 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperEIO: Self-Supervised Event Feature Learning for Event Inertial Odometry
Mar 29, 2025Event cameras asynchronously output low-latency event streams, promising for state estimation in high-speed motion and challenging lighting conditions. As opposed to frame-based cameras, the motion-dependent nature of event cameras presents persistent challenges in achieving robust event feature detection and matching. In recent years, learning-based approaches have demonstrated superior robustness over traditional handcrafted methods in feature detection and matching, particularly under aggressive motion and HDR scenarios. In this paper, we propose SuperEIO, a novel framework that leverages the learning-based event-only detection and IMU measurements to achieve event-inertial odometry. Our event-only feature detection employs a convolutional neural network under continuous event streams. Moreover, our system adopts the graph neural network to achieve event descriptor matching for loop closure. The proposed system utilizes TensorRT to accelerate the inference speed of deep networks, which ensures low-latency processing and robust real-time operation on resource-limited platforms. Besides, we evaluate our method extensively on multiple public datasets, demonstrating its superior accuracy and robustness compared to other state-of-the-art event-based methods. We have also open-sourced our pipeline to facilitate research in the field: https://github.com/arclab-hku/SuperEIO.
DEIO: Deep Event Inertial Odometry
Nov 06, 2024Event cameras are bio-inspired, motion-activated sensors that demonstrate impressive potential in handling challenging situations, such as motion blur and high-dynamic range. Despite their promise, existing event-based simultaneous localization and mapping (SLAM) approaches exhibit limited performance in real-world applications. On the other hand, state-of-the-art SLAM approaches that incorporate deep neural networks for better robustness and applicability. However, these is a lack of research in fusing learning-based event SLAM methods with IMU, which could be indispensable to push the event-based SLAM to large-scale, low-texture or complex scenarios. In this paper, we propose DEIO, the first monocular deep event-inertial odometry framework that combines learning-based method with traditional nonlinear graph-based optimization. Specifically, we tightly integrate a trainable event-based differentiable bundle adjustment (e-DBA) with the IMU pre-integration in a factor graph which employs keyframe-based sliding window optimization. Numerical Experiments in nine public challenge datasets show that our method can achieve superior performance compared with the image-based and event-based benchmarks. The source code is available at: https://github.com/arclab-hku/DEIO.
EVI-SAM: Robust, Real-time, Tightly-coupled Event-Visual-Inertial State Estimation and 3D Dense Mapping
Dec 19, 2023
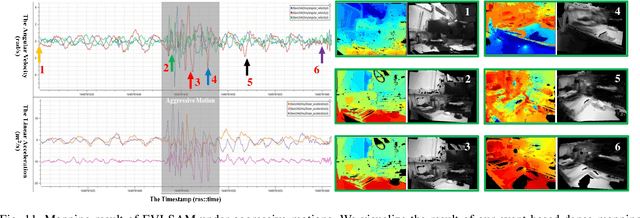

Event cameras are bio-inspired, motion-activated sensors that demonstrate substantial potential in handling challenging situations, such as motion blur and high-dynamic range. In this paper, we proposed EVI-SAM to tackle the problem of 6 DoF pose tracking and 3D reconstruction using monocular event camera. A novel event-based hybrid tracking framework is designed to estimate the pose, leveraging the robustness of feature matching and the precision of direct alignment. Specifically, we develop an event-based 2D-2D alignment to construct the photometric constraint, and tightly integrate it with the event-based reprojection constraint. The mapping module recovers the dense and colorful depth of the scene through the image-guided event-based mapping method. Subsequently, the appearance, texture, and surface mesh of the 3D scene can be reconstructed by fusing the dense depth map from multiple viewpoints using truncated signed distance function (TSDF) fusion. To the best of our knowledge, this is the first non-learning work to realize event-based dense mapping. Numerical evaluations are performed on both publicly available and self-collected datasets, which qualitatively and quantitatively demonstrate the superior performance of our method. Our EVI-SAM effectively balances accuracy and robustness while maintaining computational efficiency, showcasing superior pose tracking and dense mapping performance in challenging scenarios. Video Demo: https://youtu.be/Nn40U4e5Si8.
