 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIB-OD: Preserving the Invariant Core for Robust Heterogeneous Graph Adaptation via Decoupled Information Bottleneck and Online Distillation
Apr 13, 2026Graph Neural Network pretraining is pivotal for leveraging unlabeled graph data. However, generalizing across heterogeneous domains remains a major challenge due to severe distribution shifts. Existing methods primarily focus on intra-domain patterns, failing to disentangle task-relevant invariant knowledge from domain-specific redundant noise, leading to negative transfer and catastrophic forgetting. To this end, we propose DIB-OD, a novel framework designed to preserve the invariant core for robust heterogeneous graph adaptation through a Decoupled Information Bottleneck and Online Distillation framework. Our core innovation is the explicit decomposition of representations into orthogonal invariant and redundant subspaces. By utilizing an Information Bottleneck teacher-student distillation mechanism and the Hilbert-Schmidt Independence Criterion, we isolate a stable invariant core that transcends domain boundaries. Furthermore, a self-adaptive semantic regularizer is introduced to protect this core from corruption during target-domain adaptation by dynamically gating label influence based on predictive confidence. Extensive experiments across chemical, biological, and social network domains demonstrate that DIB-OD significantly outperforms state-of-the-art methods, particularly in challenging inter-type domain transfers, showcasing superior generalization and anti-forgetting performance.
Towards Training-Free Scene Text Editing
Mar 25, 2026Scene text editing seeks to modify textual content in natural images while maintaining visual realism and semantic consistency. Existing methods often require task-specific training or paired data, limiting their scalability and adaptability. In this paper, we propose TextFlow, a training-free scene text editing framework that integrates the strengths of Attention Boost (AttnBoost) and Flow Manifold Steering (FMS) to enable flexible, high-fidelity text manipulation without additional training. Specifically, FMS preserves the structural and style consistency by modeling the visual flow of characters and background regions, while AttnBoost enhances the rendering of textual content through attention-based guidance. By jointly leveraging these complementary modules, our approach performs end-to-end text editing through semantic alignment and spatial refinement in a plug-and-play manner. Extensive experiments demonstrate that our framework achieves visual quality and text accuracy comparable to or superior to those of training-based counterparts, generalizing well across diverse scenes and languages. This study advances scene text editing toward a more efficient, generalizable, and training-free paradigm. Code is available at https://github.com/lyb18758/TextFlow
OARS: Process-Aware Online Alignment for Generative Real-World Image Super-Resolution
Mar 13, 2026Aligning generative real-world image super-resolution models with human visual preference is challenging due to the perception--fidelity trade-off and diverse, unknown degradations. Prior approaches rely on offline preference optimization and static metric aggregation, which are often non-interpretable and prone to pseudo-diversity under strong conditioning. We propose OARS, a process-aware online alignment framework built on COMPASS, a MLLM-based reward that evaluates the LR to SR transition by jointly modeling fidelity preservation and perceptual gain with an input-quality-adaptive trade-off. To train COMPASS, we curate COMPASS-20K spanning synthetic and real degradations, and introduce a three-stage perceptual annotation pipeline that yields calibrated, fine-grained training labels. Guided by COMPASS, OARS performs progressive online alignment from cold-start flow matching to full-reference and finally reference-free RL via shallow LoRA optimization for on-policy exploration. Extensive experiments and user studies demonstrate consistent perceptual improvements while maintaining fidelity, achieving state-of-the-art performance on Real-ISR benchmarks.
From Observations to States: Latent Time Series Forecasting
Jan 30, 2026Deep learning has achieved strong performance in Time Series Forecasting (TSF). However, we identify a critical representation paradox, termed Latent Chaos: models with accurate predictions often learn latent representations that are temporally disordered and lack continuity. We attribute this phenomenon to the dominant observation-space forecasting paradigm. Most TSF models minimize point-wise errors on noisy and partially observed data, which encourages shortcut solutions instead of the recovery of underlying system dynamics. To address this issue, we propose Latent Time Series Forecasting (LatentTSF), a novel paradigm that shifts TSF from observation regression to latent state prediction. Specifically, LatentTSF employs an AutoEncoder to project observations at each time step into a higher-dimensional latent state space. This expanded representation aims to capture underlying system variables and impose a smoother temporal structure. Forecasting is then performed entirely in the latent space, allowing the model to focus on learning structured temporal dynamics. Theoretical analysis demonstrates that our proposed latent objectives implicitly maximize mutual information between predicted latent states and ground-truth states and observations. Extensive experiments on widely-used benchmarks confirm that LatentTSF effectively mitigates latent chaos, achieving superior performance. Our code is available in https://github.com/Muyiiiii/LatentTSF.
