 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Context Compression with Interleaved Vision-Text Transformation
Jan 15, 2026Recent achievements of vision-language models in end-to-end OCR point to a new avenue for low-loss compression of textual information. This motivates earlier works that render the Transformer's input into images for prefilling, which effectively reduces the number of tokens through visual encoding, thereby alleviating the quadratically increased Attention computations. However, this partial compression fails to save computational or memory costs at token-by-token inference. In this paper, we investigate global context compression, which saves tokens at both prefilling and inference stages. Consequently, we propose VIST2, a novel Transformer that interleaves input text chunks alongside their visual encoding, while depending exclusively on visual tokens in the pre-context to predict the next text token distribution. Around this idea, we render text chunks into sketch images and train VIST2 in multiple stages, starting from curriculum-scheduled pretraining for optical language modeling, followed by modal-interleaved instruction tuning. We conduct extensive experiments using VIST2 families scaled from 0.6B to 8B to explore the training recipe and hyperparameters. With a 4$\times$ compression ratio, the resulting models demonstrate significant superiority over baselines on long writing tasks, achieving, on average, a 3$\times$ speedup in first-token generation, 77% reduction in memory usage, and 74% reduction in FLOPS. Our codes and datasets will be public to support further studies.
UrbanV2X: A Multisensory Vehicle-Infrastructure Dataset for Cooperative Navigation in Urban Areas
Dec 23, 2025
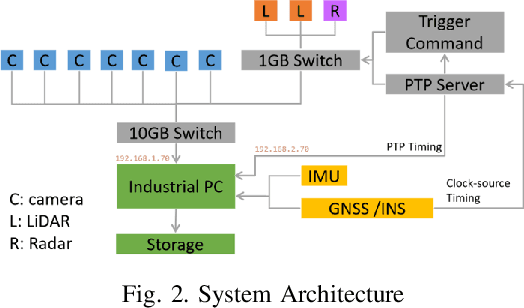

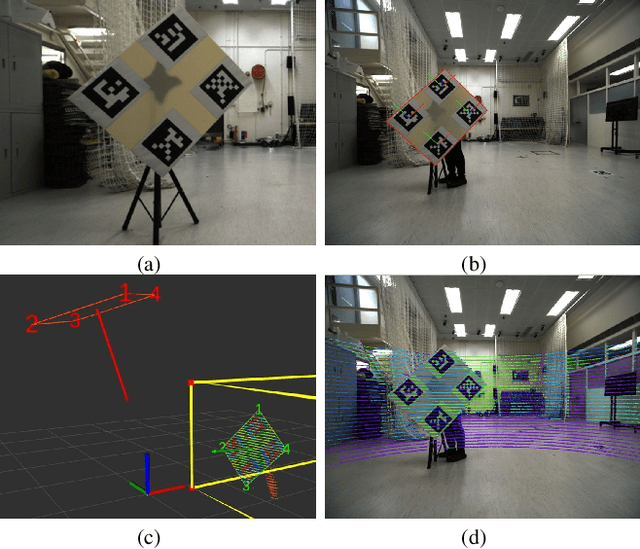
Due to the limitations of a single autonomous vehicle, Cellular Vehicle-to-Everything (C-V2X) technology opens a new window for achieving fully autonomous driving through sensor information sharing. However, real-world datasets supporting vehicle-infrastructure cooperative navigation in complex urban environments remain rare. To address this gap, we present UrbanV2X, a comprehensive multisensory dataset collected from vehicles and roadside infrastructure in the Hong Kong C-V2X testbed, designed to support research on smart mobility applications in dense urban areas. Our onboard platform provides synchronized data from multiple industrial cameras, LiDARs, 4D radar, ultra-wideband (UWB), IMU, and high-precision GNSS-RTK/INS navigation systems. Meanwhile, our roadside infrastructure provides LiDAR, GNSS, and UWB measurements. The entire vehicle-infrastructure platform is synchronized using the Precision Time Protocol (PTP), with sensor calibration data provided. We also benchmark various navigation algorithms to evaluate the collected cooperative data. The dataset is publicly available at https://polyu-taslab.github.io/UrbanV2X/.