ECMD: An Event-Centric Multisensory Driving Dataset for SLAM
Nov 04, 2023Leveraging multiple sensors enhances complex environmental perception and increases resilience to varying luminance conditions and high-speed motion patterns, achieving precise localization and mapping. This paper proposes, ECMD, an event-centric multisensory dataset containing 81 sequences and covering over 200 km of various challenging driving scenarios including high-speed motion, repetitive scenarios, dynamic objects, etc. ECMD provides data from two sets of stereo event cameras with different resolutions (640*480, 346*260), stereo industrial cameras, an infrared camera, a top-installed mechanical LiDAR with two slanted LiDARs, two consumer-level GNSS receivers, and an onboard IMU. Meanwhile, the ground-truth of the vehicle was obtained using a centimeter-level high-accuracy GNSS-RTK/INS navigation system. All sensors are well-calibrated and temporally synchronized at the hardware level, with recording data simultaneously. We additionally evaluate several state-of-the-art SLAM algorithms for benchmarking visual and LiDAR SLAM and identifying their limitations. The dataset is available at https://arclab-hku.github.io/ecmd/.
ESVIO: Event-based Stereo Visual Inertial Odometry
Dec 26, 2022Event cameras that asynchronously output low-latency event streams provide great opportunities for state estimation under challenging situations. Despite event-based visual odometry having been extensively studied in recent years, most of them are based on monocular and few research on stereo event vision. In this paper, we present ESVIO, the first event-based stereo visual-inertial odometry, which leverages the complementary advantages of event streams, standard images and inertial measurements. Our proposed pipeline achieves temporal tracking and instantaneous matching between consecutive stereo event streams, thereby obtaining robust state estimation. In addition, the motion compensation method is designed to emphasize the edge of scenes by warping each event to reference moments with IMU and ESVIO back-end. We validate that both ESIO (purely event-based) and ESVIO (event with image-aided) have superior performance compared with other image-based and event-based baseline methods on public and self-collected datasets. Furthermore, we use our pipeline to perform onboard quadrotor flights under low-light environments. A real-world large-scale experiment is also conducted to demonstrate long-term effectiveness. We highlight that this work is a real-time, accurate system that is aimed at robust state estimation under challenging environments.
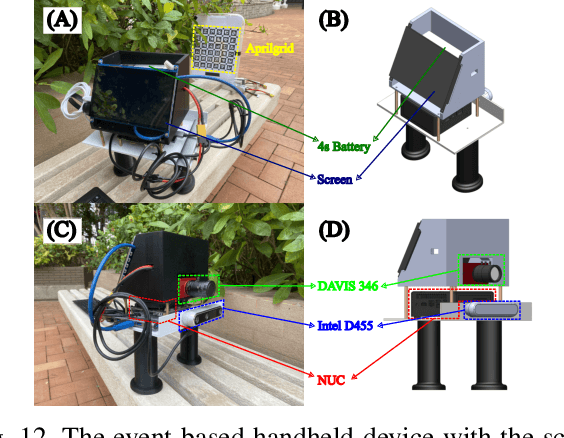
PL-EVIO: Robust Monocular Event-based Visual Inertial Odometry with Point and Line Features
Sep 25, 2022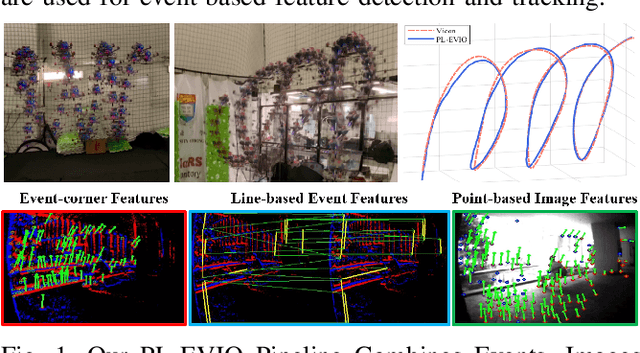

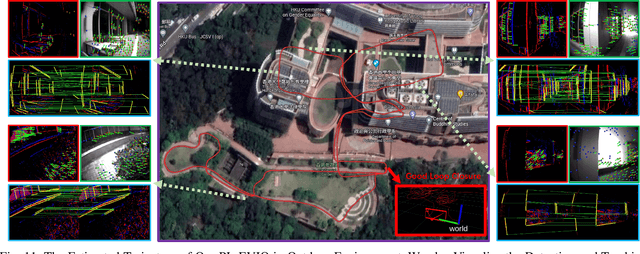
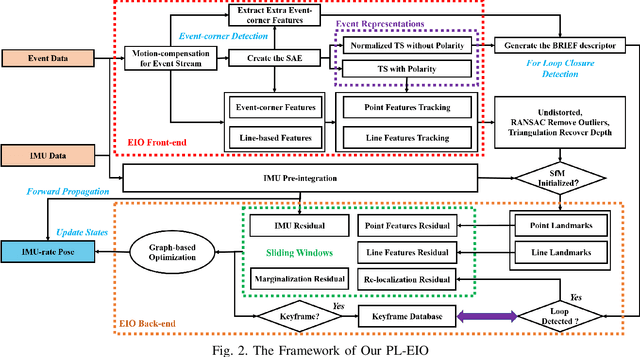
