 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTSAQA: Time Series Analysis Question And Answering Benchmark
Jan 30, 2026Time series data are integral to critical applications across domains such as finance, healthcare, transportation, and environmental science. While recent work has begun to explore multi-task time series question answering (QA), current benchmarks remain limited to forecasting and anomaly detection tasks. We introduce TSAQA, a novel unified benchmark designed to broaden task coverage and evaluate diverse temporal analysis capabilities. TSAQA integrates six diverse tasks under a single framework ranging from conventional analysis, including anomaly detection and classification, to advanced analysis, such as characterization, comparison, data transformation, and temporal relationship analysis. Spanning 210k samples across 13 domains, the dataset employs diverse formats, including true-or-false (TF), multiple-choice (MC), and a novel puzzling (PZ), to comprehensively assess time series analysis. Zero-shot evaluation demonstrates that these tasks are challenging for current Large Language Models (LLMs): the best-performing commercial LLM, Gemini-2.5-Flash, achieves an average score of only 65.08. Although instruction tuning boosts open-source performance: the best-performing open-source model, LLaMA-3.1-8B, shows significant room for improvement, highlighting the complexity of temporal analysis for LLMs.
Cross-Domain Conditional Diffusion Models for Time Series Imputation
Jun 14, 2025Cross-domain time series imputation is an underexplored data-centric research task that presents significant challenges, particularly when the target domain suffers from high missing rates and domain shifts in temporal dynamics. Existing time series imputation approaches primarily focus on the single-domain setting, which cannot effectively adapt to a new domain with domain shifts. Meanwhile, conventional domain adaptation techniques struggle with data incompleteness, as they typically assume the data from both source and target domains are fully observed to enable adaptation. For the problem of cross-domain time series imputation, missing values introduce high uncertainty that hinders distribution alignment, making existing adaptation strategies ineffective. Specifically, our proposed solution tackles this problem from three perspectives: (i) Data: We introduce a frequency-based time series interpolation strategy that integrates shared spectral components from both domains while retaining domain-specific temporal structures, constructing informative priors for imputation. (ii) Model: We design a diffusion-based imputation model that effectively learns domain-shared representations and captures domain-specific temporal dependencies with dedicated denoising networks. (iii) Algorithm: We further propose a cross-domain consistency alignment strategy that selectively regularizes output-level domain discrepancies, enabling effective knowledge transfer while preserving domain-specific characteristics. Extensive experiments on three real-world datasets demonstrate the superiority of our proposed approach. Our code implementation is available here.
PLANETALIGN: A Comprehensive Python Library for Benchmarking Network Alignment
May 27, 2025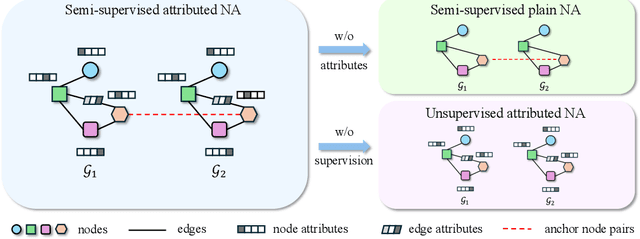
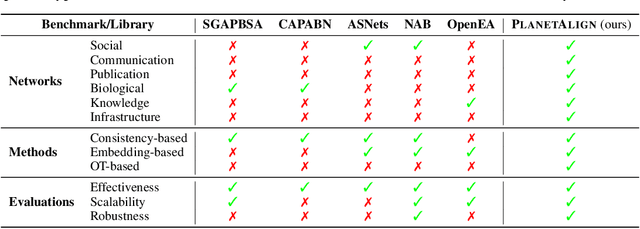
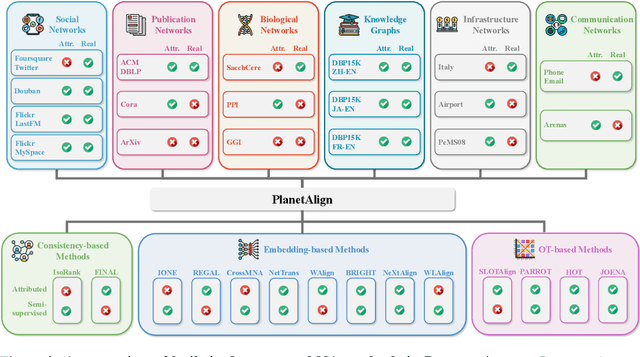
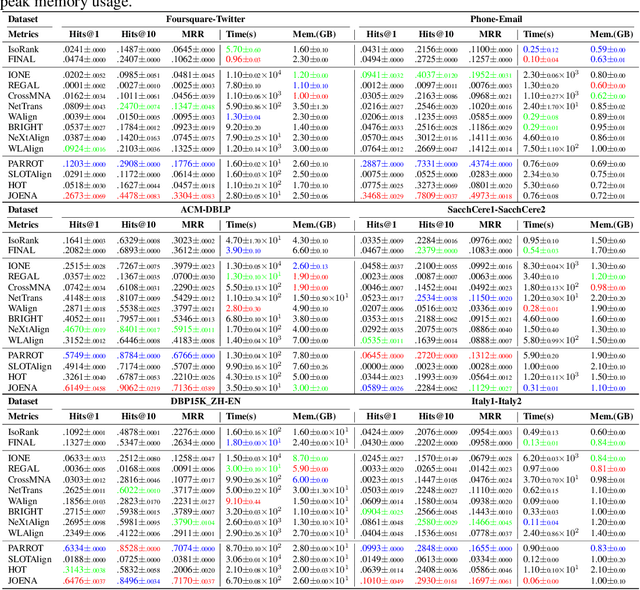