Text-IRSTD: Leveraging Semantic Text to Promote Infrared Small Target Detection in Complex Scenes
Mar 10, 2025



Infrared small target detection is currently a hot and challenging task in computer vision. Existing methods usually focus on mining visual features of targets, which struggles to cope with complex and diverse detection scenarios. The main reason is that infrared small targets have limited image information on their own, thus relying only on visual features fails to discriminate targets and interferences, leading to lower detection performance. To address this issue, we introduce a novel approach leveraging semantic text to guide infrared small target detection, called Text-IRSTD. It innovatively expands classical IRSTD to text-guided IRSTD, providing a new research idea. On the one hand, we devise a novel fuzzy semantic text prompt to accommodate ambiguous target categories. On the other hand, we propose a progressive cross-modal semantic interaction decoder (PCSID) to facilitate information fusion between texts and images. In addition, we construct a new benchmark consisting of 2,755 infrared images of different scenarios with fuzzy semantic textual annotations, called FZDT. Extensive experimental results demonstrate that our method achieves better detection performance and target contour recovery than the state-of-the-art methods. Moreover, proposed Text-IRSTD shows strong generalization and wide application prospects in unseen detection scenarios. The dataset and code will be publicly released after acceptance of this paper.
RAP-SR: RestorAtion Prior Enhancement in Diffusion Models for Realistic Image Super-Resolution
Dec 10, 2024



Benefiting from their powerful generative capabilities, pretrained diffusion models have garnered significant attention for real-world image super-resolution (Real-SR). Existing diffusion-based SR approaches typically utilize semantic information from degraded images and restoration prompts to activate prior for producing realistic high-resolution images. However, general-purpose pretrained diffusion models, not designed for restoration tasks, often have suboptimal prior, and manually defined prompts may fail to fully exploit the generated potential. To address these limitations, we introduce RAP-SR, a novel restoration prior enhancement approach in pretrained diffusion models for Real-SR. First, we develop the High-Fidelity Aesthetic Image Dataset (HFAID), curated through a Quality-Driven Aesthetic Image Selection Pipeline (QDAISP). Our dataset not only surpasses existing ones in fidelity but also excels in aesthetic quality. Second, we propose the Restoration Priors Enhancement Framework, which includes Restoration Priors Refinement (RPR) and Restoration-Oriented Prompt Optimization (ROPO) modules. RPR refines the restoration prior using the HFAID, while ROPO optimizes the unique restoration identifier, improving the quality of the resulting images. RAP-SR effectively bridges the gap between general-purpose models and the demands of Real-SR by enhancing restoration prior. Leveraging the plug-and-play nature of RAP-SR, our approach can be seamlessly integrated into existing diffusion-based SR methods, boosting their performance. Extensive experiments demonstrate its broad applicability and state-of-the-art results. Codes and datasets will be available upon acceptance.
Single-Point Supervised High-Resolution Dynamic Network for Infrared Small Target Detection
Aug 04, 2024



Infrared small target detection (IRSTD) tasks are extremely challenging for two main reasons: 1) it is difficult to obtain accurate labelling information that is critical to existing methods, and 2) infrared (IR) small target information is easily lost in deep networks. To address these issues, we propose a single-point supervised high-resolution dynamic network (SSHD-Net). In contrast to existing methods, we achieve state-of-the-art (SOTA) detection performance using only single-point supervision. Specifically, we first design a high-resolution cross-feature extraction module (HCEM), that achieves bi-directional feature interaction through stepped feature cascade channels (SFCC). It balances network depth and feature resolution to maintain deep IR small-target information. Secondly, the effective integration of global and local features is achieved through the dynamic coordinate fusion module (DCFM), which enhances the anti-interference ability in complex backgrounds. In addition, we introduce the high-resolution multilevel residual module (HMRM) to enhance the semantic information extraction capability. Finally, we design the adaptive target localization detection head (ATLDH) to improve detection accuracy. Experiments on the publicly available datasets NUDT-SIRST and IRSTD-1k demonstrate the effectiveness of our method. Compared to other SOTA methods, our method can achieve better detection performance with only a single point of supervision.