Event cameras are motion-activated sensors that capture pixel-level illumination changes instead of the intensity image with a fixed frame rate. Compared with the standard cameras, it can provide reliable visual perception during high-speed motions and in high dynamic range scenarios. However, event cameras output only a little information or even noise when the relative motion between the camera and the scene is limited, such as in a still state. While standard cameras can provide rich perception information in most scenarios, especially in good lighting conditions. These two cameras are exactly complementary. In this paper, we proposed a robust, high-accurate, and real-time optimization-based monocular event-based visual-inertial odometry (VIO) method with event-corner features, line-based event features, and point-based image features. The proposed method offers to leverage the point-based features in the nature scene and line-based features in the human-made scene to provide more additional structure or constraints information through well-design feature management. Experiments in the public benchmark datasets show that our method can achieve superior performance compared with the state-of-the-art image-based or event-based VIO. Finally, we used our method to demonstrate an onboard closed-loop autonomous quadrotor flight and large-scale outdoor experiments. Videos of the evaluations are presented on our project website: https://b23.tv/OE3QM6j
Leveraging Unimodal Self-Supervised Learning for Multimodal Audio-Visual Speech Recognition
Mar 26, 2022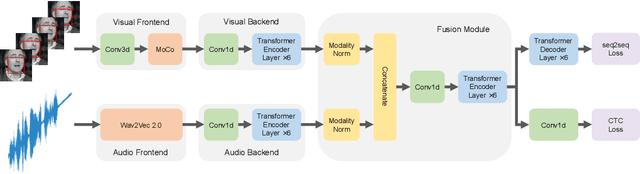
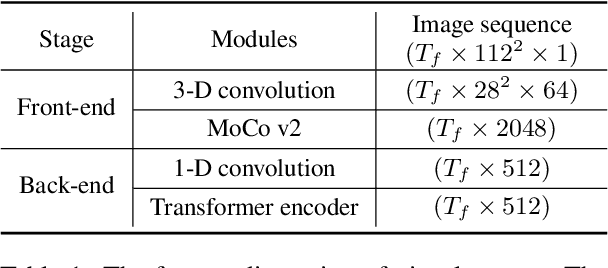


Training Transformer-based models demands a large amount of data, while obtaining aligned and labelled data in multimodality is rather cost-demanding, especially for audio-visual speech recognition (AVSR). Thus it makes a lot of sense to make use of unlabelled unimodal data. On the other side, although the effectiveness of large-scale self-supervised learning is well established in both audio and visual modalities, how to integrate those pre-trained models into a multimodal scenario remains underexplored. In this work, we successfully leverage unimodal self-supervised learning to promote the multimodal AVSR. In particular, audio and visual front-ends are trained on large-scale unimodal datasets, then we integrate components of both front-ends into a larger multimodal framework which learns to recognize parallel audio-visual data into characters through a combination of CTC and seq2seq decoding. We show that both components inherited from unimodal self-supervised learning cooperate well, resulting in that the multimodal framework yields competitive results through fine-tuning. Our model is experimentally validated on both word-level and sentence-level tasks. Especially, even without an external language model, our proposed model raises the state-of-the-art performances on the widely accepted Lip Reading Sentences 2 (LRS2) dataset by a large margin, with a relative improvement of 30%.