Network alignment (NA) aims to identify node correspondence across different networks and serves as a critical cornerstone behind various downstream multi-network learning tasks. Despite growing research in NA, there lacks a comprehensive library that facilitates the systematic development and benchmarking of NA methods. In this work, we introduce PLANETALIGN, a comprehensive Python library for network alignment that features a rich collection of built-in datasets, methods, and evaluation pipelines with easy-to-use APIs. Specifically, PLANETALIGN integrates 18 datasets and 14 NA methods with extensible APIs for easy use and development of NA methods. Our standardized evaluation pipeline encompasses a wide range of metrics, enabling a systematic assessment of the effectiveness, scalability, and robustness of NA methods. Through extensive comparative studies, we reveal practical insights into the strengths and limitations of existing NA methods. We hope that PLANETALIGN can foster a deeper understanding of the NA problem and facilitate the development and benchmarking of more effective, scalable, and robust methods in the future. The source code of PLANETALIGN is available at https://github.com/yq-leo/PlanetAlign.
PyG-SSL: A Graph Self-Supervised Learning Toolkit
Dec 30, 2024



Graph Self-Supervised Learning (SSL) has emerged as a pivotal area of research in recent years. By engaging in pretext tasks to learn the intricate topological structures and properties of graphs using unlabeled data, these graph SSL models achieve enhanced performance, improved generalization, and heightened robustness. Despite the remarkable achievements of these graph SSL methods, their current implementation poses significant challenges for beginners and practitioners due to the complex nature of graph structures, inconsistent evaluation metrics, and concerns regarding reproducibility hinder further progress in this field. Recognizing the growing interest within the research community, there is an urgent need for a comprehensive, beginner-friendly, and accessible toolkit consisting of the most representative graph SSL algorithms. To address these challenges, we present a Graph SSL toolkit named PyG-SSL, which is built upon PyTorch and is compatible with various deep learning and scientific computing backends. Within the toolkit, we offer a unified framework encompassing dataset loading, hyper-parameter configuration, model training, and comprehensive performance evaluation for diverse downstream tasks. Moreover, we provide beginner-friendly tutorials and the best hyper-parameters of each graph SSL algorithm on different graph datasets, facilitating the reproduction of results. The GitHub repository of the library is https://github.com/iDEA-iSAIL-Lab-UIUC/pyg-ssl.
Can Graph Neural Networks Learn Language with Extremely Weak Text Supervision?
Dec 11, 2024



While great success has been achieved in building vision models with Contrastive Language-Image Pre-training (CLIP) over Internet-scale image-text pairs, building transferable Graph Neural Networks (GNNs) with CLIP pipeline is challenging because of three fundamental issues: the scarcity of labeled data and text supervision, different levels of downstream tasks, and the conceptual gaps between domains. In this work, to address these issues, we leverage multi-modal prompt learning to effectively adapt pre-trained GNN to downstream tasks and data, given only a few semantically labeled samples, each with extremely weak text supervision. Our new paradigm embeds the graphs directly in the same space as the Large Language Models (LLMs) by learning both graph prompts and text prompts simultaneously. To accomplish this, we improve state-of-the-art graph prompt method, and then propose the first graph-language multi-modal prompt learning approach for exploiting the knowledge in pre-trained models. Notably, due to the insufficient supervision for fine-tuning, in our paradigm, the pre-trained GNN and the LLM are kept frozen, so the learnable parameters are much fewer than fine-tuning any pre-trained model. Through extensive experiments on real-world datasets, we demonstrate the superior performance of our paradigm in few-shot, multi-task-level, and cross-domain settings. Moreover, we build the first CLIP-style zero-shot classification prototype that can generalize GNNs to unseen classes with extremely weak text supervision.