ZeroDDI: A Zero-Shot Drug-Drug Interaction Event Prediction Method with Semantic Enhanced Learning and Dual-Modal Uniform Alignment
Jul 01, 2024



Drug-drug interactions (DDIs) can result in various pharmacological changes, which can be categorized into different classes known as DDI events (DDIEs). In recent years, previously unobserved/unseen DDIEs have been emerging, posing a new classification task when unseen classes have no labelled instances in the training stage, which is formulated as a zero-shot DDIE prediction (ZS-DDIE) task. However, existing computational methods are not directly applicable to ZS-DDIE, which has two primary challenges: obtaining suitable DDIE representations and handling the class imbalance issue. To overcome these challenges, we propose a novel method named ZeroDDI for the ZS-DDIE task. Specifically, we design a biological semantic enhanced DDIE representation learning module, which emphasizes the key biological semantics and distills discriminative molecular substructure-related semantics for DDIE representation learning. Furthermore, we propose a dual-modal uniform alignment strategy to distribute drug pair representations and DDIE semantic representations uniformly in a unit sphere and align the matched ones, which can mitigate the issue of class imbalance. Extensive experiments showed that ZeroDDI surpasses the baselines and indicate that it is a promising tool for detecting unseen DDIEs. Our code has been released in https://github.com/wzy-Sarah/ZeroDDI.
Heterogeneous Causal Metapath Graph Neural Network for Gene-Microbe-Disease Association Prediction
Jun 27, 2024The recent focus on microbes in human medicine highlights their potential role in the genetic framework of diseases. To decode the complex interactions among genes, microbes, and diseases, computational predictions of gene-microbe-disease (GMD) associations are crucial. Existing methods primarily address gene-disease and microbe-disease associations, but the more intricate triple-wise GMD associations remain less explored. In this paper, we propose a Heterogeneous Causal Metapath Graph Neural Network (HCMGNN) to predict GMD associations. HCMGNN constructs a heterogeneous graph linking genes, microbes, and diseases through their pairwise associations, and utilizes six predefined causal metapaths to extract directed causal subgraphs, which facilitate the multi-view analysis of causal relations among three entity types. Within each subgraph, we employ a causal semantic sharing message passing network for node representation learning, coupled with an attentive fusion method to integrate these representations for predicting GMD associations. Our extensive experiments show that HCMGNN effectively predicts GMD associations and addresses association sparsity issue by enhancing the graph's semantics and structure.
Video Frame Interpolation for Polarization via Swin-Transformer
Jun 17, 2024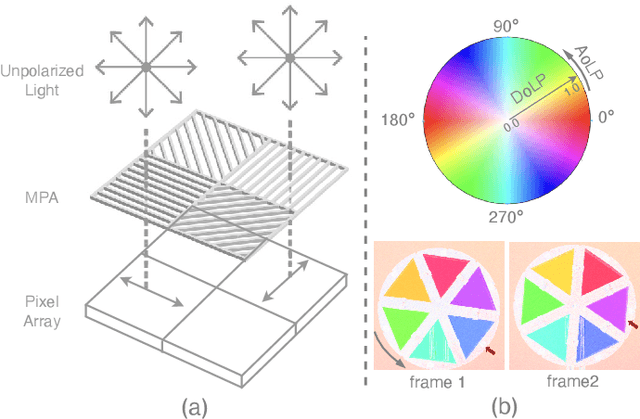
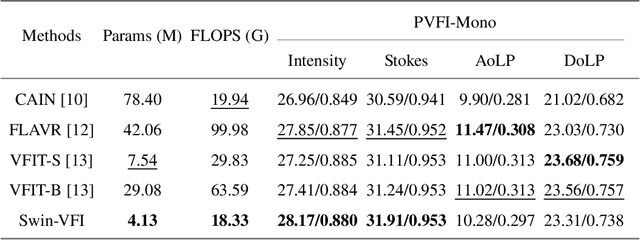
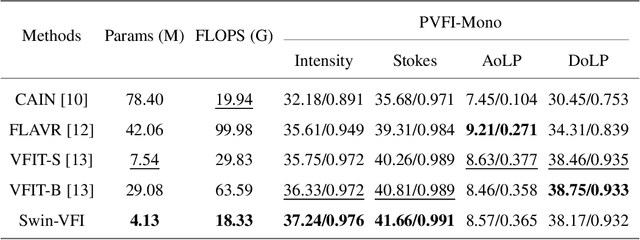
Video Frame Interpolation (VFI) has been extensively explored and demonstrated, yet its application to polarization remains largely unexplored. Due to the selective transmission of light by polarized filters, longer exposure times are typically required to ensure sufficient light intensity, which consequently lower the temporal sample rates. Furthermore, because polarization reflected by objects varies with shooting perspective, focusing solely on estimating pixel displacement is insufficient to accurately reconstruct the intermediate polarization. To tackle these challenges, this study proposes a multi-stage and multi-scale network called Swin-VFI based on the Swin-Transformer and introduces a tailored loss function to facilitate the network's understanding of polarization changes. To ensure the practicality of our proposed method, this study evaluates its interpolated frames in Shape from Polarization (SfP) and Human Shape Reconstruction tasks, comparing them with other state-of-the-art methods such as CAIN, FLAVR, and VFIT. Experimental results demonstrate our approach's superior reconstruction accuracy across all tasks.
