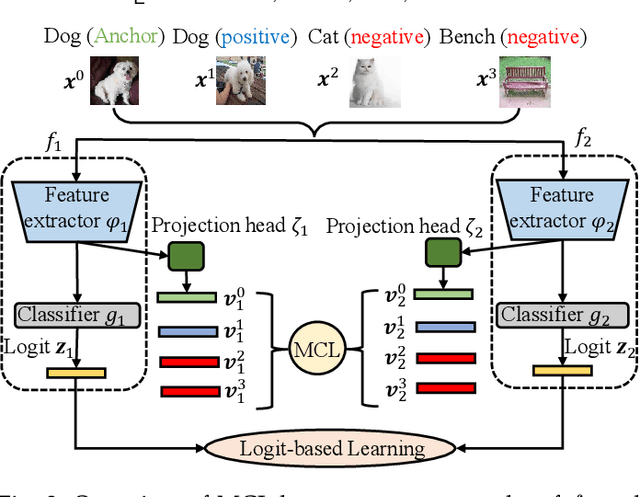
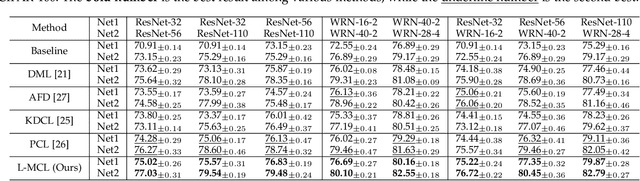
The teacher-free online Knowledge Distillation (KD) aims to train an ensemble of multiple student models collaboratively and distill knowledge from each other. Although existing online KD methods achieve desirable performance, they often focus on class probabilities as the core knowledge type, ignoring the valuable feature representational information. We present a Mutual Contrastive Learning (MCL) framework for online KD. The core idea of MCL is to perform mutual interaction and transfer of contrastive distributions among a cohort of networks in an online manner. Our MCL can aggregate cross-network embedding information and maximize the lower bound to the mutual information between two networks. This enables each network to learn extra contrastive knowledge from others, leading to better feature representations, thus improving the performance of visual recognition tasks. Beyond the final layer, we extend MCL to several intermediate layers assisted by auxiliary feature refinement modules. This further enhances the ability of representation learning for online KD. Experiments on image classification and transfer learning to visual recognition tasks show that MCL can lead to consistent performance gains against state-of-the-art online KD approaches. The superiority demonstrates that MCL can guide the network to generate better feature representations. Our code is publicly available at https://github.com/winycg/MCL.