Heterogeneous Contrastive Learning for Foundation Models and Beyond
Mar 30, 2024In the era of big data and Artificial Intelligence, an emerging paradigm is to utilize contrastive self-supervised learning to model large-scale heterogeneous data. Many existing foundation models benefit from the generalization capability of contrastive self-supervised learning by learning compact and high-quality representations without relying on any label information. Amidst the explosive advancements in foundation models across multiple domains, including natural language processing and computer vision, a thorough survey on heterogeneous contrastive learning for the foundation model is urgently needed. In response, this survey critically evaluates the current landscape of heterogeneous contrastive learning for foundation models, highlighting the open challenges and future trends of contrastive learning. In particular, we first present how the recent advanced contrastive learning-based methods deal with view heterogeneity and how contrastive learning is applied to train and fine-tune the multi-view foundation models. Then, we move to contrastive learning methods for task heterogeneity, including pretraining tasks and downstream tasks, and show how different tasks are combined with contrastive learning loss for different purposes. Finally, we conclude this survey by discussing the open challenges and shedding light on the future directions of contrastive learning.
Automated Contrastive Learning Strategy Search for Time Series
Mar 19, 2024



In recent years, Contrastive Learning (CL) has become a predominant representation learning paradigm for time series. Most existing methods in the literature focus on manually building specific Contrastive Learning Strategies (CLS) by human heuristics for certain datasets and tasks. However, manually developing CLS usually require excessive prior knowledge about the datasets and tasks, e.g., professional cognition of the medical time series in healthcare, as well as huge human labor and massive experiments to determine the detailed learning configurations. In this paper, we present an Automated Machine Learning (AutoML) practice at Microsoft, which automatically learns to contrastively learn representations for various time series datasets and tasks, namely Automated Contrastive Learning (AutoCL). We first construct a principled universal search space of size over 3x1012, covering data augmentation, embedding transformation, contrastive pair construction and contrastive losses. Further, we introduce an efficient reinforcement learning algorithm, which optimizes CLS from the performance on the validation tasks, to obtain more effective CLS within the space. Experimental results on various real-world tasks and datasets demonstrate that AutoCL could automatically find the suitable CLS for a given dataset and task. From the candidate CLS found by AutoCL on several public datasets/tasks, we compose a transferable Generally Good Strategy (GGS), which has a strong performance for other datasets. We also provide empirical analysis as a guidance for future design of CLS.
CASPER: Causality-Aware Spatiotemporal Graph Neural Networks for Spatiotemporal Time Series Imputation
Mar 18, 2024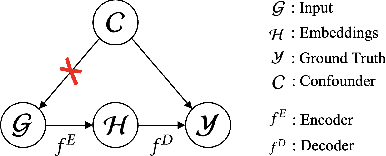
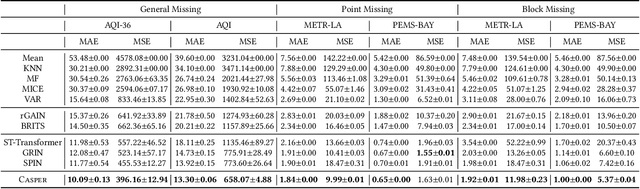
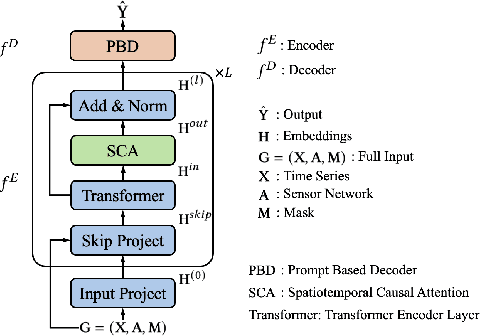
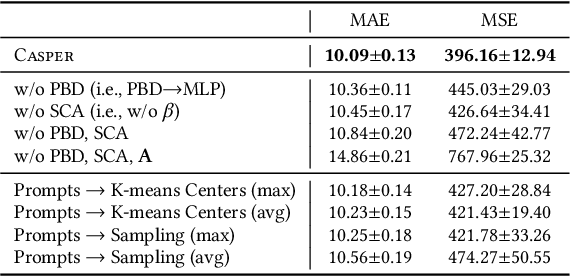
Spatiotemporal time series is the foundation of understanding human activities and their impacts, which is usually collected via monitoring sensors placed at different locations. The collected data usually contains missing values due to various failures, which have significant impact on data analysis. To impute the missing values, a lot of methods have been introduced. When recovering a specific data point, most existing methods tend to take into consideration all the information relevant to that point regardless of whether they have a cause-and-effect relationship. During data collection, it is inevitable that some unknown confounders are included, e.g., background noise in time series and non-causal shortcut edges in the constructed sensor network. These confounders could open backdoor paths between the input and output, in other words, they establish non-causal correlations between the input and output. Over-exploiting these non-causal correlations could result in overfitting and make the model vulnerable to noises. In this paper, we first revisit spatiotemporal time series imputation from a causal perspective, which shows the causal relationships among the input, output, embeddings and confounders. Next, we show how to block the confounders via the frontdoor adjustment. Based on the results of the frontdoor adjustment, we introduce a novel Causality-Aware SPatiotEmpoRal graph neural network (CASPER), which contains a novel Spatiotemporal Causal Attention (SCA) and a Prompt Based Decoder (PBD). PBD could reduce the impact of confounders and SCA could discover the sparse causal relationships among embeddings. Theoretical analysis reveals that SCA discovers causal relationships based on the values of gradients. We evaluate Casper on three real-world datasets, and the experimental results show that Casper outperforms the baselines and effectively discovers causal relationships.