The Procrustean Bed of Time Series: The Optimization Bias of Point-wise Loss
Dec 21, 2025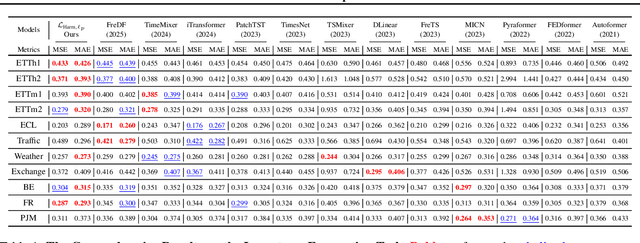
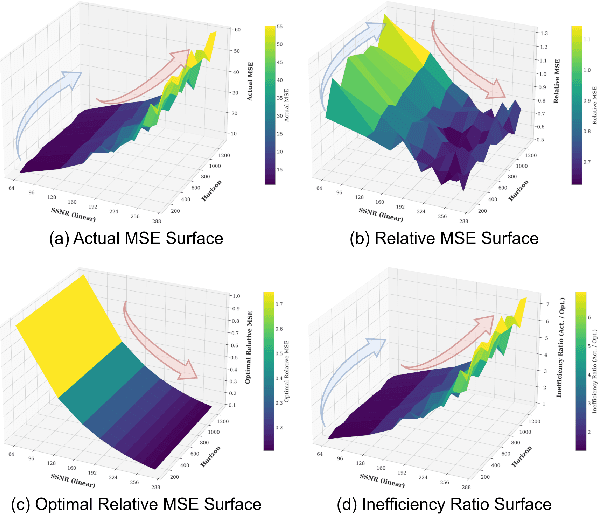
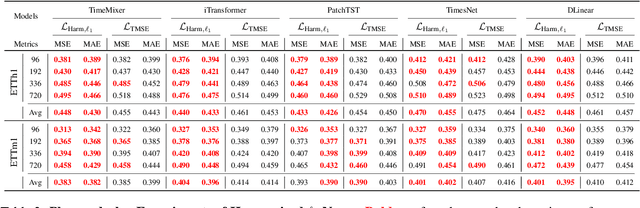
Optimizing time series models via point-wise loss functions (e.g., MSE) relying on a flawed point-wise independent and identically distributed (i.i.d.) assumption that disregards the causal temporal structure, an issue with growing awareness yet lacking formal theoretical grounding. Focusing on the core independence issue under covariance stationarity, this paper aims to provide a first-principles analysis of the Expectation of Optimization Bias (EOB), formalizing it information-theoretically as the discrepancy between the true joint distribution and its flawed i.i.d. counterpart. Our analysis reveals a fundamental paradigm paradox: the more deterministic and structured the time series, the more severe the bias by point-wise loss function. We derive the first closed-form quantification for the non-deterministic EOB across linear and non-linear systems, and prove EOB is an intrinsic data property, governed exclusively by sequence length and our proposed Structural Signal-to-Noise Ratio (SSNR). This theoretical diagnosis motivates our principled debiasing program that eliminates the bias through sequence length reduction and structural orthogonalization. We present a concrete solution that simultaneously achieves both principles via DFT or DWT. Furthermore, a novel harmonized $\ell_p$ norm framework is proposed to rectify gradient pathologies of high-variance series. Extensive experiments validate EOB Theory's generality and the superior performance of debiasing program.
Glocal Information Bottleneck for Time Series Imputation
Oct 06, 2025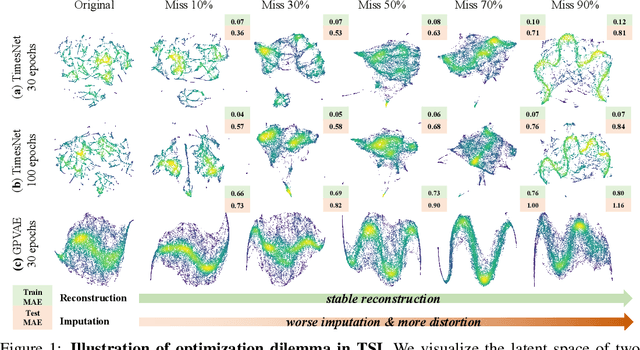



Time Series Imputation (TSI), which aims to recover missing values in temporal data, remains a fundamental challenge due to the complex and often high-rate missingness in real-world scenarios. Existing models typically optimize the point-wise reconstruction loss, focusing on recovering numerical values (local information). However, we observe that under high missing rates, these models still perform well in the training phase yet produce poor imputations and distorted latent representation distributions (global information) in the inference phase. This reveals a critical optimization dilemma: current objectives lack global guidance, leading models to overfit local noise and fail to capture global information of the data. To address this issue, we propose a new training paradigm, Glocal Information Bottleneck (Glocal-IB). Glocal-IB is model-agnostic and extends the standard IB framework by introducing a Global Alignment loss, derived from a tractable mutual information approximation. This loss aligns the latent representations of masked inputs with those of their originally observed counterparts. It helps the model retain global structure and local details while suppressing noise caused by missing values, giving rise to better generalization under high missingness. Extensive experiments on nine datasets confirm that Glocal-IB leads to consistently improved performance and aligned latent representations under missingness. Our code implementation is available in https://github.com/Muyiiiii/NeurIPS-25-Glocal-IB.