Multi-Level Feature Fusion Network for Lightweight Stereo Image Super-Resolution
May 09, 2024Stereo image super-resolution utilizes the cross-view complementary information brought by the disparity effect of left and right perspective images to reconstruct higher-quality images. Cascading feature extraction modules and cross-view feature interaction modules to make use of the information from stereo images is the focus of numerous methods. However, this adds a great deal of network parameters and structural redundancy. To facilitate the application of stereo image super-resolution in downstream tasks, we propose an efficient Multi-Level Feature Fusion Network for Lightweight Stereo Image Super-Resolution (MFFSSR). Specifically, MFFSSR utilizes the Hybrid Attention Feature Extraction Block (HAFEB) to extract multi-level intra-view features. Using the channel separation strategy, HAFEB can efficiently interact with the embedded cross-view interaction module. This structural configuration can efficiently mine features inside the view while improving the efficiency of cross-view information sharing. Hence, reconstruct image details and textures more accurately. Abundant experiments demonstrate the effectiveness of MFFSSR. We achieve superior performance with fewer parameters. The source code is available at https://github.com/KarosLYX/MFFSSR.
Infrared Polarization Imaging-based Non-destructive Thermography Inspection
May 06, 2024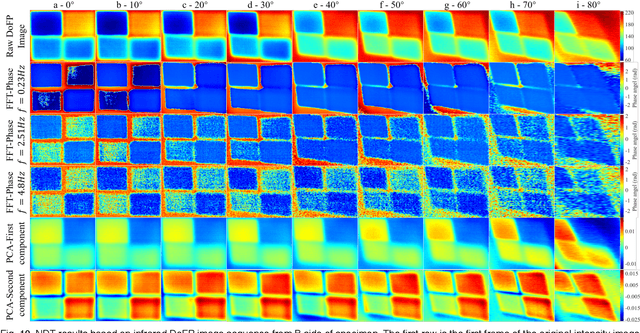
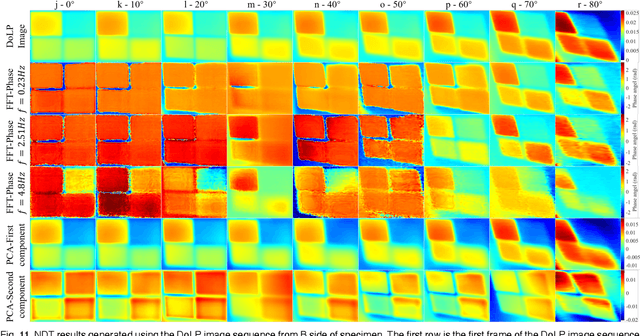
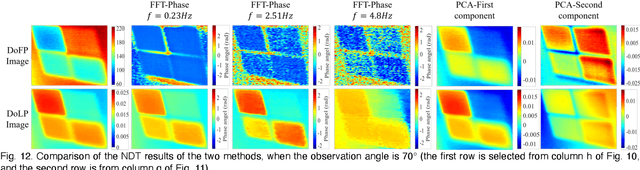
Infrared pulse thermography non-destructive testing (NDT) method is developed based on the difference in the infrared radiation intensity emitted by defective and non-defective areas of an object. However, when the radiation intensity of the defective target is similar to that of the non-defective area of the object, the detection results are poor. To address this issue, this study investigated the polarization characteristics of the infrared radiation of different materials. Simulation results showed that the degree of infrared polarization of the object surface changed regularly with changes in thermal environment radiation. An infrared polarization imaging-based NDT method was proposed and demonstrated using specimens with four different simulated defective areas, which were designed and fabricated using four different materials. The experimental results were consistent with the simulation results, thereby proving the effectiveness of the proposed method. Compared with the infrared-radiation-intensity-based NDT method, the proposed method improved the image detail presentation and detection accuracy.