Characterizing Long-Tail Categories on Graphs
May 17, 2023Long-tail data distributions are prevalent in many real-world networks, including financial transaction networks, e-commerce networks, and collaboration networks. Despite the success of recent developments, the existing works mainly focus on debiasing the machine learning models via graph augmentation or objective reweighting. However, there is limited literature that provides a theoretical tool to characterize the behaviors of long-tail categories on graphs and understand the generalization performance in real scenarios. To bridge this gap, we propose the first generalization bound for long-tail classification on graphs by formulating the problem in the fashion of multi-task learning, i.e., each task corresponds to the prediction of one particular category. Our theoretical results show that the generalization performance of long-tail classification is dominated by the range of losses across all tasks and the total number of tasks. Building upon the theoretical findings, we propose a novel generic framework Tail2Learn to improve the performance of long-tail categories on graphs. In particular, we start with a hierarchical task grouping module that allows label-limited classes to benefit from the relevant information shared by other classes; then, we further design a balanced contrastive learning module to balance the gradient contributions of head and tail classes. Finally, extensive experiments on various real-world datasets demonstrate the effectiveness of Tail2Learn in capturing long-tail categories on graphs.
Retrieval Based Time Series Forecasting
Sep 27, 2022
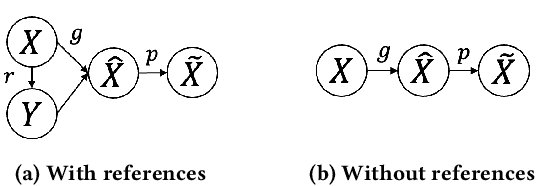
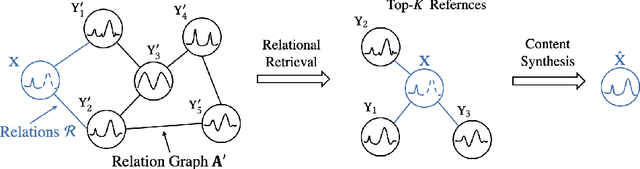
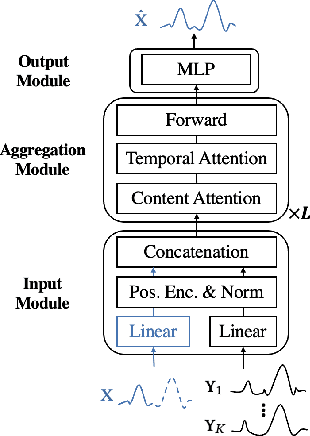
Time series data appears in a variety of applications such as smart transportation and environmental monitoring. One of the fundamental problems for time series analysis is time series forecasting. Despite the success of recent deep time series forecasting methods, they require sufficient observation of historical values to make accurate forecasting. In other words, the ratio of the output length (or forecasting horizon) to the sum of the input and output lengths should be low enough (e.g., 0.3). As the ratio increases (e.g., to 0.8), the uncertainty for the forecasting accuracy increases significantly. In this paper, we show both theoretically and empirically that the uncertainty could be effectively reduced by retrieving relevant time series as references. In the theoretical analysis, we first quantify the uncertainty and show its connections to the Mean Squared Error (MSE). Then we prove that models with references are easier to learn than models without references since the retrieved references could reduce the uncertainty. To empirically demonstrate the effectiveness of the retrieval based time series forecasting models, we introduce a simple yet effective two-stage method, called ReTime consisting of a relational retrieval and a content synthesis. We also show that ReTime can be easily adapted to the spatial-temporal time series and time series imputation settings. Finally, we evaluate ReTime on real-world datasets to demonstrate its effectiveness.