KFS: KAN based adaptive Frequency Selection learning architecture for long term time series forecasting
Aug 01, 2025Multi-scale decomposition architectures have emerged as predominant methodologies in time series forecasting. However, real-world time series exhibit noise interference across different scales, while heterogeneous information distribution among frequency components at varying scales leads to suboptimal multi-scale representation. Inspired by Kolmogorov-Arnold Networks (KAN) and Parseval's theorem, we propose a KAN based adaptive Frequency Selection learning architecture (KFS) to address these challenges. This framework tackles prediction challenges stemming from cross-scale noise interference and complex pattern modeling through its FreK module, which performs energy-distribution-based dominant frequency selection in the spectral domain. Simultaneously, KAN enables sophisticated pattern representation while timestamp embedding alignment synchronizes temporal representations across scales. The feature mixing module then fuses scale-specific patterns with aligned temporal features. Extensive experiments across multiple real-world time series datasets demonstrate that KT achieves state-of-the-art performance as a simple yet effective architecture.
From Entanglement to Alignment: Representation Space Decomposition for Unsupervised Time Series Domain Adaptation
Jul 28, 2025Domain shift poses a fundamental challenge in time series analysis, where models trained on source domain often fail dramatically when applied in target domain with different yet similar distributions. While current unsupervised domain adaptation (UDA) methods attempt to align cross-domain feature distributions, they typically treat features as indivisible entities, ignoring their intrinsic compositions that governs domain adaptation. We introduce DARSD, a novel UDA framework with theoretical explainability that explicitly realizes UDA tasks from the perspective of representation space decomposition. Our core insight is that effective domain adaptation requires not just alignment, but principled disentanglement of transferable knowledge from mixed representations. DARSD consists three synergistic components: (I) An adversarial learnable common invariant basis that projects original features into a domain-invariant subspace while preserving semantic content; (II) A prototypical pseudo-labeling mechanism that dynamically separates target features based on confidence, hindering error accumulation; (III) A hybrid contrastive optimization strategy that simultaneously enforces feature clustering and consistency while mitigating emerging distribution gaps. Comprehensive experiments conducted on four benchmark datasets (WISDM, HAR, HHAR, and MFD) demonstrate DARSD's superiority against 12 UDA algorithms, achieving optimal performance in 35 out of 53 cross-domain scenarios.
Cross-Domain Conditional Diffusion Models for Time Series Imputation
Jun 14, 2025Cross-domain time series imputation is an underexplored data-centric research task that presents significant challenges, particularly when the target domain suffers from high missing rates and domain shifts in temporal dynamics. Existing time series imputation approaches primarily focus on the single-domain setting, which cannot effectively adapt to a new domain with domain shifts. Meanwhile, conventional domain adaptation techniques struggle with data incompleteness, as they typically assume the data from both source and target domains are fully observed to enable adaptation. For the problem of cross-domain time series imputation, missing values introduce high uncertainty that hinders distribution alignment, making existing adaptation strategies ineffective. Specifically, our proposed solution tackles this problem from three perspectives: (i) Data: We introduce a frequency-based time series interpolation strategy that integrates shared spectral components from both domains while retaining domain-specific temporal structures, constructing informative priors for imputation. (ii) Model: We design a diffusion-based imputation model that effectively learns domain-shared representations and captures domain-specific temporal dependencies with dedicated denoising networks. (iii) Algorithm: We further propose a cross-domain consistency alignment strategy that selectively regularizes output-level domain discrepancies, enabling effective knowledge transfer while preserving domain-specific characteristics. Extensive experiments on three real-world datasets demonstrate the superiority of our proposed approach. Our code implementation is available here.
ContextRefine-CLIP for EPIC-KITCHENS-100 Multi-Instance Retrieval Challenge 2025
Jun 12, 2025

This report presents ContextRefine-CLIP (CR-CLIP), an efficient model for visual-textual multi-instance retrieval tasks. The approach is based on the dual-encoder AVION, on which we introduce a cross-modal attention flow module to achieve bidirectional dynamic interaction and refinement between visual and textual features to generate more context-aware joint representations. For soft-label relevance matrices provided in tasks such as EPIC-KITCHENS-100, CR-CLIP can work with Symmetric Multi-Similarity Loss to achieve more accurate semantic alignment and optimization using the refined features. Without using ensemble learning, the CR-CLIP model achieves 66.78mAP and 82.08nDCG on the EPIC-KITCHENS-100 public leaderboard, which significantly outperforms the baseline model and fully validates its effectiveness in cross-modal retrieval. The code will be released open-source on https://github.com/delCayr/ContextRefine-Clip